
A few months ago, we wrote that SolidRun was working on ClearFog ITX workstation with an NXP LX2160A 16-core Arm Cortex-A72 processor, support for up to 64GB RAM, and a motherboard following the mini-ITX form factor that would make it an ideal platform as an Arm developer platform.
Since then the company split the project into two parts: the ClearFog CX LX2K mini-ITX board will focus on networking application, while HoneyComb LX2K has had some of the networking stripped to keep the cost in check for developers planning to use the mini-ITX board as an Arm workstation. Both boards use the exact same LX2160A COM Express module.
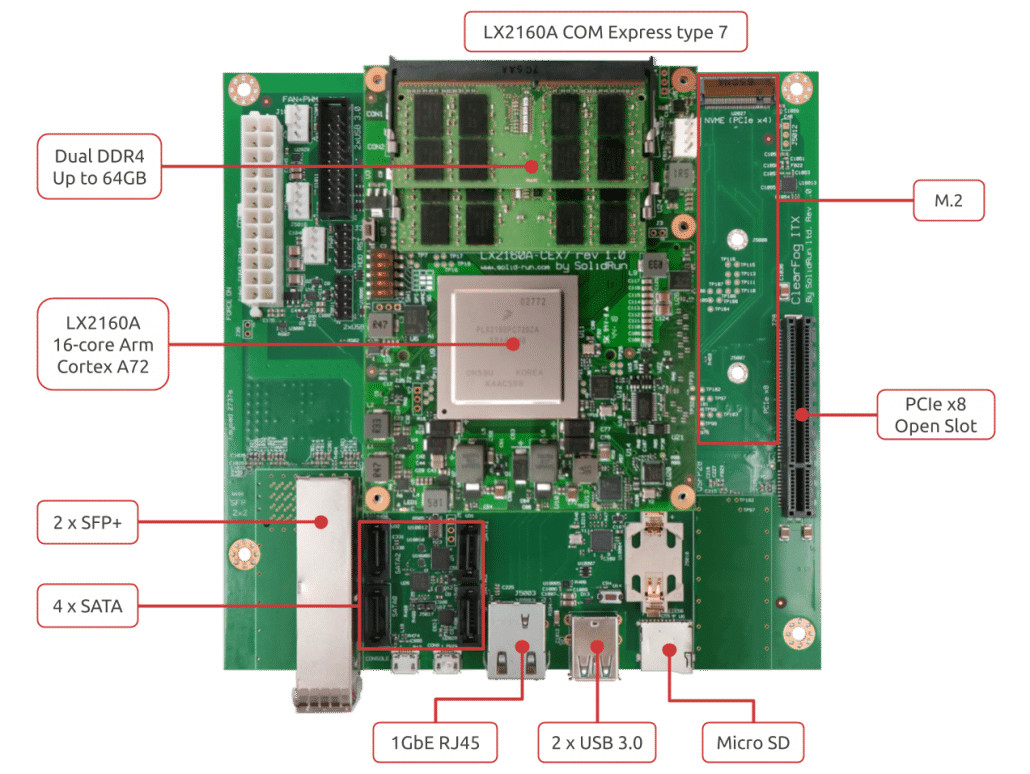 HoneyComb LX2K specifications:
HoneyComb LX2K specifications:
- COM Module – CEx7 LX2160A COM Express module with NXP LX2160A 16-core Arm Cortex A72 processor @ 2.2 GHz (2.0 GHz for pre-production developer board)
- System Memory – Up to 64GB DDR4 dual-channel memory up to 3200 Mpts via SO-DIMM sockets on COM module (pre-production will work up to 2900 Mpts)
- Storage
- M.2 2240/2280
/22110SSD support - MicroSD slot
- 64GB eMMC flash
- 4 x SATA 3.0 ports
- M.2 2240/2280
- Networking
1x QSFP28 100Gbps cage (100Gbps/4x25Gbps/4x10Gbps)4x2x SFP+ ports (10 GHz each)- 1x Gigabit Ethernet copper (RJ45)
M.2 2230 with SIM card
- USB – 3x USB 3.0, 3x USB 2.0
- Expansion – 1x PCIe x8 Gen 4.0 socket (Note: pre-production board will be limited to PCIe gen 3.0)
- Debugging – MicroUSB for debugging (UART over USB)
- Misc – USB to STM32 for remote management
- Power Supply – ATX standard
- Dimensions – 170 x 170mm (Mini ITX Form Factor) with support for metal enclosure
The pre-production developer board is fitted with NXP LX2160A pre-production silicon which explains some of the limitations. The metal enclosure won’t be available for the pre-production board, and software features will be limited with the lack of SBSA compliance, UEFI, and mainline Linux support. It will support Linux 4.14.x only. You may want to visit the developer resources page for more technical information.
With those details out of the way, you can pre-order the pre-production board right now for $550 without RAM with shipment expected by August. This is mostly suitable for developers, as the software may not be fully ready. The final HoneyComb LX2K Arm workstation board will become available in November 2019 for $750. If you’d like the network board with 100GbE instead, you can pre-order ClearFog LX2K for $980 without RAM, and delivery is scheduled for September 2019.
If you are interested in benchmarks, Jon Nettleton of SolidRun shared results for Openbenchmarking C-Ray, 7-zip, and sbc-bench among others.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress


What a fantastic board! It has everything i need really. I wonder what the TDP is and how this should be cooled?
