
Amlogic S922X is an upcoming hexa-core processor with four Cortex A73 cores and Cortex-A53 cores mostly designed for devices running Android TV P, but it could also become potentially interesting for development boards and other products like Arm laptops.
There aren’t any products available for purchase, but some results appeared on Geekbench in recently showing Droidlogic galilei board with a 6-core processor from Amlogic which has to be Amlogic S922X processor. There’s also g12b_w400 with a 6-core processor from Amlogic, but that’s A311D.
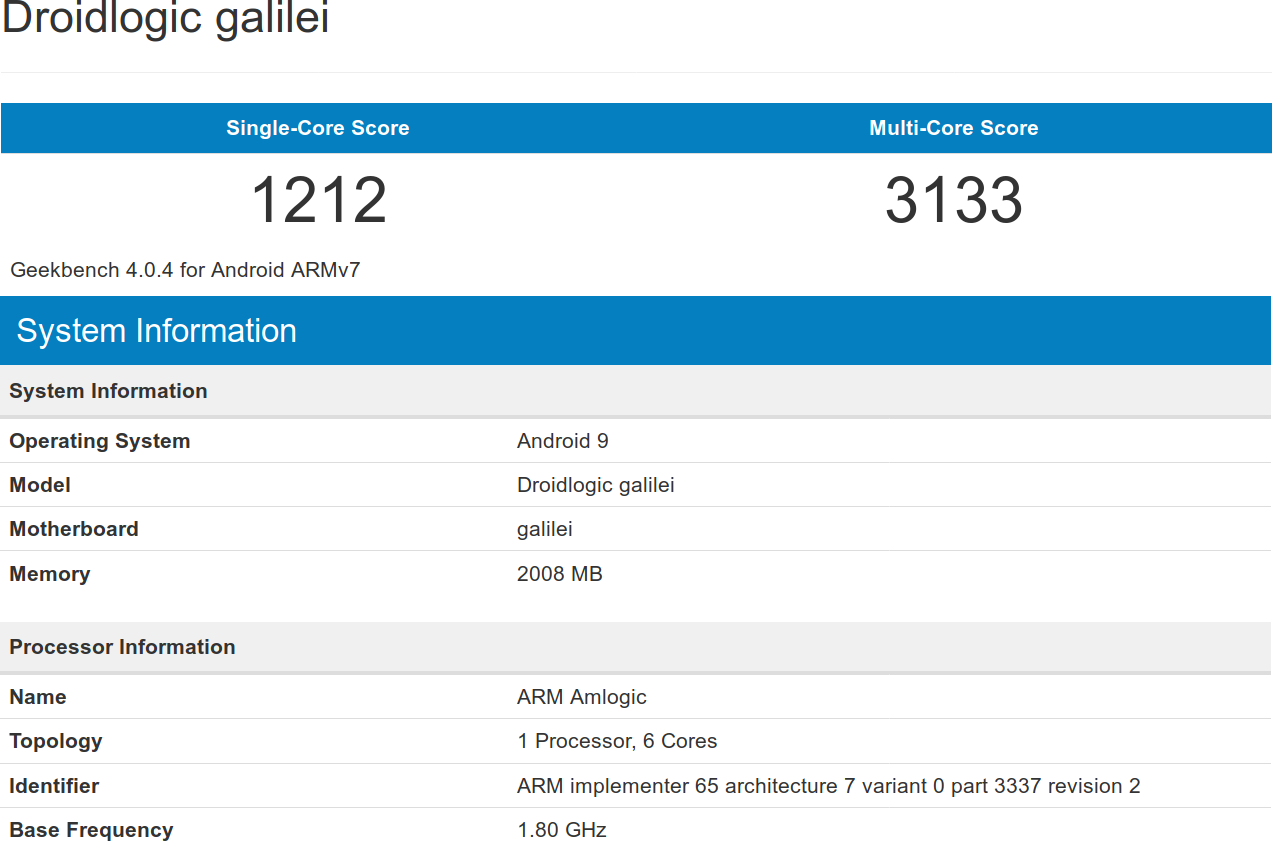
So Amlogic S922X benchmarks report 1212 points for the single-core score, and “only” 3,133 points for the multi-core score. The base frequency in “Droidlogic galilei” board is 1.80 GHz, but 1.90 GHz in g12b_w400 “A311D” platforms. Strangely enough, the single core score is only 9xx in the latter. It’s very likely the maximum frequency drops when all four Cortex A73 cores are under loads, as the multi-core score does not scale.
