
After announcing their first MIPS Open release a few weeks ago, Wave Computing is back in the news with the announcement of TritonAI 64, an artificial intelligence IP platform combining MIPS 64-bit + SIMD open instruction set architecture with the company’s WaveTensor subsystem for the execution of convolutional neural network (CNN) algorithms, and WaveFlow flexible, scalable fabric for more complex AI algorithms.
TritonAI 64 can scale up to 8 TOPS/Watt, over 10 TOPS/mm2 using a standard 7nm process node, and eventually would allow both inference and training at the edge.
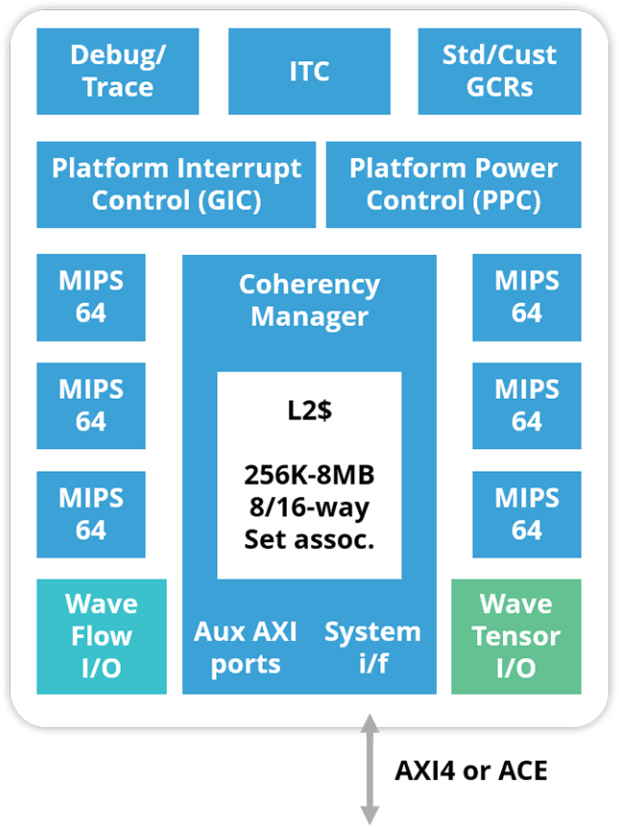
The platform supports 1 to 6 cores with MIPS64r6 ISA boasting the following features:
- 128-bit SIMD/FPU
- 8/16/32/int, 32/64 FP datatype support
- Virtualization extensions
- Superscalar 9-stage pipeline w/SMT
- Caches (32KB-64KB), DSPRAM (0-64KB)
- Advanced branch predict and MMU
- Integrated L2 cache (0-8MB, opt ECC)
- Power management (F/V gating, per CPU)
- Interrupt control with virtualization
- 256b native AXI4 or ACE interface
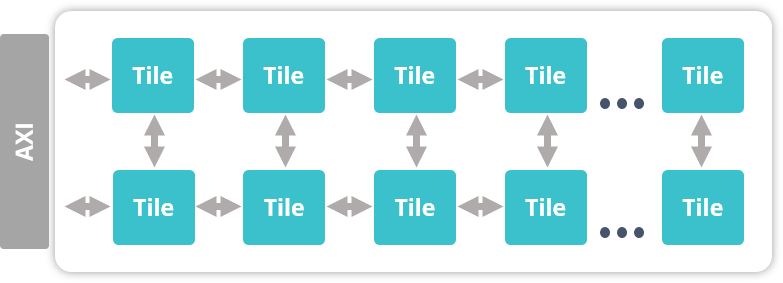
Here’s the description provided by the company for their WaveTensor and WaveFlow AI blocks:
- WaveTensor Technology – The WaveTensor subsystem can scale up to a PetaOP of 8-bit integer operations on a single core instantiation by combining extensible slices of 4×4 or 8×8 kernel matrix multiplier engines for the highly efficient execution of today’s key Convolutional Neural Network (CNN) algorithms. The CNN execution performance can scale up to 8 TOPS/watt and over 10 TOPS/mm2 in industry standard 7nm process nodes with libraries using typical voltage and processes.