The TDP is 32Watts for the SOC. Currently we are cooling it with a heatsink and a 40mm pwm fan. It should be possible to use a fully passive solution if preferred.
I’d like to thank SolidRun for repeatedly catering to a market that’s been traditionally neglected or taken advantage of.
For a long time their MacchiatoBin was the sole workstation-class (ie. proper expandability options) board an arm developer could *buy* (emphasis vs ‘access in the cloud’, or ‘be provided on the job’), and more importantly, that board remained the go-to choice even after other vendors tried but largely missed their sane price brackets.
Here’s to hoping HoneyComb takes arm workstations for the masses to new levels!
>been traditionally neglected or taken advantage of.
Which market is this? Maybe the market is “neglected” because it doesn’t exist? Highly proprietary workstations died ages ago.
>Here’s to hoping HoneyComb takes arm workstations for the masses to new levels!
Sorry to beat a dead horse and all but why does it being ARM even matter? Don’t get me wrong this is a very good price for one of these high end ARM SoCs that are generally only available as part of expensive equipment but .. would it be less attractive if it was the same price, performance etc but was SPARC instead?
What I’m seeing here is general purpose products versus final products. The vast majority of ARM boards are either a final product (NAS, STB, etc) or a specific purpose board (RPi imitation, focus on gaming/media playing, tablet, smartphone etc). Often they count on their expansion connector to place extra products that will almost never exist.
With workstation boards, you get a *real* general purpose product. In general you have the SoC, the glue around, the network, PCIe and SATA connectors, a DIMM socket for the RAM, and just like with a PC, you do whatever you want with it by adding what is missing for *your* use case. It’s not limited by a simplified device tree that you have to hack like the other boards, and you’re not forced to buy the board that does 90% of what you’d like, hoping that with your soldering iron you’ll manage to address half of the remaining 10%. These boards are totally expandable and allow developers to test the technology itself then design a final product matching what they’ve assembled.
Regarding your question about SPARC, I would personally be interested as well (I have two at home but they make too much noise for me) assuming it comes with the same capabilities as the ARM boards. People are currently focused on ARM because ARM is at a price-performance point that is extremely appealing for many use cases, all this often with a very reasonable power budget. It usually suits the “just fast enough” goal.
>What I’m seeing here is general purpose products versus final products.
I think you’re talking about propriety versus generic.
>The vast majority of ARM boards
I don’t think that problem is at a board level. You can’t really buy an ARM chip that’s not a highly integrated market specific product.
>With workstation boards, you get a *real* general purpose product.
mm but this seems much more like an old propriety workstation from Sun if it really is a workstation.
Almost everything except the memory is integrated into the SoC and you have one expansion connector.
You’ll have a GPU in that connector so your expansion possibilities are right back to zero.
This feels much more like the old microcomputer days when an upgrade would be a card that replaced the whole machine and used it’s corpse as a glorified power supply.
>just like with a PC, you do whatever you want with it by adding what is missing for *your* use case.
A $100 PC motherboard has 5 or more industry standard expansion connectors on it.
>These boards are totally expandable and allow developers to test the technology
>itself then design a final product matching what they’ve assembled.
For this board I’m not seeing it. You have one pci-e connector that is gone if you want a local display.
If you want more pci-connectors you need a custom backplane board with those broken out if there are any spare lanes in the SoC for that.
>People are currently focused on ARM because ARM is at a price-performance point
That makes sense if that’s the actual reason and not “just because it’s ARM”.
I have some nostalgia for ARM as I used one of the first RISC PCs built at school but I wouldn’t fight a holy war for them.
ARM in the cloud and on the edge is growing market. In general you need devices that are powerful enough to service these workloads, but also power efficient and able to run in extreme temperature conditions. It is just far easier to develop on the same architecture you want to run your application on.
>It is just far easier to develop on the same architecture you want to run your application on.
I don’t see how that is even remotely true. People are deploying code they developed on generic X86 Dells and mac books to millions of devices running all sorts of weird CPUs on a daily basis.
If there weren’t reasonably fast X86 machines out there would be no Android or iOS fuelling ARMs mobile boom because it would been impossible to compile either of those OSes for the targets.
Did you ever develop large apps with cross-compilers? Did you ever debug them? That can be a real pain. There’s no denial it’s infinitely easier to do development natively.
>Did you ever develop large apps with cross-compilers?
Yes. FYI most if not all builds of the “large app” known as Android that are in the wild on millions of devices will have been built on an x86 machine because of the memory required.I suspect the situation is the same for most yocto, buildroot etc systems floating around. Pretty much every Android or iOS app you can install will have been built on an x86 machine, debugged in the x86 emulators and cross-debugged between an x86 host and an ARM target.
>Did you ever debug them? That can be a real pain.
Right now I’m debugging a port of u-boot to a new ARM platform from a generic x86 machine..
Good luck tracking performance on your emulator, especially for iOS when your “emulator” is running an app compiled to native x86. And good luck tracking any MT issue on any of those emulators.
Firmware and boot obviously are a different beast for reason I won’t list as I don’t want to insult your intelligence.
>Good luck tracking performance on your emulator,
>especially for iOS when your “emulator” is running an app compiled to native x86.