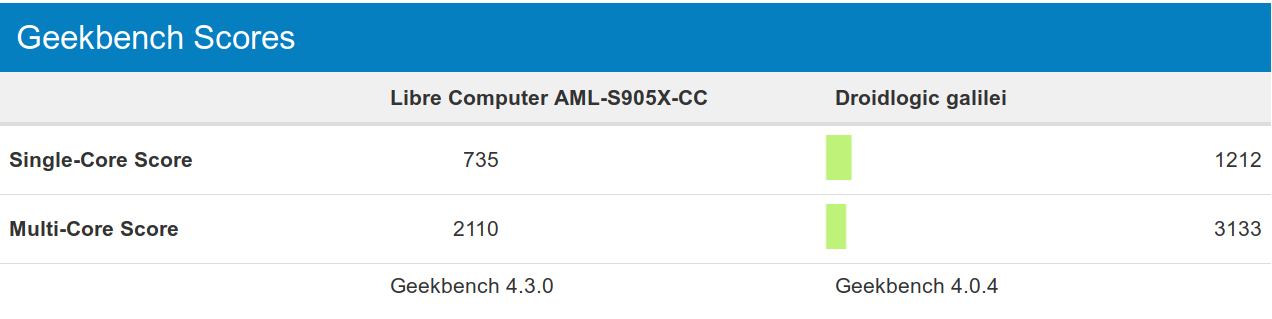
Let’s compare those score to Amlogic S905X (Libre Computer AML-S905X-CC SBC), and there are significant improvements as expected.
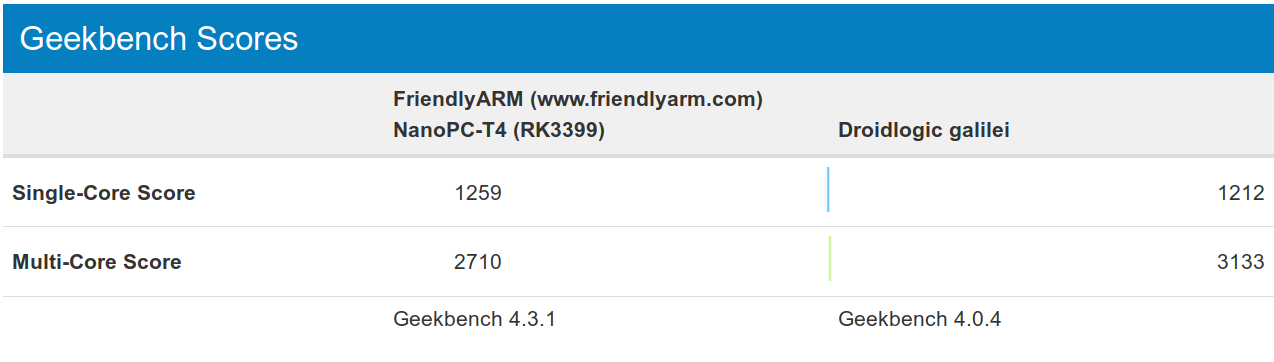
Comparing Amlogic S922X to Rockchip RK3399 is somewhat disappointing. The single-core score is the same, and that one should be expected since Cortex-A72 and Cortex-A73 are supposed to have the same performance, with the latter having better thermals, but the multi-core score is only slightly better despite S922X having four “fast” cores against two “fast” cores for RK3399.
Having said that I’d expect the scores for Amlogic S922X to somewhat improve since:
- 32-bit Android was used with S922X against 64-bit Android for RK3399
- Hardware accelerated AES for S922X is not ready yet, or there are some problems with the implementation as shown in the screenshot below.
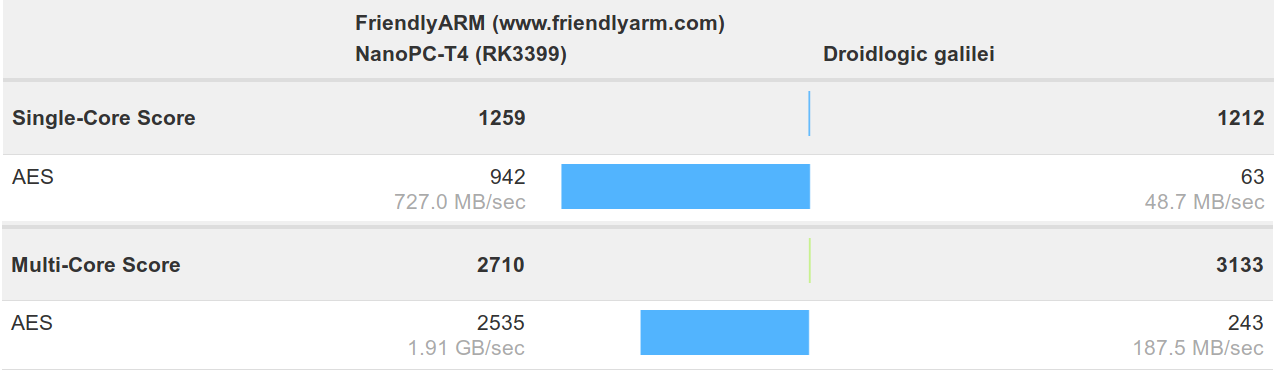
Nevertheless, the early results look good so far, and Amlogic S922X should be a promising platform competing against Rockchip RK3399 processor, and offering a significant upgrade compared to previous Amlogic processors. The CPU is only one part of modern SoC, so we’ll have to see how to GPU, and high-speed interfaces perform in the new SoC.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


Latest Sony TVs are that far too:
https://browser.geekbench.com/v4/cpu/11696101
Good catch by the parties involved!
