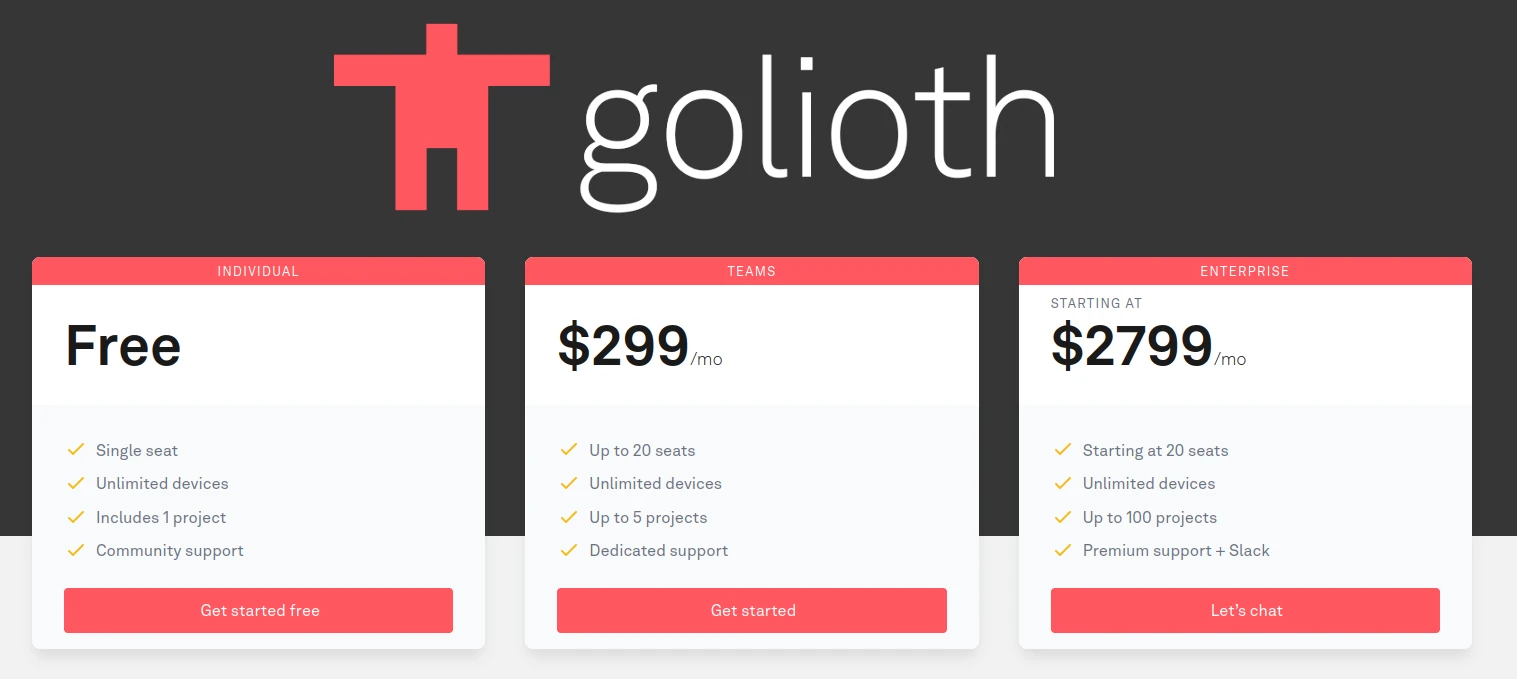
When we first wrote about the Golioth IoT development platform with ESP32 and nRF9160 devices support in 2022, we noted they offered a free Dev Tier account for up to 50 devices, 10 MB of LightDB data with a 7-day retention policy, and other limitations. The company has now decided to remove many of the limitations from the free developer tier without any limit to the number of IoT devices and also added other benefits: Unlimited Device Connections: Empowering developers to scale projects without constraints. Over-the-air (OTA) Device Firmware Updates (DFU) with 1GB monthly bandwidth 1,000,000 Monthly Log Messages up to 200MB Free data retention Time series – 30 days Logs: 14 days The main limitations compared to paid plans are that only one project can be created and a single seat (single loading) is available, so it’s not possible to have a team of users with different permissions like […]
Golioth expands its free tier for developers with unlimited IoT devices, OTA updates, 1GB bandwidth