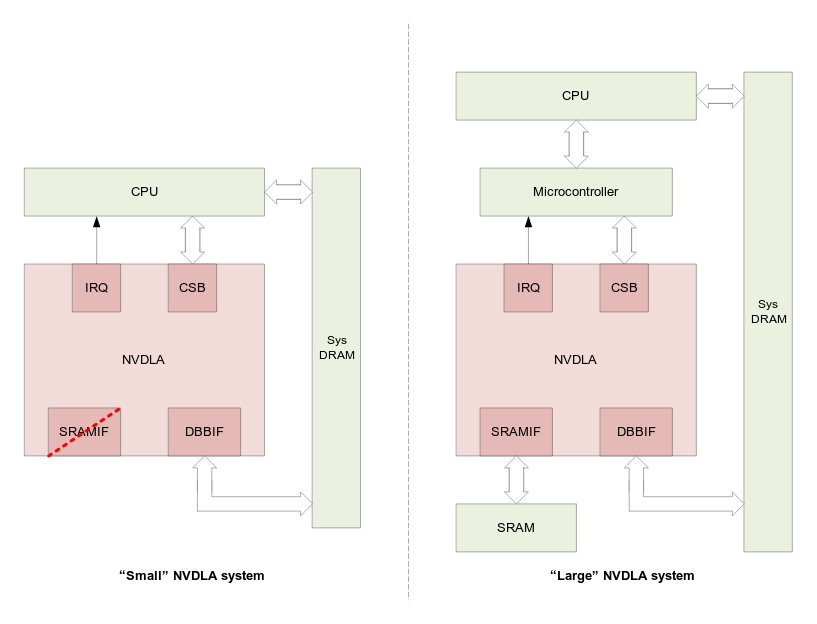
NVIDIA is not exactly known for their commitment to open source projects, but to be fair things have improved since Linus Torvalds gave them the finger a few years ago, although they don’t seem to help much with Nouveau drivers, I’ve usually read positive feedback for Linux for their Nvidia Jetson boards. So this morning I was quite surprised to read the company had launched NVDLA (NVIDIA Deep Learning Accelerator), “free and open architecture that promotes a standard way to design deep learning inference accelerators” The project is based on Xavier hardware architecture designed for automotive products, is scalable from small to large systems, and is said to be a complete solution with Verilog and C-model for the chip, Linux drivers, test suites, kernel- and user-mode software, and software development tools all available on Github’s NVDLA account. The project is not released under a standard open source license like MIT, […]
NVIDIA Unveils Open Source Hardware NVDLA Deep Learning Accelerator