BTW, in contrast to the CA57 -> CA72 transition, where CA72 was just better overall (power, performance, area), CA73 is a significantly remote uarch from CA72, and things are not quite unilateral — while CA73 is better at integer code — better performance for the same power, or same performance at lower power, in the fp domain things are not so clear cut, due to the fact CA73 sacrifices fp ports/ALUs, and ergo performance.
That said, 4x CA73 *should* be a clear performance win over 2x CA72 : )
ps: The most interesting question for me here is what clocks Amlogic managed to sustain in this design.
> 4x CA73 *should* be a clear performance win over 2x CA72:)
Exactly.
> 32-bit Android was used with S922X against 64-bit Android for RK3399
So what? Geekbench uses only primitive low level routines so not able to measure ‘OS performance’ anyway. Amlogic S912 with Aarch64 Geekbench version (64-bit) vs. ARMv7 (32-bit). Doesn’t matter.
Once they enable ARMv8 Crypto Extensions the scores will somewhat improve but they’re far away from being impressive when thinking about 4 ‘fast’ A73 cores in this design. When all cores are busy they must be downclocked to really low values which is something those people believing into new Amlogic SoCs being made in an efficient 12nm process might want to think about (those believing into ‘throttling effects’ –> it’s easy to educate yourself on Youtube how long such Geekbench tests run)
OK. I did not know about that. I was thinking about this: https://www.cnx-software.com/2016/03/01/64-bit-arm-aarch64-instructions-boost-performance-by-15-to-30-compared-to-32-bit-arm-aarch32-instructions/ when I wrote that specific sentence.
There are two vectors of reasoning here — one is the effect of ISA on OS/kernel performance, which geekbench does not depend _much_ on (it surely does to some small degree), and one is ISA effect on user code. Unless in some pointer-chasing scenario (not uncommon for compilers, BTW), aarch64 should and does perform equally-or-better for gen-purpose user code, and even more so for fp code — ASIMDv2 is truly a better ASIMD/NEON — a basic matrix multiplier can show that. Now, how much does geekbench bother with different versions for different ARM ISAs — I don’t know, but for x86 where I’ve bothered to check, geekbench does branch to different routines for SSEx and AVX for fp code, at the very least. So I would not be surprised if armv7 vs armv8 differentiation existed at least in some of geebkench non-crypto routines. I think that for a proper clean test that should be taken into account.
Wait till you see the Ryzen 5 2400G based Apple iMac easily destroy the Intel Core i9-9900K!
https://browser.geekbench.com/v4/cpu/compare/11733020?baseline=10805492
This changes everything!
With such a difference in frequency, that Ryzen thing really sucks. xD Look at the report frequency of it.
8.7 Ghz ? Yeah sure!
> how much does geekbench bother with different versions for different ARM ISAs — I don’t know
And nobody else knows. Geekbench source code is not available and the ‘information’ provided is rather crappy. And looking at the Geekbench scores for this S922X board right now is close to moronic anyway.
What Geekbench calls ‘Identifier’ is them parsing
/proc/cpuinfo. ‘Architecture 7’ means the SoC has been brought up in ARMv7/AArch32 state (otherwise it would be 8) and is then also running a 32-bit kernel (usually even 32-bit Android userlands are combined with a 64-bit kernel).What Geekbench calls ‘Base Frequency’ is neither a base nor a frequency but just some random number they pulled out of the device-tree (obviously the number defined as maximum clockspeed for cpu0 — we all know that these numbers with some vendors have no meaning at all and we would need to know what cpu0 is –> is it a little CPU or a big one? Usually cpu0 is little but on Amlogic’s little.LITTLE S912 thingy for example they defined the A53 cluster that is allowed to clock up to 1.4 GHz as cpu0-cpu3. That’s why we see 1.5 GHz as ‘Base Frequency’ with with S912.
It would be so easy for Geekbench to provide real information instead of bogus data (simply walking through all CPUs, testing them quickly for their real clockspeeds and then providing this as information) but it seems the target audience doesn’t care anyway.
So we need to wait for S922X being brought up in Aarch64 state to make some use of Geekbench numbers (the single core AES scores are somewhat interesting since not affected by memory performance at all and therefore usable as clockspeed indicator — but in AArch32 state without ARMv8 Crypto Extensions it’s useless).
Disclaimer: I’m pretty sure I mixed up stuff when mentioning ARMv7 vs. ARMv8 vs. Aarch32 vs. Aarch64 🙂
After reading your cooling review of the NanoPi M4, which looks like one of the better ones on the market, I wonder if thermal throttling would not even be a bigger problem for the 4 large cores here. I wish there could be more effort in designing a proper cooling solution. I have seen that there is, for example, an active cooler for the NanoPC T4, which has a fairly small passive cooler, so maybe that improves things.
Lattepanda designed an active cooler for their 6W TDP Core m3 and Celeron M4100, and I would expect this S922 has at least a similar TDP.
I’m intrigued to look through Taobao what kind of cooling solutions there are. I already found one with a massive offer on passive coolers that could be topped with an active cooler. Mostly, mounting it properly is challenging, though, so a properly designed cooler that comes with the board is still preferred.
