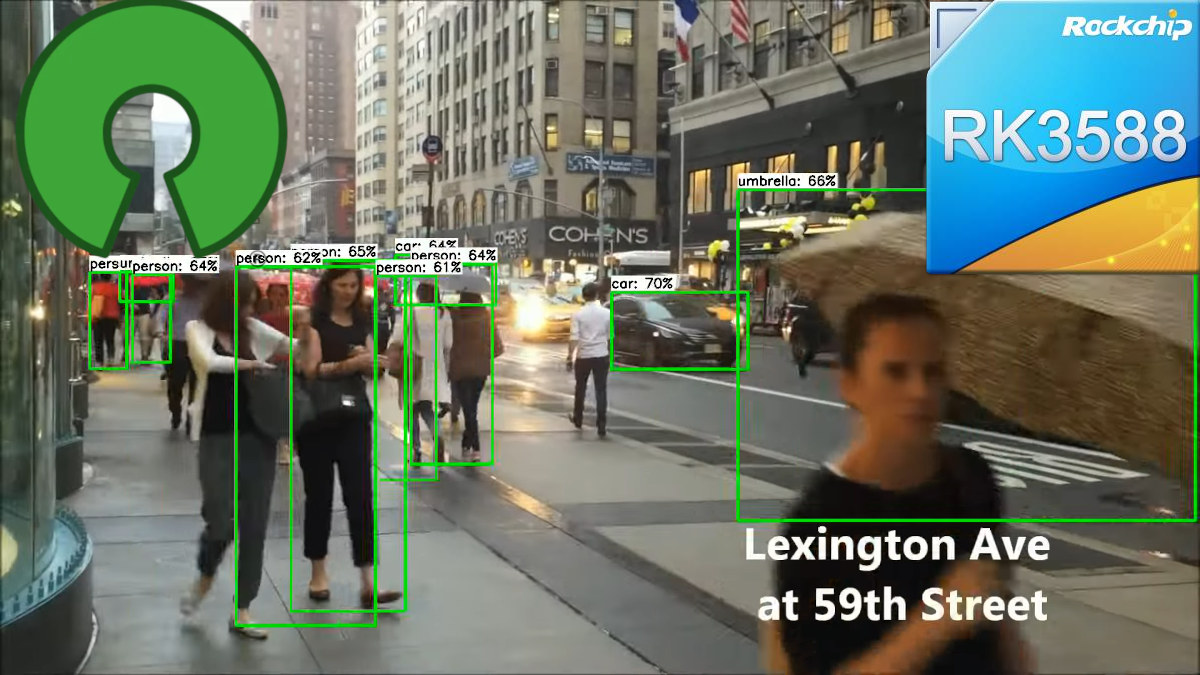
Tomeu Vizoso has been working on an open-source driver for NPU (Neural Processing Unit) found in Rockchip RK3588 SoC in the last couple of months, and the project has nicely progressed with object detection working fine at 30 fps using the SSDLite MobileDet model and just one of the three cores from the AI accelerator. Many recent processors include AI accelerators that work with closed-source drivers, but we had already seen reverse-engineering works on the Allwinner V831’s NPU a few years ago, and earlier this year, we noted that Tomeu Vizoso released the Etvaniv open-source driver that works on Amlogic A311D’s Vivante NPU. Tomeu has now also started working on porting his Teflon TensorFlow Lite driver to the Rockchip RK3588 NPU which is closely based on NVIDIA’s NVDLA open-source IP. He started his work in March leveraging the reverse-engineering work already done by Pierre-Hugues Husson and Jasbir Matharu and was […]
Rockchip RK3588’s NPU open-source driver performs object detection at 30 FPS