
CNXSoft: This is a guest post by Greg Lytle, V.P. Engineering, Au-Zone Technologies. Au-Zone Technologies is part of the Toradex Partner Network.
Object detection and classification on a low-power Arm SoC
Machine learning techniques have proven to be very effective for a wide range of image processing and classification tasks. While many embedded IoT systems deployed to date have leveraged connected cloud-based resources for machine learning, there is a growing trend to implement this processing at the edge. Selecting the appropriate system components and tools to implement this image processing at the edge lowers the effort, time, and risk of these designs. This is illustrated with an example implementation that detects and classifies different pasta types on a moving conveyor belt.
Example Use Case
For this example, we will consider the problem of detecting and classifying different objects on a conveyor belt. We have selected commercial pasta as an example but this general technique can be applied to most other objects.

Hardware Architecture
There is a wide range of embedded Arm processors suitable for embedded image processing at different power, performance and cost points. Selecting a processor or module family with a range of compatible parts provides flexibility to scale the design if the processing requirements change over the design or product lifetime. Real-time machine learning inference is a computationally intensive process which can often be implemented more efficiently on embedded GPUs or co-processors due to the parallel nature of the underlying tensor math operations, therefore an embedded SoC with one of these compute resources is preferable. Another consideration is peripheral interfaces and compute range required for the balance of the system. Fortunately, there are a number of SoC processors available from a number of silicon vendors which support these features.
For this example, a Toradex Apalis Computer on Module based on the NXP i.MX 8 series application processor was selected. This module is available with up to 2x Arm Cortex-A72, 4X Cortex –A53, 2x Arm Cortex-M4F, 2x embedded GPUs, and an embedded hardware video codec. This module is an excellent choice for industrial applications with greater than 10-year availability and industrial temperature range support. The Linux provided by Toradex allows us to focuses on the application.

Selecting the appropriate image sensor and image sensor processor (ISP) for the intended application is critical for a successful implementation. Requirements such as resolution, sensitivity, dynamic range, and interface are all important factors to consider. If an object is in significant motion with respect to frame rate, then a global image sensor should be considered to avoid tearing distortion in the captured images.
The image sensor interface method is also an important consideration. Interfaces such as USB or Gigabit Ethernet, which are typically used for PC based imaging have additional cost, power and performance issues compared to MIPI CSI or parallel interfaces which are supported on the Toradex Apalis COM.
An Allied Vision Alvium embedded camera module with an ON-Semi MT9P031 sensor was selected for image capture. This camera module uses the serial MIPI CSI-2 interface and contains an ISP for pre-preprocessing of the raw sensor data for optimal image quality. The ISP also offloads the embedded processor from operations such as defective pixel correction, exposure control, and de-bayering the color filter array. The Alvium modules are also a good choice for an industrial/commercial product due to the long availability, range of supported image sensors and machine vision class quality.