> So I would not be surprised if armv7 vs armv8 differentiation existed at least in some of geebkench non-crypto routines. I think that for a proper clean test that should be taken into account.
Doh, it struck me only now that that part of my post was nonsensical the way I wrote it.
As aarch32 vs aarch64 states are per-process, *not* per-routine (which is the case of SSE vs AVX in amd64 land and ARM vs Thumb in arm land), an aarch64-compiled geekbench would mandatorily use aarch64 across *all* its code. Geekbench could still ignore ASIMDv2 and the crypto extensions where those would be beneficent, but other than that it would take effectively full advantage of the armv8 ISA by just passing the correct flags to the compiler (namely -march=armv8-a).
Previously I overlooked ‘Architecture 7’ in Geekbench output. So Geekbench scores (and also real-world performance) will improve once Amlogic manages to bring the CPU cores up in Aarch64 state.
the only fact, aarch64 uses much more general purpose registers, should improve code speed considerably, compared with aarch32. and this is something that anything can take advantage of, even a lame synthetic test.
It’s not that black and white. There are some tradeoffs. For most of the stuff I find armv8 faster, except for gcc and a few other programs. For me gcc is 20% slower in armv8 mode than in armv7’s thumb2 mode on the same machine. Larger pointers implying a higher stress on the CPU caches most likely are one reason. Other explanations may involve some lost features like conditional execution of many instructions, which have to be replaced by conditional jumps, hence now rely on the branch predictor’s accuracy.
in the link that @Stane1983 mentionned, there is an intereting PDF document about S922X (the one named OTT-android_p_release_notes_v20181208_AOSP.pdf)
it says that the GPU is ARM Mali-G52 MP6 (if i remember correctly, A311D features a MP4 one)
also, it waiting for the next openlinux release from amlogic, it should contains DTS info about s922x
i remember that on A311D, the dts showed that A53 is clocked up to 1.9GHz and A73 up to 1.7GHz only…
and yes, i know that these info have to be double checked when hardware is available
Can someone confirm that it has 4 CA73 and 2 CA53 cores? I mean, with 2 CA73 and 4 CA53 cores, performance numbers would match.
Poster from Amlogic booth at CES: https://pasteboard.co/HZ9zWWw.jpg
i’m surprised nobody commented about this S922D
isn’t it an exclusive info ?
The S922X sibling A311D shows similar ‘Geekbench behavior’: https://browser.geekbench.com/v4/cpu/search?utf8=✓&q=g12b_w400
Latest publicly available Amlogic Linux code drop contains information about the CPU clusters:
The stuff displayed by Amlogic at various booths is somewhat questionable, e.g. they showed ‘Mali G52 MP4’ being part of S922X at IBC 2018. At CES it has grown to MP6 already…
Thanks. Next question would be if Linux Kernel can handle this unusual core configuration or whether there are 2 fast cores unsused.
Linux kernel handles that just fine via HMP (heterogeneous multi processing) scheduling.
Well, it’s the scheduler’s job in such big.LITTLE situations to know about the CPU core’s capabilities and there’s even ‘Energy Aware Scheduling (EAS)’ (do a web search for it to get an idea about the concepts and status).
Reality sometimes looks differently. I tried today to get Geekbench numbers for other A73 CPU cores. I found some for Helio X30 but failed to lookup Kirin 960/970 numbers directly. But when searching for ‘hikey’ I found this: https://browser.geekbench.com/v4/cpu/search?utf8=✓&q=hikey — that’s most probably either Kirin 960 or Kirin 970 but the kernel these devices are running lacks understanding of big.LITTLE since the single-threaded Geekbench tasks obviously were all executed on a little core (AES score of 375 translates to A53 at 1.2GHz with ARMv8 Crypto Extensions active).
Similar picture when looking at Amlogic S912. This little.LITTLE design features two identical A53 clusters but one of them is limited to 1.0 GHz, the other to 1.4GHz (faking 1.5 GHz as usual with Amlogic). Khadas Vim2 users reported CPU intensive tasks ending up on those cores that are artificially limited to 1.0 GHz so in the end this octa-core S912 thingy is slower than a quad-core S905 or S905X since still most tasks are single-threaded and 1.5 GHz (S905) or 1.4 GHz (S905X) are faster than 1 GHz when the scheduler on an S912 pins threads to the wrong cores.
Addendum: link to S912 scheduler madness: https://forum.khadas.com/t/s912-limited-to-1200-mhz-with-multithreaded-loads/2311/71?u=tkaiser (maybe due to Amlogic defining the artifially slower A53 cluster as cpu4-cpu7 while usually the little cores are cluster0?).
This is interesting from a S922X perspective since the weird scheduler behavior on S912 occurred with Amlogic’s 4.9 kernel and AFAIK same kernel will be used for S922X/A311D as well.
Especially for kernels 4.x it’s easy to add HMP scheduler – you candy find patches for 4.9, 4.14, 4.18, 5.0 on my GitHub – and there’s a kernel config option for fast cpu mask. This is really a non issue for anyone remotely competent with access to kernel sources.