The profilers for android and ios are actually better with the emulators (FYI Android uses KVM now so it’s the same deal) because the environment is more predictable. Many commercial Android devices have all sorts of crap going on and hacks to the OS that mean something you see on one device might not be true for the majority of devices in the field. There are usually lots of weird crashes and other issues that only ever happen on Samsung devices for example.
The GPU profiling stuff is probably the only area you need a real device.
>And good luck tracking any MT issue on any of those emulators.
I have done this many times. In fact the emulators can be better for tracking down those sorts of issues because they run much faster than a real device in many cases and trigger issues that don’t happen on a real device because nothing is running fast enough or in parallel.
>Firmware and boot obviously are a different beast for
>reason I won’t list as I don’t want to insult your intelligence.
Why? If the native machine is so important for development then surely it would be most important when you’re running on the bare metal without a kernel and os layers removing most of the properties of the actual machine from view.
Many configure scripts are probing the host machine instead of hypothetical target device. That makes it easier.
So the solution to a broken build system is not to fix the build or replace it with something that works well with cross compiling (i.e. meson) but to buy an expensive machine to do the compile on the target itself? This sounds like a good excuse to get a higher up to approve your expense request for a board you want to mess with.
dgp is correct, I also do cross development work all of the time without any issues. Some recommendations…..
If possible boot your device off from the network, or use a network share to load your apps. That avoids the need to flash over and over again.
Learn how to run gdb remotely. If you are working with low level stuff, learn how to use a JTAG with gdb. JTAGs are dirt cheap, you can buy for $30. JTAG can be more effective than working directly on the hardware since they minimally disturb the system.
For Android adb over USB is quite effective. There are also ports of adb for Linux around not that work with native Linux apps on the target system – no Android needed.
If you hate doing cross development work is is likely one of these recommendation is your pain point.
As for emulators – I rarely use them. The hardware is emulated and doesn’t exactly match the real hardware which messes up debugging. Emulators are probably fine for app development, but I mainly work on OS level code.
@Jon
I wouldn’t say the process is painless. For microcontroller stuff just working out how to get OpenOCD to stop the target running properly can be a major pain point..
For stuff running on Linux though I usually forget what the actual machine is either way and it’s much more convenient to do the development work on my desktop machine with tons of RAM, a decent GPU, youtube on demand etc and push it onto the target when I want to test it than trying to keep multiple machines running with all of the tools and other junk.
With Android stuff I can have 10 emulators with different versions Android of running on my desktop, deploy the app to them at the same time. A few years ago you literally had to have a phone with each major version to test with because the ARM emulator was slow as hell and the whole process was a nightmare.
At work our ALOHA load balancers are entirely cross-compiled as well and it’s not a pain at all. It provides a nice set of benefits such as never depending on the build environment at all (which is why we switched to cross-compile even for x86->x86). The time lost dealing with cross-compilation issues is largely offset by the time saved not having to debug artefact caused by stuff that is not part of your product! Regarding emulators, I don’t like them either, mainly for the same reasons : when you spend one week figuring that the bug you’re looking at can only happen in the emulator, you have good reasons to be angry 🙂
> dgp is correct, I also do cross development work all of the time without any issues. Some recommendations…..
I do what is effectively cross-development during most of my workday (one often does cross-platform work in a huge multi-platform codebase, as one cannot code all code across all platforms natively — that’s not physically possible, but one often debugs and profiles on any of the multiple targets), but dgp is very, very far from correct, and it has nothing to do with if one does cross development or not, or how they ‘feel about it’, etc.
dgp fails to acknowledge (for lack of experience, I assume) the necessity of native development (i.e. code built, deployed, debugged, profiled on the target), but instead brings up irrelevant arguments like his uboot example — of course you do cross-platform on devices which cannot do self-hosted debugging. E.g, you cannot ‘natively’ develop on a GPU — latter is always a guest architecture to which you always deploy from a host, and so any kid of GPU debug environment operates on a remote principle. His other examples are funny too — I do remote development from an arm chromebook, but that’s a terminal opened to a remote machines — in no way, shape or form would I call that cross development.
So, back to the subject of when native development has no better alternatives — consider the following example steps from my daily routine (I’ve deliberately excluded any debugging from the picture for the sake of simplicity):
1. Build a large app — you can do that on anything that has the compute and storage capacity, and a proper build environment.
2. Deploy to a target.
3. Run a profile session — collect multi-GB profile logs.
4. Open those for analysis — that in itself can be a daunting task for the host.
Now, clearly (for me at least, doing this most of my 25-year career), steps 2, 3, and 4 are done best in an environment where:
(a) large builds can be deployed as quick as possible
(b) taxing profile sessions take as short as possible
(c) huge profile logs reach the point of analysis as quickly as possible
(d) any profiles pre-processing takes as short as possible
I can do all that in a terminal connected to an all-capable target machine where all steps happen locally, AKA ‘self-hosted development’
OR
I can build locally, deploy to an arbitrary-remote target (AKA cloud), waiting for (2) on each and every deployment, and then carrying (3) and (4) in a terminal to the cloud. Aside from the cross-build step, everything else is self-hosted.