Software Architecture
Now that the hardware components have been selected the options for the image processing design and implementation must be considered for the high-level tasks shown in Figure 4.
A Video4Linux2 (V4L2) driver is available for the Alvium Camera module so this simplifies the integration with into the Toradex i.mx8QM Linux BSP. Next, a Blob detector must be implemented to find the multiple regions of interest in the captured image for each object to be identified. Once the regions of interest are defined, they can be fed as input to a neural network inference engine for classification. Finally, the classification results are used to label the source image for display on the GUI display.
The Au-Zone DeepView Toolkit was used to implement the machine learning based image classifier. DeepView supports the desktop design flow shown in Figure 5 as well as the run-time inference engine embedded code that runs on the target platform.
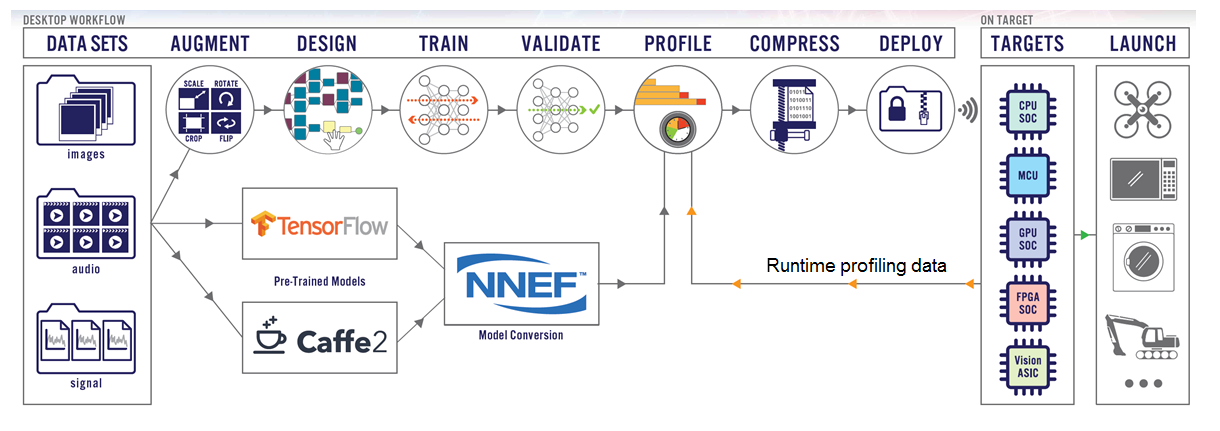
For this example, we selected and imported a pre-trained MobileNet V2_0.35_128 model using the Neural Network Exchange Format (NNEF) interface. The advantage of using a pre-trained model is that it vastly reduces the number of images which must be captured and used to train a Neural Network from scratch. The MobileNet V2_0.35_128 model has approximately 1.66M parameters and requires about 20M MAC operations to execute. This model may be significantly more complex than is required for a classification problem of this complexity but was used to demonstrate the platform can easily support a model of this size.
Training images
For this example, six different types of pasta were used. Four training images of each pasta type were captured using an iPhone on random samples which were independent of the test samples.
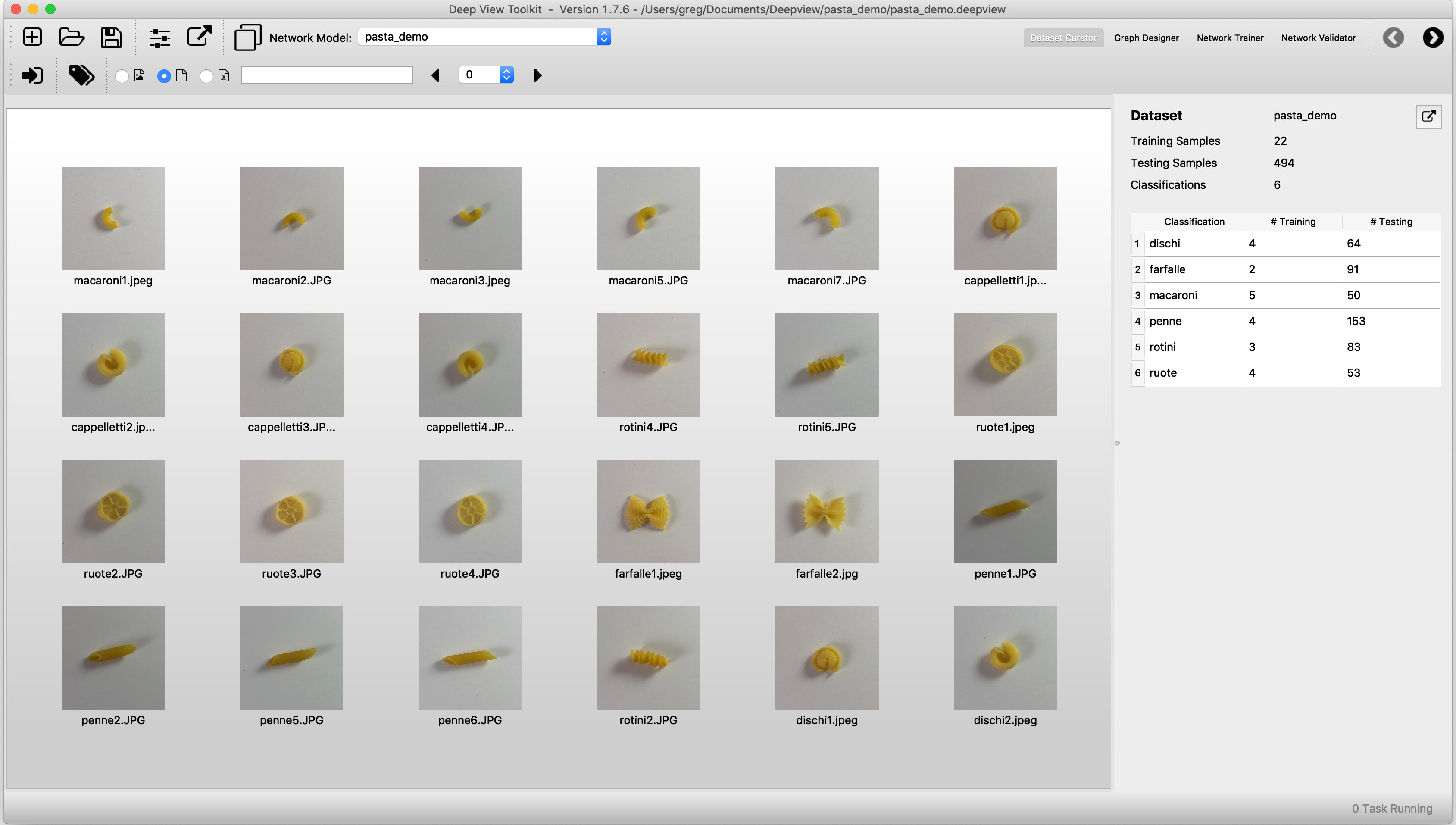
The DeepView Tool imports the small training samples and performs Transfer learning of the MobileNet Model using a Tensorflow backend. Transfer learning Training complete to an accuracy of 98% in this case in about 30 seconds on a desktop PC. Additional validation of the final solution is done to confirm the final accuracy with the embedded camera since a limited number of images were captured for training.
Conversion of the TensorFlow Model to DeepViewRT run-time model for execution on the embedded CPU or GPU.