Really terrible support there from Khadas vim ppl. It’s a 15 minute fix.
“basic” hikey should be the octa-core A53 board based on kirin 620 https://www.96boards.org/product/hikey/
you can find hikey960 geekbench numbers here https://browser.geekbench.com/v4/cpu/search?dir=desc&q=hikey960
i never found any geekbench numbers about kirin 970 unfortunately
but, imho, comparing these geekbench numbers is a bit *early* since we know almost nothing about hardware platforms, software (benchmark tool, OS, kernel) and the SoC power consumption & sustained frequencies
Not interesting to me. We’ve had octa-core A53 for a while with NanoPI Fire3, and a bit faster (1.4 GHz stock, 1.6 max). And for half the price 🙂
> you can find hikey960 geekbench numbers
Ah, yes this looks like an A73 cluster at reasonable clockspeeds. And while I agree that it’s too early to look at S922X benchmark numbers it should be obvious that at least with current firmware blobs the cores in S922X are heavily downclocked (which should be a surprise for those people believing into Amlogic’s funny ’12nm’ claim)
> it should be obvious that at least with current firmware blobs the cores in S922X are heavily downclocked
Snapdragon 636 equiped with slightly “tuned”(via ARM BoC license) Cortex-A73 cores @1.8GHz. And its GB4 single-core scores are ~=1330-1340 (vs 1212 in tested device).
So, cores in benchmarked device are not “heavily downclocked”.
Multi-core scores – heavily depends on SoC cooling.
> cores in benchmarked device are not “heavily downclocked”
Have you seen how Kirin960 performs: https://browser.geekbench.com/v4/cpu/11771160
Kirin960 according to specs has just two more A53 cores compared to S922X but multi-core score is almost twice as high (if we keep in mind that S922X scores will improve when running with a 64-bit kernel and enabled ARMv8 Crypto Extensions that hopefully have been licensed by Amlogic).
Kirin960 is said to be manufactured in TSMC’s 16FFC FinFET process and the A73 cores are clocked at 2362 MHz.
> Multi-core scores – heavily depends on SoC cooling.
With Geekbench 4? I don’t think so. It’s very easy to get what Geekbench is doing by simply watching a few seconds on Youtube. Every benchmark test runs the single-thread test and directly afterwards the multi-core test (each lasting less than a second) and then the next test starts. So the first tests should not be affected by throttling at all (only if the device was already totally overheated when the benchmark started).
There is a link to Khadas forum above where you can examine how Amlogic deals with this on their little.LITTLE S912 design. The firmware simply downclocks the cores when all are busy while Linux’ cpufreq scaling frameworks gets bogus clockspeeds reported.
> Have you seen how Kirin960 performs
Sure.
> Kirin960 is said to be manufactured in TSMC’s 16FFC FinFET process and the A73 cores are clocked at 2362 MHz.
vs 1800Mhz or so.
> With Geekbench 4?
Yes. Multicore scores of GeekBench can be considered broken at all, because depends on too many factors. Bad reapitability of scores.
> The firmware simply downclocks the cores when all are busy while Linux’ cpufreq scaling frameworks gets bogus clockspeeds reported.
That’s not news to me.
It seems this is not the case.
> vs 1800Mhz or so.
I’d be really surprised if S922X couldn’t sustain one CA73 core at ~2GHz.
> I’d be really surprised if S922X couldn’t sustain one CA73 core at ~2GHz.
You can download some GB for a tar file on Amlogic’s openlinux site which contains
OpenLinux_20180907/kernel/aml-4.9/arch/arm64/boot/dts/amlogic/g12b_a311d_w400.dtsdefining the fake numbers.cpu_opp_table1defines the DVFS OPP for the A73 cluster and this ends at 1.9 GHz at slightly below 0.9V. So if even the fake numbers do not exceed 1.9 GHz how should real clockspeeds be above or at 2.0 GHz?I would be surprised if S922X A73 real clockspeeds with single-threaded loads exceed 1.8 GHz and with all A73 cores being busy does not drop below 1.3 GHz 🙂
Well, if Amlogic did 1.8GHz with one CA73 whereas Rockchip and Mediatek do 2.0 and 2.1 with (two) CA72 @ 28nm (RK3399 and MT8173, respectively), then Amlogic really screwed up something.
A73 is a 11 stage design and A72 is a 15 stage design. A73 will clock slower than A72 on the same process. Performance will be higher at the same clock for A73 because of the fewer stages and losses from a miss. You also have to consider a design’s power budget. G12B is targeted to have a much lower power profile than RK3399 at nearly the same performance. RK3399 can consume upwards of 15W while S922 is targeted at less than 10W.
Number of stages mostly only matter after a branch (1 instruction out of 5 on average). However workloads that have been heavily optimized to be branchless already fill a longer pipeline and will run slower on a CPU with a lower frequency. The A73 decodes only 2 instructions per cycle vs 3 for the A72, its only chance to win is its double load/store unit which should improve memory bound workloads, but otherwise it has more chances of being 33% slower at the same frequency. Also another hint is that the vendor speaks about power savings everywhere and always remains vague about performance. This is unusual enough to be interpreted as “well, we warned you”.