OR
I can build locally, deploy to a cloud, waiting for (2), let the cloud do (3), then do (4) over at my workstation — could be worse than the prev scenario, or better, depending on pesky latencies to the cloud, but that would be the most ‘cross-dev’ approach.
Can the ‘cloud’ be on my LAN? Sure, and then I’d do the 1st and 2nd scenarios (unsurprisingly, that’s how I’ve been doing my job for the past 5 years or so).
So yes, having a target-like host on the LAN when developing for the target architecture has huge benefits, and if your target is an ARM, that host needs to be an ARM as well — that’s the best way for devs like me. Which, of course, dgp would have no clue about, but nevertheless his contributions are always welcome by me.
> Which market is this? Maybe the market is “neglected” because it doesn’t exist? Highly proprietary workstations died ages ago.
Who said anything about ‘highly proprietary workstations’? A dev workstation nowadays is something allowing the unrestricted development of most kinds of software. It takes certain levels of genericity and expandability, as willy mentioned.
> Sorry to beat a dead horse and all but why does it being ARM even matter?
Because you’re developing a massive piece of sw for ARM, and not for something else. If you were developing that for SPARC then perhaps an ARM workstation might not be the best choice. Like an amd64 workstation might not be the best choice for the ARM case.
> I don’t see how that is even remotely true. People are deploying code they developed on generic X86 Dells and mac books to millions of devices running all sorts of weird CPUs on a daily basis.
And that’s better than developing on the target ISA (where viable, as in the case of ARM) because?
> If there weren’t reasonably fast X86 machines out there would be no Android or iOS fuelling ARMs mobile boom because it would been impossible to compile either of those OSes for the targets.
If there weren’t reasonably fast amd64 machines out there there would be reasonably-fast non-amd64 machines out there — amd64 did not invent ‘reasonably fast’. Android and iOS mobile boom would’ve been perfectly fine.
> Right now I’m debugging a port of u-boot to a new ARM platform from a generic x86 machine..
Good. Are you also profiling it on a generic amd64 machine?
BTW, when people refer to ‘large software projects’ they usually refer to codebases in the GBs range, so u-boot does not qualify by a factor of 10.
>It takes certain levels of genericity and expandability, as willy mentioned.
This machine has a single pci-e slot and a semi-proprietary mezzanine connector. Unless you are happy with what it already has on board or have a lot of expansions that are available/usable over USB then this has less expansion than a 90s Amiga.
>Because you’re developing a massive piece of sw for ARM, and not for something else.
In this day and age why would you develop specifically for ARM unless you are targeting something highly specific?
>And that’s better than developing on the target ISA (where viable, as in the case of ARM) because?
Often the target ISA or machine isn’t usable for doing the grunt work. Look at Debian as a really great example of this. Debian is massive. Debian sort of supports a few machines that are not massive (armel, m68k, superh and so on) but are perfectly capable of running Debian to some level. Debian (at least used to) insist on native builds for everything.. There are very few superh machines out there with enough ram to build a kernel. Most of them don’t have enough memory to run the maintainer scripts that create packages even if they have enough to run the resulting binary. superh might not be months and months behind if they allowed cross builds and it wouldn’t get into the situations were everything wants to build against newer libraries that it hasn’t caught up with.
Also x86 machines are cheap. I can buy all of my devs a bunch of generic Dell machines and have one or two expensive boards with a networking SoC on it for doing final testing. Also Dell can come and service those machines if a capacitor or something dies on the motherboard.
>Android and iOS mobile boom would’ve been perfectly fine.
Not without a non-ARM machine that had enough RAM to build it. (pssst the only cheap machines with enough RAM at the time and arguably even now are x86).
>Good. Are you also profiling it on a generic amd64 machine?
Why would I profile it? It’s not performance critical. Reliability is more important.
>BTW, when people refer to ‘large software projects’ they usually refer to
>codebases in the GBs range, so u-boot does not qualify by a factor of 10.
When people refer to “large software projects” they are usually talking out of their arse or doing like you’re trying to do and “power levelling”.
A large project might be measured by it’s code base, by it’s revenue generation or how critical it is. As long as your binary and debug info fit into the machine then debugging with GDB is no different if the code base is 1K or hundreds of megabytes. Things are a little bit different when you’re developing with Android or iOS as the development environment alone would eat almost all of your target’s resources.
(psst: I mentioned u-boot as how the hell do you debug something on the target if the target hasn’t even got DRAM initialisation done. I thought you would have been able to work out what was going on there. This is a site about embedded stuff and I thought you would have noticed).
> Why would I profile it? It’s not performance critical. Reliability is more important.
Yes performance doesn’t matter. You’re kidding right?
And as I wrote above, good luck tracking reliability issues with cross-dev, in particular when MT is involved.
Your u-boot example is stupid because it has the same issues for x86.
>Yes performance doesn’t matter. You’re kidding right?
Not always. A lot of modern computing is about something that is maybe isn’t the fastest solution on earth but fills some other requirements. For example python is slow and eats tons of memory for basic data structures but almost anyone can pick it up.
In this specific case size is actually more important than performance as there is limited space for it.
>And as I wrote above, good luck tracking reliability issues with cross-dev,
>in particular when MT is involved.
