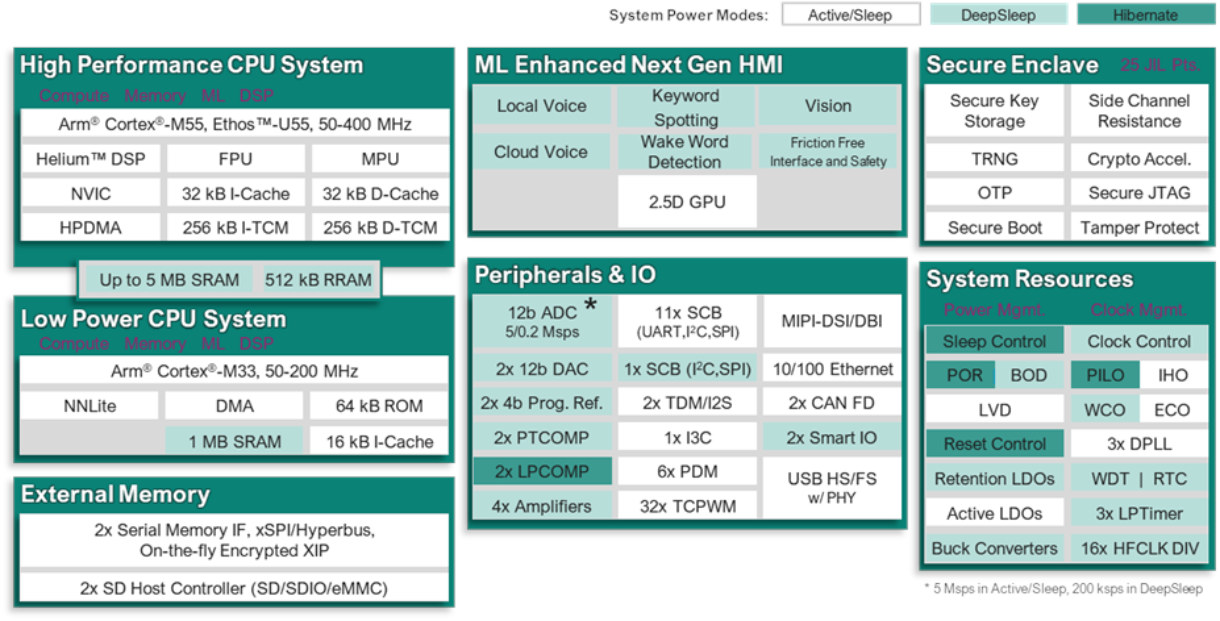
Infineon PSOC Edge E81, E83, and E84 MCU series are dual-core Cortex-M55/M33 microcontrollers with optional Arm Ethos U55 microNPU and 2.5D GPU designed for IoT, consumer, and industrial applications that could benefit from machine learning acceleration. This is a follow-up to the utterly useless announcement by Infineon about PSoC Edge Cortex-M55/M33 microcontrollers in December 2023 with the new announcement introducing actual parts that people may use in their design. The PSOC Edge E81 series is an entry-level ML microcontroller, the PSOC Edge E83 series adds more advanced machine learning with the Ethos-U55 microNPU, and the PSOC Edge E84 series further adds a 2.5D GPU for HMI applications. Infineon PSOC Edge E81, E83, E84-series specifications: MCU cores Arm Cortex-M55 high-performance CPU system up to 400 Mhz with FPU, MPU, Arm Helium support, 256KB i-TCM, 256KB D-TCM, 4MB SRAM (Edge E81/E83) or 5MB SRAM (Edge E84) Arm Cortex-M33 low-power CPU system up […]
Infineon PSOC Edge E81, E83, E84 Cortex-M55/M33 MCUs target Machine Learning-enhanced IoT, consumer and industrial applications