> A73 is a 11 stage design and A72 is a 15 stage design. A73 will clock slower than A72 on the same process.
But we’re working from assumption here that it’s not the same process, no?
BTW, RK3399 is passively-cooled in 10″ chromebooks and chrometabs just fine — are you sure of that 15W TDP?
> we’re working from assumption here that it’s not the same process, no?
Why would we think about different processes? Since some funny Amlogic marketing dude prints ‘Technology: 12nm’ on posters (at a time ‘minor players’ like Intel still struggle to move their production from 14nm to 10nm)?
https://www.anandtech.com/show/11088/hisilicon-kirin-960-performance-and-power/4 is an interesting read especially for those people blindly believing into marketing BS.
> https://www.anandtech.com/show/11088/hisilicon-kirin-960-performance-and-power/4 is an interesting read especially for those people blindly believing into marketing BS.
I had forgotten about that chart. So, CA72 @ 2.3GHz @ 16FF+ takes approx 800-900 mW per core, whereas CA73 @ 2.36GHz @ 16FFC takes approx 1200mW per core.. TSMC 16FFC does seem like a bad fit for CA73.
I’m still not convinced Amlogic went for a 28nm 4x CA73 design, though, even if they sent their clocks down to the upper-mid 1.5GHz range, as that’s still be a higher TDP than the competition’s 2x CA72 @2GHz. What would they attain by a product that gets murdered by 2-year-old competitors in single-threaded performance?
> What would they attain by a product that gets murdered by 2-year-old competitors in single-threaded performance?
‘Murdered’?
Those A72 based SoCs you mentioned are for mobile use cases, they need to be energy efficient and have to provide good single-threaded performance since otherwise Chromebook experience sucks.
Amlogic does TV box SoCs. Target audience: people sitting on a sofa and watching TV. Consumption is irrelevant, single-threaded performance also irrelevant, they need good HW accelerated media decoding capabilities due to most TV boxes having shitty thermal designs and everything else is marketing department’s job.
Amlogic needs to define some nice looking DT entries so ‘tools’ like Geekbench and CPU-Z show nice high clockspeeds and if your marketing department also spreads BS like ‘Technology: 12nm’ then you already won since there’s always some ‘journalist’ or blogger or blog commenter pointing out how superior your new SoCs are.
Everything I stated was assuming same process. A72 has less to do per stage and scale to higher frequencies. It will also perform better assuming no branch mispredictions for non-NEON code since it has more execution ports.
I did extensive testing when designing Renegade Elite. RK3399+LPDDR4 will exceed 15W with full CPU and GPU load. Those devices you mentioned will thermal throttle and power throttle to maintain stability. 28nm A72 is nearly double the power of 14nm A72. RK3399 also has a 64-bit wide DDR bus compared to the 32-bit wide DDR bus of the S922. RK3399 also has significantly more logic for peripherals than S922, which is relatively stripped down chip. A complete S922 design will end up at half the power of a RK3399 design at the expense of being much less flexible in terms of IO.
> Those devices you mentioned will thermal throttle and power throttle to maintain stability.
I have passively-cooled chromebooks hosting both mentioned SoCs (i.e. MT8173 and RK3399), so I can toss in my observations. For the purpose I’ve run a dense matrix multiplication (armv7 ASIMDv1, due to 32-bit arm userspace in chromeos) in a tight loop as two concurrent multi-threaded processes, one pinned to the little and one to the big cluster, while monitoring the resulting performance from both processes.
First off, you’re right about the MT8173C — in both enclosures I have here this SoC gets to throttle *both* its big and little cores within a minute from test initiation.
Re the RK3399 (read: its OP1 varian), though, here are the results:
little cluster: https://pastebin.com/BVkH0mM0
big cluster: https://pastebin.com/z9znm4um
(one run per line, showing times of all participating cores, followed by the averaged, in parentheses)
Notice how either clusters on the RK3399 (OP1) don’t throttle. Their clocks stay as:
I can also confirm the reported times per run correspond to the unthrottled performance of CA72 and CA53.
You need use cpuburn-a7. Each 1.5GHz little core is about 1W. Each 2GHz big core is over 2W. If you are just using the CPU, the maximum load is only 9W. If you fire up the GPU and display pipelines, you will hit 15W+.
Ok, why whould I need cpuburn-a7 when the ASIMD dense matmul test is doing 2flops/clock on A53 and 4.5flops/clock on A72? What possibly could a spinloop of two shifts, one scalar subtraction and two 32-bit loads per iteration do (if you’re referring to this https://github.com/ssvb/cpuburn-arm/blob/master/cpuburn-a7.S)? Yes, I could load the flops even higher on both cores by using larger matrices, but do I need to if cpuburn sets the bar so low?
> A73 will clock slower than A72 on the same process
The A72 cores in Rockchip’s OP1 SoC (selected RK3399 that can be operated at lower DVFS OPP) are clocked at up to 2.0 GHz. The A73 in S922X will clock at 1.7 GHz max. Makes sense for 28nm 🙂
> RK3399 can consume upwards of 15W while S922 is targeted at less than 10W.