Software Image Pipeline
The image pipeline for the demo is shown in Figure 9 below. After the image is captured the hardware G2D engine was used to resize the image size for the resolution and region of interest required. The DeepView Camera Server then split the video to an OpenGL Texture for display on the Qt-based GUI and frames for the BLOB detector which was implemented using DLIB with conventional image processing techniques. This was appropriate for a simple object detection task on a fixed background. For more complex detection problems a Single Shot MultiBox Detector (SSD) would be implemented in the CNN, however this would have a significantly higher processing load.
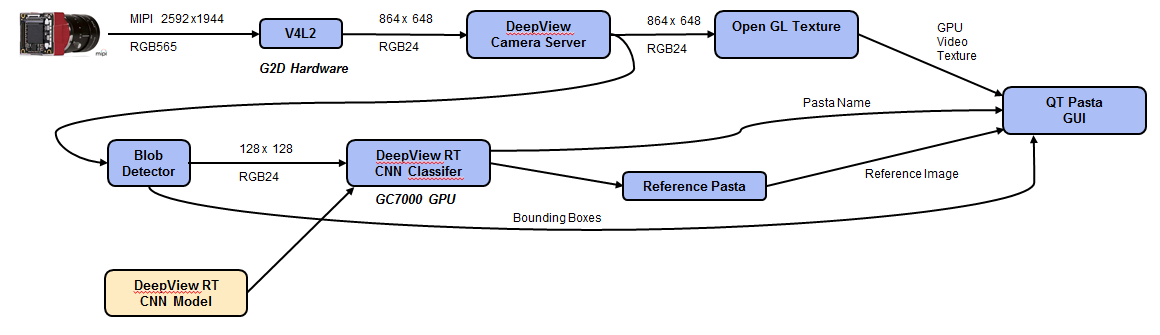
The Blob detector generated bounding box regions of interest for the DeepView Classifier as well as the GUI display.

Finally, the GUI displays the labeled pasta with the original training images show for reference.

Performance
The DeepViewRT run-time engine supports the CNN classifier running on the embedded GC7000 GPU with the balance of the application running on the CPU cores. The inference rate for the Mobilenet V2_0.35_128 is in the range of 36 results per second for this example. The CPU load is dependent on the speed of the conveyor as this impacts the detector algorithm. The current CPU loading for the complete application is in the 15 to 25% range which leaves overhead for a more complex use case or an implementation on compatible i.MX 8 COM module with lower cost and performance.
Further Optimizations
Additional optimization of the image pipeline to fully leverage DMA will further lower the CPU loading, this was not available in the pre-release BSP but is expected to be supported in future releases. The resolution of the captured frames from the camera module could also be significantly reduced for this simple application with future driver updates.
Conclusion
Machine learning is a powerful tool for edge-based image processing. With the selection of available tools and components, it is straightforward to quickly design and implement a low cost, low power object detector, and classifier into an embedded product which leverages both CPU and GPU processing for optimal performance.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


For every beautiful example of synergy between heterogeneous compute units, like in this case between the CPU and the GPU, potentially bringing us to the next compute level, there is a pesky issue like lack of DMA at key points in the pipeline, taking us back to the middle ages, until a driver/framework gets patched/redesigned. A great read, BTW — I enjoyed it thoroughly (mmm, pasta! ; )
What is the total price for the hardware and software as used in this article?
I can comment on the compute HW:
Toradex System on Module is in a price range from about 40 – 200 USD depending on the performance.
The Apalis IMX8QM does not have a public price yet, but as it is a very high-performance module, I would expect it on the higher end.
Also, a carrier board is required they start at 24 USD, the one in the blog is an Ixora which is about 100USD,
Toradex modules built for industrial high-reliability application and come with free software support.
couldnt find info about prices for the dev kit. doubt that the architecture will be powerful enough for complex real world problems. in an embedded chain the machine learning part might be better processed in a specific accelerated hardware, while image preprocessing could be easily done by standard arm based boards next to the cameras.
Pricing for the DeepView Toolkit and runtime is dependent on the application, the target hardware and the target volume. Please contact us directly for more information. We do have customers which are deploying effective solution for applications such as classification, process monitoring, and distracted driving detection on SOC’s of this class and even microcontrollers with significantly lower compute resources, so it is possible to possible to solve real world problems today without Neural Network specific hardware accelerators. I do agree that NPU hardware will improve the machine learning performance for a given power level as this IP becomes available.
Great project and rig to later compare side by side to a board supporting integrated NPU once they get to the mainstream.
hey can you link to a github repo with data and code? trying to build a webapp/game for pasta classification and this would be great to look at