- WaveFlow Technology – Wave Computing’s highly flexible, linearly scalable fabric is adaptable for any number of complex AI algorithms, as well as conventional signal processing and vision algorithms. The WaveFlow subsystem features low latency, single batch size AI network execution, and reconfigurability to address concurrent AI network execution. This patented WaveFlow architecture also supports algorithm execution without intervention or support from the MIPS subsystem.
Basically, I understand that WaveTensor is what you’d use for the highest efficiency, and leveraging existing AI frameworks like TensorFlow Lite, while WaveFlow provides more flexibility at, I suspect, the cost of higher power consumption.
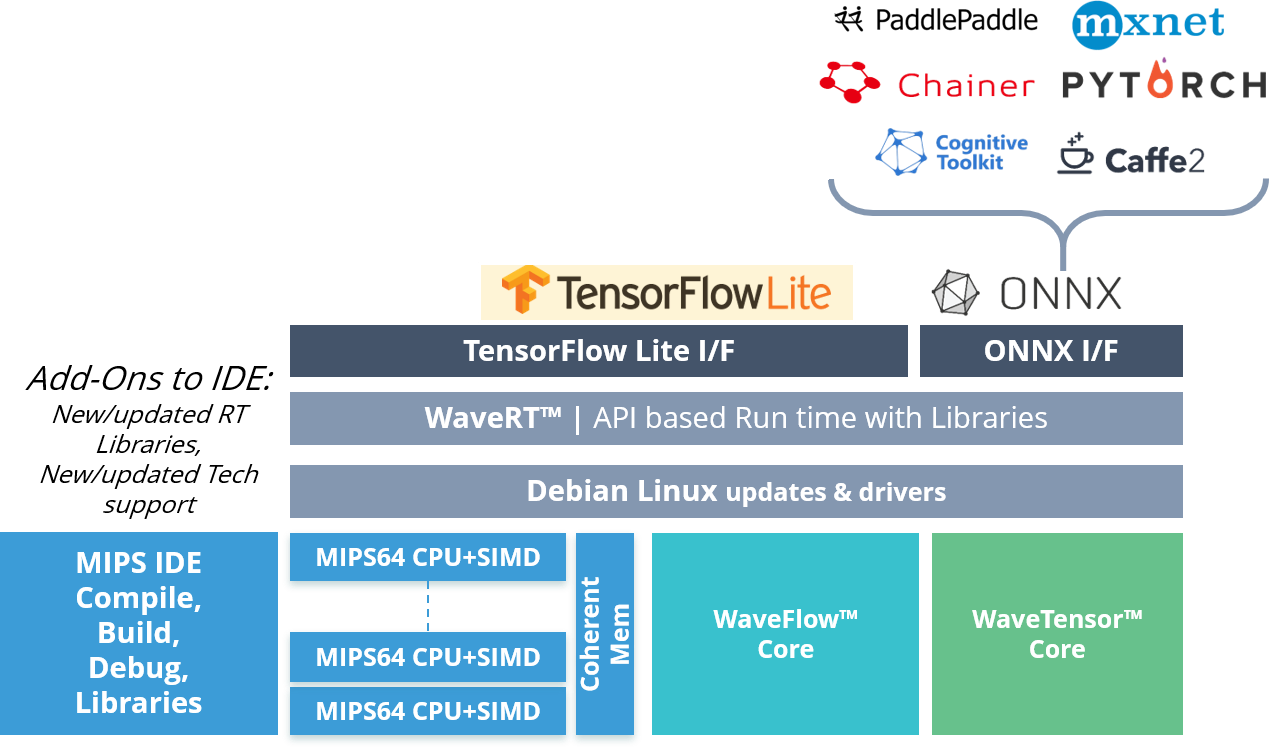
One the software side, Wave Computing offers the TritonAI Application Programming Kit (APK) with the following components:
- GCC Binutil tools and IDE
- Debian Linux OS support and updates
- WaveRT API abstracts framework calls
- WaveRT Optimized AI libraries for
- CPU/SIMD/WaveFlow/WaveTensor
- TensorFlow-lite build support and updates
- TensorFlow build for edge training roadmap
Wave Computing TritonAI 64 is now available for licensing. More details may be found on the product page.
Via LinuxGizmos

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