Thousands, millions, of developers around the world are doing cross dev. Most of the shiny ARM SoCs featured on this site are going to be brought up by guys with a dev board, a JTAG pod and some generic shitty PC. A lot of Android and iOS devs hardly test their stuff on all of the different supported ARM variants if any before doing releases. There are probably people out there on ARM Chromebooks debugging live applications running on HPC clusters of some other architecture.
>Your u-boot example is stupid because it has the same issues for x86.
I could debug it on an ARM board or another machine that can run the debugger I need. The point is the host running the debugger could be anything as long as the debugger understands the target.
> This machine has a single pci-e slot and a semi-proprietary mezzanine connector. Unless you are happy with what it already has on board or have a lot of expansions that are available/usable over USB then this has less expansion than a 90s Amiga.
Let’s see:
* workstation levels of compute — check
* workstation levels of ram — check.
* workstation levels of network connectivity — check
* a PCIe slot (yes, I could use another one for, you’d never guess, a second GPU, but one GPU of choice is still ok) — check
Perfectly happy.
>In this day and age why would you develop specifically for ARM unless you are targeting something highly specific?
Why would it need to be specifically for ARM? Notice the absence of ‘specifically’ from my original statement:
>>Because you’re developing a massive piece of sw for ARM, and not for something else.
> Often the target ISA or machine isn’t usable for doing the grunt work.
What about when the target ISA or machine *is* capable of doing the grunt work (as is the case with ARM, as I explicitly mentioned in the parenthesis here:
>>And that’s better than developing on the target ISA (where viable, as in the case of ARM) because?
>Not without a non-ARM machine that had enough RAM to build it. (pssst the only cheap machines with enough RAM at the time and arguably even now are x86).
psst: the most common machine of the day would have enough ram.
psst: it could’ve been ARM, or anything else that happened to be popular in that timeframe.
psst: amd64 happened to be that machine in that timeframe. Nothing special about amd64 there.
psst: you seem to be ascribing magical properties to amd64.
> Why would I profile it? It’s not performance critical. Reliability is more important.
..
>When people refer to “large software projects” they are usually talking out of their arse or doing like you’re trying to do and “power levelling”.
Funny, that’s precisely how your arguments looked to me. Since I happen to work on one multi-GB codebase project, and guess what, it’s multi-plaform, and multi-arch. And I have to profile code, on top of the the basic requirements for reliability. You need to go outside mode often, kid.
> (psst: I mentioned u-boot as how the hell do you debug something on the target if the target hasn’t even got DRAM initialisation done. I thought you would have been able to work out what was going on there. This is a site about embedded stuff and I thought you would have noticed).
psst: thanks for the laugh.
>Why would it need to be specifically for ARM? Notice the absence
>of ‘specifically’ from my original statement
You made the point about this being ARM and that being great and I asked why it has be ARM and not say ARC, RISCV,..
>Because you’re developing a massive piece of sw for ARM, and not for something else.
That sounds like a real edge case and I suspect is why you think this target demographic is so badly treated or unsupported. (psst: because the target demographic is 5 people working on apps and guys working on networking equipment)
>psst: amd64 happened to be that machine in that timeframe. Nothing special about amd64 there.
Exactly my point. The point is you needed some other machine to get anything to run on the target. Ergo doing the development work on the target isn’t so important and maybe impossible in a lot of cases.
>psst: you seem to be ascribing magical properties to amd64.
The magical properties being it’s cheap as dirt, even the garden variety can have 64GB of ram attached, generic, expandable. These are things you seem to think are good to have.
>You need to go outside mode often, kid
This is why I enjoy arguing with you. It takes one simple question with a simple answer and you’re calling people kids. Maybe you need to work on more than one project?
> That sounds like a real edge case and I suspect is why you think this target demographic is so badly treated or unsupported. (psst: because the target demographic is 5 people working on apps and guys working on networking equipment)
Clearly SolidRun selling 5 macchiatoBins must have made them release a larger, more serious product. (psst: I didn’t say the market was large, I said it was neglected by prospective vendors, or mistreated by margin chasers. You brought up dells and macbooks, for some obscure reason).
> Exactly my point. The point is you needed some other machine to get anything to run on the target. Ergo doing the development work on the target isn’t so important and maybe impossible in a lot of cases.
I must be repeating myself for the 3rd time here, and you keep ignoring it (I wonder why):
How about those cases where it’s *perfectly possible* and *beneficial* to do the development work on something identical or as close to the target as possible?
> The magical properties being it’s cheap as dirt, even the garden variety can have 64GB of ram attached, generic, expandable. These are things you seem to think are good to have.
Yes. Plus native development. Can the garden variety do native developement? No, oh, well, an non-garden-variety (ARM) workstation for me then.
> This is why I enjoy arguing with you. It takes one simple question with a simple answer and you’re calling people kids. Maybe you need to work on more than one project?
For now I’m perfectly happy with this project, but I’ll consider your suggestion.
>How about those cases where it’s *perfectly possible* and *beneficial*
What are they? Which situations does *your editor of choice* run better on ARM than anything else and in which situations does your toolchain produce different outputs depending on the machine it runs on for a specific target?
>No, oh, well, an non-garden-variety (ARM) workstation for me then.
There we go. This machine is good for *you* and a tiny amount of other people for mostly religious reasons hence almost no one makes them and if they do they are prohibitively expensive. This is something akin needing a Coldfire based Atari because *reasons* and wondering why such a thing would be expensive.
