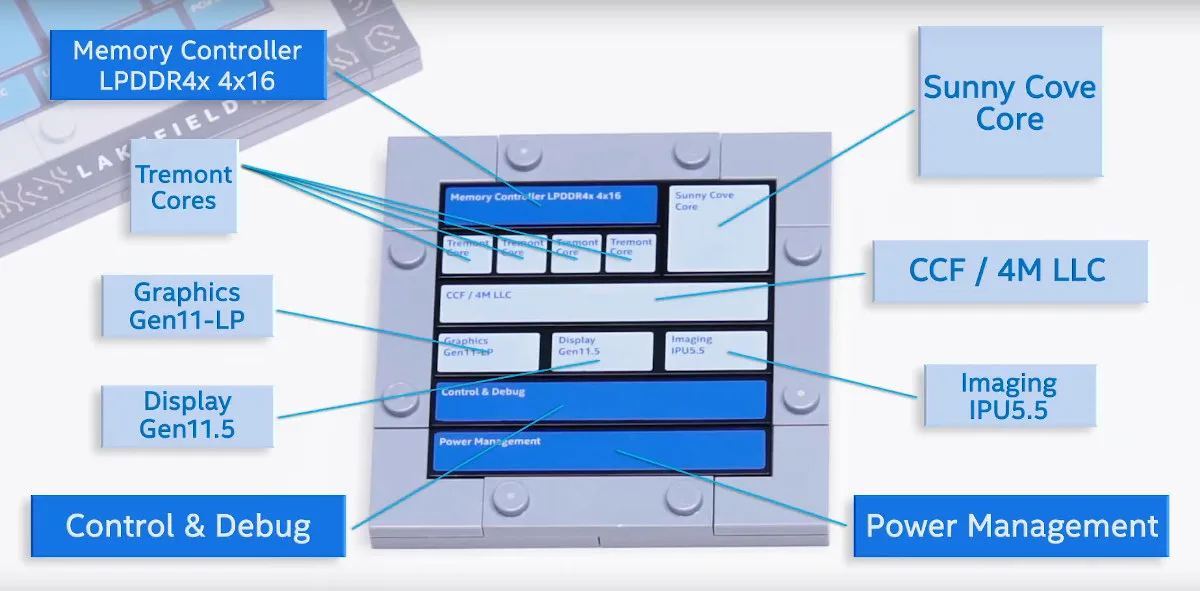
Intel launched Core i3-L13G4 and Core i5-L16G7 penta-core Lakefield Hybrid processors last year with one high-performance Sunny core, and four high-efficiency Atom Tremont cores, in a way that’s similar to what Arm is doing with DynamIQ and before that, big.LITTLE technology. The new processors were found in Lenovo ThinkPad X1 Fold foldable tablet and Samsung Galaxy Book S laptop, both premium products sold for over $2,000. Even some large websites never got hold of a testing sample of those products, and Anandtech has just reported that Intel published a product change notification (PCN) with the title “Select Intel Core Processors with Intel Hybrid Technology, PCN 118334-00, Product Discontinuance, End of Life”. The discontinuance of Lakefield hybrid processors is a shocker considering they were just introduced last year, but I don’t think it will affect many people as I hadn’t heard about any upcoming boards or products based on Intel’s hybrid […]
End-of-life notice issued for Intel Lakefield hybrid processors