Where did you get your 15W from? https://olimex.wordpress.com/2019/01/25/rockchip-is-releasing-low-power-soc-with-npu-targeting-deep-learning/#comment-36172
Fire up the GPU and CPU together.
> Fire up the GPU and CPU together.
Huh? Why? I’m neither interested in ‘GPU’ nor Android boxes. As such I don’t care about this S922X thingy anyway unless the GPU could be used for GPGPU stuff. It’s just amusing to join such discussions based on even intelligent people believing every BS marketing departments tell 🙂
So newest thing I learned today is that this S922X is designed for a maximum consumption of 10W when both CPU and GPU are busy. This would require a very efficient process like… e.g. ’12nm’ when CPU and GPU cores run at today’s clockspeeds, right?
Thanks to Anandtech and others we know about the consumption of a busy A73 cluster made in TSMC’s 16FFC FinFET process. Given Amlogic did S922X in a more advanced and way more expensive ’12nm’ process (which would assure none of their customers doing cheap TV boxes will ever buy their SoC) we could assume that full CPU load consumption is less than Kirin960 numbers (made in an ‘ancient’ 16nm process — due to those HiSilicon losers and their lame SoCs for flagship phones. What a lousy product category compared to super cheap TV boxes! We just need to look at the markets to know where the innovations happen!).
Full CPU load with Amlogic’s ‘super efficient’ 12nm process will for sure result in less than 5W if we base our assumptions on situation with Kirin960, right? Wait! I forgot that Kirin960 consumes slightly more than 5W at almost 2.4 GHz clockspeeds. So given the ‘great’ official cpufreq settings for S922X (1.7 GHz) we can even assume that Amlogic’s A73 cores in their superior 12nm process will consume less than 4W (3W?) under full load at ‘impressive’ 1.7 GHz (BTW: I still highly doubt these 1.7 GHz will be the maximum once 2, 3 or 4 A73 cores are busy at the same time. Wouldn’t be surprised if it’s 1.2GHz or less). With 10W max in mind there should be a lot of headroom for GPU consumption then, right (’12nm’ must be soooo efficient)?
Seriously: why do we talk about new Amlogic SoCs made in a freaking expensive process when their business depends on selling cheap media player SoCs for a ‘race to the bottom’ market? I would believe their new SoCs still shine wrt HW accelerated media capabilities since that’s what Amlogic is really good at (focusing on Android and Fuchsia now). But since the customers of their customers are totally clueless TV box consumers not able to understand the importance of ‘VPU’ and ‘GPU’ their marketing department is forced to spit out some funny numbers (e.g. 2 being 1.5 in reality or 12 being 28 in reality and so on).
We and our discussion are of no relevance for Amlogic’s business model. It’s about a mass market (Android and Fuchsia soon) and customers focusing on numbers they don’t understand. Actual CPU performance close to irrelevant, SoC as cheap as possible while providing sufficient GPU/VPU features key to success.
I think you’ve quite made your point here, and while I agree with much of what you said, it doesn’t seem to resonance much, perhaps because of the way you communicate it 😉
To me it doesn’t really matter, if let’s say Hardkernel chooses this SoC for their next Odroid, I trust their choice and will look at the real results then. To me, it doesn’t really matter which process they make it in, but rather how the chip performs.
Does anyone know btw which foundry Amlogic is using? Because I think it would be hard to go to TSMC and get a “12nm” process that’s closer to a 28nm of others. Is it possible that they work with a foundry that is equal to them in their marketing department?
> Seriously: why do we talk about new Amlogic SoCs made in a freaking expensive process when their business depends on selling cheap media player SoCs for a ‘race to the bottom’ market?
I haven’t mentioned anything about 12nm, though ; ) I’ve been entertaining the thought S922x is on a better than 28nm node, that’s all.
>So newest thing I learned today is that this S922X is designed for a maximum consumption of 10W when both CPU and GPU are busy.
It can scale to higher than 1.7GHz with higher voltages but power consumption can double very quickly. Keep in mind this chip is designed for a lot of applications that are passively cooled so they need to keep the frequency and voltage low in order to address the market.
>Full CPU load with Amlogic’s ‘super efficient’ 12nm process will for sure result in less than 5W if we base our assumptions on situation with Kirin960, right?
Yes, expect 1W/core max. Equivalent to A53 @ 1.5GHz on 28nm.
12nm is much cheaper now because phone sales are dwindling and they were the ones driving the demand for the latest process. With every big SoC manufacture moving to 7nm for their 2019 season, 12nm is quickly coming down in price. Higher mask costs is covered by lower per unit cost for 12nm.
@tkaiser
you made a big mistake here
the dts file shows that the A73 runs up to 1.704 GHz @ 0.891V
once again, those numbers need to be double checked when hardware is available
comparatively, the hikey960 dts shows that its A73 runs up to 2.36 GHz @ 1.1V
power consumption does matter (see Da Xue’s comment, he explained this way better than me)
> the dts file shows that the A73 runs up to 1.704 GHz @ 0.891V
Ah, then I remembered wrong, it’s even worse and the fake numbers stop already at 1.7 GHz (I deleted the openlinux stuff already).