Almost no one else needs an “ARM workstation” and are most likely better off doing their work on a crappy generic laptop at starbucks and chucking a build off to AWS or another cloud provider that has ARM instances when that one weird client complains that it doesn’t work on their unicorn machine.
Having to have a specific machine screams broken workflow to me. For a multi gb super project like yours I would have expected CI to be doing your bulk builds and tests on all of your targets without you even thinking about it.. when I worked in mobile games we did automated builds of Linux x86, Windows x86, Android ARM/x86, iOS ARM/x86 and unit tested them with a couple of old rack mount servers and an iMac and that was years ago. It should be possible to do all of that in the cloud for almost nothing now. Throwing an Android build off to a rack with all of the popular phones is built right into the tooling.
>For now I’m perfectly happy with this project, but I’ll consider your suggestion.
That’s nice and all but all of your arguments always follow back to it. Which is really funny because you constantly accuse me of being a kid and needing to broaden my horizons etc.
> Which situations does *your editor of choice* run better on ARM than anything else and in which situations does your toolchain produce different outputs depending on the machine it runs on for a specific target?
Guys, you’re arguing because one thinks a gray thing is white while the other sees it black!
While I prefer cross-compiling and consider it the most reliable way to achieve long-term software maintenance, I found myself many times running gcc on my NanoPis or mcbin when doing some research work or trying to optimize a small piece of code, just because it’s way easier and faster to change a constant, save, press the up arrow and enter to issue gcc and run a.out again, or to manipulate optimization options on the gcc command line. Yes in *some* cases it *is* convenient to develop on the machine itself, just like it’s sometimes convenient to have access to different distros because the target distro for a project might differ from the one on your development machine.
I’ve always been in favor of using the best tool for the job, and if one tool manages to save me two hours on a project and these two hours cost as much as the tool, I
would be foolish to refuse to use this tool. It’s also the reason I use exclusively fanless systems : they lie on my desk always up and accessible. It’s faster for me to ssh into my NanoPI to cat /proc/cpuinfo for extension flags than to look them up on google.
What’s $500 in a product development budget ? If working this way with multiple machines manages to save on development and debugging time, it’s probably already worth it. Personally I consider that my macchiatoBin, NanoPI-Fire3 and M4 have already paid themselves. None of them ever had a display plugged in, but I do value their performance (being able to build fast), and the mcbin’s connectivity. Why would I refrain from using them where they bring me some value just because someone thinks it’s not the most professional way to do development or debugging ? I don’t care, I’m efficient this way and that’s enough for me.
> (psst: I mentioned u-boot as how the hell do you debug something on the target if the target hasn’t even got DRAM initialisation done. I thought you would have been able to work out what was going on there. This is a site about embedded stuff and I thought you would have noticed).
You use JTAG and the SRAM on the chip. That why the chip has SRAM. The SPL part of u-boot loads into that SRAM.
You can do almost anything with JTAG. I once added code to OpenOCD to wiggle the boundary pins on the CPU to initially program the soldered in flash chip. The CPU wasn’t even running yet, it was held in reset. Techniques like this were needed before CPUs started having boot ROMs.
>A dev workstation nowadays is something allowing the unrestricted development
>of most kinds of software. It takes certain levels of genericity and expandability,
>as willy mentioned.
And FYI you just described any generic x86 box I can go and buy from the local PC shop.
I would like to clarify. This is using pre-Mass Production silicon. This was an agreement that we came to with NXP to get the boards into developers hands as early as possible. The only main differences between this SOC and the production will be the support for 100Gbps networking, this version is limited to 25Gbps max. Also note that it was decided that this revision of the chip, will only support PCIe Version 3. There will be a new variant in 2020 that will support PCIe Version 4
What a great NAS / Application Server we can build with it! 🙂
a lot of DDR4 RAM, a 10/25GBe SFP+ module, and a SAS PCIe x8 controller …. WOW! 🙂
The HoneyComb board will be limited to dual 10Gbe SFP+ interfaces. The ClearFog CX LX2K will include the QSFP28 cage that will allow for multiple 25Gbe connections, or a single 100Gbe.
Yes it could but IMHO… you can also go TODAY with cheaper and more practical solutions with AMD V1000 series based mini-itx boards, the v1605b runs 12 to 25W after all. Google these:
IBase MI988
ASRock Industrial IMB-V1000
Advantech DPX-E140
DFI GH171
Quanmax MITX-V1K0
First, let’s clarify the “these are industrial boards, end users can’t them!”. Mmm… not entirely accurate. Each of these sites usally has a button “Get Quote”. Just click it and use a corporate email. That’s about it. I did.
I went with a DFI GH171(*). The nvme is x4 wide. The PCI slot is x16 electrical. Has SATA 3. 32Gb DDR4 3200. Plus the unavoidable serial ports because most of these boards are for signage or medical or any other industrial need.
Usually you can buy direct from the manufacturer or from a distributor. The funny part is that for one, in order to get the prices, I was candid and said it was for indivitual use. The response was: sure, no problem! I nevertheless advise you to use a corporate email and do not mention the individual use part 🙂 If they ask for corporate ID, talk to your employer. If they for a description of the project invent something like: internal signage using Xibo or whatever. My experience: nobody asked me this info. Note that some distributors even sell online. So just google for them
These boards are around $500 or more depending on the version of the v1000 you want.
(*) The IBase MI988 looks good too (the nvme is x2 wide though).
The UDOO Bold is less expensive but does not provide all the I/O I need. A castrated beast IMHO.
Like for the “maker” boards, these industrial boards come with the board, the cooler and the I/O shield. That’s it. The power plugs might be “exotic” so some adapter might be necessary. You should know a little bit about connectors, soldering and have a multi-meter to solve the questions. You can grab manual and docs from the web site. From there you’re on your own and without a community support (like you get from Odroid, Pine64, Raxda…) So be sure you know what you are doing.
About the 10G networking. If you look at the current state of affairs, the switches and the cards are expensive. Ans all of that for a meager 10 Gbe link. A cheaper solution is to go InfiniBand with used second hand hardware from eBay.
Avoid ConnectX-2, way too old. Go with ConnectX-3, still current and supported by the last releases of Mellanox OFED on both Windows and Linux (Centos, Ubuntu…). On eBay you can grab a 40Gbe or 56Gbe unmanaged switch(*)(**) for less than $200. For the cards, you can get by for around $75. The tricks is to update the firmware on the card. For that just an older version of the Mellanox MFT (i.e. v4) where the flint burning software allows to changed the PSID of the cards, thus “transforming” and OEM card into a Mellanox card with updated firmware. Then you’re on a roll.
(*) These are noisy beasts (4x15K rpm fans). Not for living room use, unless you mod it with silent more civilized fans. I did, works fine.
(**) Unmanaged InfiniBand switches for personal use is the best: it’s plug and play, no switch config at all, the sofware management comes from the nodes. You just need to start opensm on at least one node and you’re up and running.
I expect a Mellanox MCX354A-FCBT to work AOK in the PCIe x16 of the DFI GH171, the graphics coming from the v1605B CPU (as you may have guessed I don’t give a damn about graphics).
I validated the solution with modern PCs (meaning DDR4 3200 and hardware circa 2018). Got iperf3 sustainable at 32Gbe with IPoIB (Internet stack over InfiniBand) 🙂 :)) A Windows 10 got up to 18Gbe copying files over SMB. Due to being busy at work, I have not tried NFS or GlusterFS over RDMA (pure InfiniBand) yet. There is even a Python RDMA package 🙂
Tip: use optical cables, you can find used ones for $50~$90 depending on the length. When you received one, check it’s not bent anywhere and verify it’s in working condition right away. DAC copper are OK too for small distances (1m -> 5m). Active optical are AOK over 10-15 m.
After results beyond my expectations, I ordered on eBay a 56 Gbe switch for about $175. The additional 16Gbe will compensate for the IPoIB overhead. For cables, make sure you buy 40Gbe or 56Gbe depending on the case.
CONCLUSION
– For storage and network, forgo 10G Ethernet (too slow!) and go direct for the moon with InfiniBand used hardware. You’ll thank yourself over and over. I do.
– If you use it with “old” hardware (i.e. PCI 2.x), your hardware will be the bottleneck with speeds topping at 12Gbe.
– The 40/56Gbe cards requires PCIe 3 8x, anything less, they will run at 5GT (or less) instead of 8 GT and speed will obviously suffer.
– FAST memory is a must (again DDR4 3200).
– While the CPU is not the most important part if you’re using RDMA, it becomes much more important when using IPoIB because then the IP stack is used on top of RDMA. Same thing for the storage: if want to have 30+ Gbe over the network it means that your storage also must provide it in read and write.
– Mellanox is a hardware company: they play nice and let you download software, firmware and docs without hassles.
– Do your home work, read a lot about InfiniBand before making the plunge. It’s a total different beast than Ethernet. Don’t believe everything you read on the Internet. Double-check the posting date of articles, some of the stuff is archaic and borderline funny.
– Good source of information:
– https://www.rdmamojo.com/
– The docs, even the Marketing product briefs, on the Mellanox web site.
– You can register for free to the Mellanox forums and Academy.
– Other forum: https://forums.servethehome.com/index.php
– You can also find 100Gbe Mellanox hardware on eBay. BUT, still quite expensive and the cards requires PCIe 3 16x. Finally I do not think that “reasonable” consumer PC hardware can take it anyway. In 10 years maybe.
– If you want esoteric features with RoCE, VM and other sweet things on a server you may want to put a ConnectX-4 in that server instead of a ConnectX-3. Do your reading prior buying (I mean RTFM the Mellanox user guides freely downloadable).
Finally, sub-$200 maker boards cannot deal with high-speed networking. Not enough oomph yet. Wait for 5? 10? years. I’m still trying to make a Mellanox card work on the PCI 4x of the RockPro64. The card does not even show up as of this writing. A little bit beyond my skills to find out why 🙂
Out of curiosity: what’s the use case for the InfiniBand setup you propose?
As for your RockPro64 not working with the Mellanox card maybe doing a web search for ‘rk3399 pci aperture bar’ might help.
1) File servers (Samba, NFS)
2) Distributed file servers (GlusterFS, Lustre)
3) Distributed DB (Cassandra)
4) Distributed Apps (MPI)
5) Anything networked which can be optimized by adding the RDMA interface.
6) Anything networked which cannot be optimized with RDMA but will profit from IPoIB.