BTW: I doubt they ‘show’ anything since defining clockspeeds and corresponding voltages is a requirement of the cpufreq scaling framework while traditionally with Amlogic the thermal, DVFS and cpufreq stuff happens solely on the Cortex M cores and out of control of the kernel.
> those numbers need to be double checked when hardware is available
Sure. But what do you expect? Higher real clockspeeds than those defined in DT? Or vice versa (as usual)?
How are those 1.6ghz allwinner H3 SoC doing, the ones you was payed by Stephen to provide Orange Pi support for !
seriously, wtf, why my comments haven’t gotten into the discussion? they were off topic? or is it a “closed” club for a few posters. kinda attitude that stinks.
Because I sleep sometimes.
oh, sorry, my bad, I hope you had a good sleep. 😀 I just saw comments published that were posted after my ones and thought it was just my comments were rejected. but honestly, you could not publishing this above one.
It sucks openlinux is nowhere near usable for Linux. Nearly double the engineering effort because Android is a fork still. Otherwise that SoC’s performance would actually be interesting for something other than an Android box.
At least Amlogic try, Libre Le Potato is at LTS Linux 4.19
Amlogic has nearly nothing to do with Le Potato being on 4.19. Why is tkaiser getting neg’ed? He is correct.
Who do you think payed baylibre to start updating Linux on Amlogic. A move that now result with baylibre and the libre computers collection of companies working of Linux main streaming on SoC from several companies. That first payment seeded the baylibre start on the work.
Amlogic is focused on their next generation. You are talking to the guy sponsoring much of the work for GXL.
Non of which alters the fact that Amlogic paid baylibre to first start main lining, Amlogic Linux drivers.
GXBB and GXL are where they are upstream because of the community. Not because of Amlogic. Your logical equivalence is like thanking Allwinner for sunxi. You are giving credit where credit less than deserved. Amlogic got a very few subsystems they needed upstream but Martin, Neil, Jerome, Maxime, and others spent a lot of time outside of those subsystems.
You running Amlogic down by completely intentionally ignoring that before they paid baylibre, baylibre were not working on the drivers Amlogic paid them to work on. While allwinner just dumped their SoC with blobs on the hardware scene. That’s why you desperately try to broaden your premise, you ego chokes on you getting basic historical facts wrong. If you and those you mention are so clever, you don’t need Amlogic or Baylibre, just write it all yourselves.
Neil, Jerome, and Maxime are all from BayLibre doing work on GXL. I spent the last two years working with them to upstream the numerous parts we needed for Le Potato. If you don’t know who they are, you should read the kernel mailing list for Amlogic upstreaming.
Martin did a heck of a job for GXBB as his hobby. ODROID-C2 would still be in the stone ages without him because HardKernel only used Amlogic’s openlinux, which is stuck on 3.14 for GXBB.
Amlogic could and should do more in supporting upstream especially for GXL because they have tens of millions of deployments and all those things would become e-waste without upstream. There is a lot of potential applications for these chips outside of boxes although boxes move the most volume.
I actually agree with you about the use of the SoC outside TV boxes and TV. Being fair to Amlogic that is their main market and they have worked with Google on Android for those two markets.
Hardkernal and other board makers etc should be paying towards linux driver support because their products use it.
If you are that sures you can bring all concerned together , baylibre and all Amlogic Linux board makers, then approach Amlogics sales director, and make your case for working together to expand their sales software support, for the expanding market.
Currently Libre Computer sponsors BayLibre to get mainline Linux support for some old Amlogic SoCs. Can you please summarize what Amlogic provides for these new SoCs now and an estimate when they could be usable with something different than Android?
AFAIK, Amlogic themselves hired BayLibre to bring support to mainline Linux. Here’s quote from BayLibre blog (January 24th 2018):
It was a match made in heaven: two years ago AmLogic and BayLibre joined forces to bring top-notch support for AmLogic SoCs into the mainline Linux kernel.
> two years ago
Sorry, I was not talking about what might have happened some years ago but focused on ‘currently’: https://www.cnx-software.com/2018/09/22/amlogic-s905y2-s905x2-s922x-boards-android-9/#comment-556195
Amlogic is mostly focused on AXG and G12. They haven’t really done a thing for GXBB or GXL since 2017. tkaiser is absolutely correct on this one.
Baylibre words
” January 24, 2018/in Amlogic, Community, Frontpage Article, Linux Kernel /by Mike Turquette
It was a match made in heaven: two years ago AmLogic and BayLibre joined forces to bring top-notch support for AmLogic SoCs into the mainline Linux kernel.
Since that time AmLogic has continued to become one of the most relevant and widely used silicon vendors in the world. Similarly, BayLibre has expanded the variety of SoCs, drivers and frameworks supported upstream all while supporting a growing number of OEMs basing their products off of recent kernel releases ”
Ref. https://baylibre.com/improved-amlogic-support-mainline-linux/
Also covered @ https://www.cnx-software.com/2018/01/24/mainline-linux-on-amlogic-s905-s905x-s912-soc-2018-status-update/