For the RockPro64 TYVM for the suggestion. I’ll look into it. The card does not show in lspci and dmesg shows some cryptic error.
Forgot to mention:
7) Remote VM
8) iSCSI
The use cases you mentioned are more or less ‘network/storage in general’ and stuff I’m rather familiar with. But I wonder whether client access isn’t also an issue? Do all your clients get also equipped with Mellanox cards or do you utilize an Infiniband to Ethernet bridge or something like that?
For this project I don’t have clients. It’s a home project, I’m the only “client”. Answer: yes you can do both. My original need was much faster network to move my VMware images (40GB for example). But then I learned that IB can do many more things (i.e. for distributed apps.)
The major point is the difference between the IP stack and RDMA. With the IP stack each time a request/response is performed the “client” and the “server” both go through well… the IP stack. This means multiple copies of the data in buffers and the execution is performed by the CPU. With RDMA the data is copied directly from the client app memory to the server app memory and this is performed by the processor on the NIC.
This being said, you can use RDMA to carry IP packets over InfiniBand, that’s IPoIB. Conversely you can use Ethernet to carry RDMA packets, that’s RoCE (RDMA over Converged Ethernet). This allows data centers or corporate networks all equipped in Ethernet to use RDMA without having to lay down new cables.
Hey, very good comment i read with joy. I’ve also been following the EPYC embedded closely and have some good experience with ConnectX-3 with SR-IOV/RDMA/TCP, it’s really fun technology.
How much did you pay for that DFI DFI GH171 board?
Thank you. $479 for the v1605b version (http://www.nextwarehouse.com/item/?2949068). I’m waiting for the other pieces (memory, nvme). The power connector is an “antique” P4 (4-pin square block for Pentium mobos). Fortunately I have “antique” PSUs. For new ones, you also need the molex/P4 adapter. I should be able to try it over the week-end. So you’re probably more experienced on ConnectX-3, I just started two months ago. Fun technology indeed!… and less expensive than brand new 10Ge hardware 🙂
I got the memory this afternoon. I plugged in the 12v P4 from the ATX PSU and shorted pins 4-5 on the PSU ATX power plug to start it. The Mellanox shows up in lspci and -vv states LnkCap 8GT and 8x. More interestingly the LnkSta is also 8GT and 8x. So I’m in business 🙂 Back to work now.
<> Strike that, new PSUes have CPU 8-pin that can be separated in 2 x 4-pin. Quick IPoIB test using iperf3, from 27.7 to 29.6 Gbe with one core at 100%. So it is a very acceptable result for an embedded solution.
This is just awesome. I hope it’s the first of many comparable boards. I hope it’ll do well.
workstation without GPU graphics card no video output? This soc is not for workstation…
You can us a pcie based graphics card that has OSS support. We are targeting the RX 5XX line for initial verification.
The SoC is a networking SoC so it doesn’t have a GPU. Which in the ARM ecosystem is probably a good thing because you wouldn’t want your workstation stuck on Linux 3.18 until the end of time.
It would have been nice if there was one less SFP connector and in it’s place another pci-e slot so you could have a GPU and something else like an a beefy FPGA on a pci-e card. That would be a good match up with the sort of situations you’d use something like this in.
This is something we are looking at for the production release of the ClearFog CX LX2K. The QSFP28 port could also be assigned as an external PCIe connector. Our idea was it would be easier for a developer to have their workstation under the desk and then an external PCIe cage that can sit on their desktop for easier access, prototyping etc. We are still not sure it will be possible with the current IP but investigating for that release.
One of the reasons we split the branding is that HoneyComb will be our workstation lineup so it will give us some freedom for upgrading carriers and provide other options. We hope that the input we get from the developers on this first iteration can be applied to the future revisions.
> ClearFog CX LX2K. The QSFP28 port could also be assigned as an external PCIe connector
That’s interesting. You write about ’18 x PCIe Gen 4 (5 controllers)’ on the developer page. So something like x8, x4, x4, x1, x1 is a possible setup? What’s the maximum width?
BTW: On https://developer.solid-run.com/products/cex7-lx2160a/ you mention ‘Up to 16GB DDR4’ on the overview tab but ‘Up to 64GB DDR4’ under specifications. I guess one is wrong?
Clarification. NXP has redefined the product line and only PCIe Gen 3 will every be supported. As for the PCIe options that is a bit more complex. NXP currently only supports specific configurations of PCIe, SERDES and USB so you need to pick and choose what you want to expose. This is something we are working with them on to hopefully be more flexible, especially because we have the SOC on a COM so we want the carriers to be as flexible as possible.
The maximum width is x8.
Yes the 16GB is incorrect. It is 64GB and we have tested this running at 3000 MT/s
and fixed the incorrect memory specs. thanks for the heads up.
Why is tkaiser not giving his ordeal?
finally what every one here has been waiting for
def my next board
Can SBSA/UEFI and mainline Linux support be added to the pre-production board later, or is it going to be stuck with Linux 4.14 branch forever?
I have asked marketing and sales to update that copy. Those versions are target shipping software, which is actually bumped on the developer board as NXP has just released a 4.19 based BSP. These boards will be fully supported by all mainline support that progresses.
This was my main concern, but if support can be added later sign me up!
Does anyone know if this board supports virtualization?