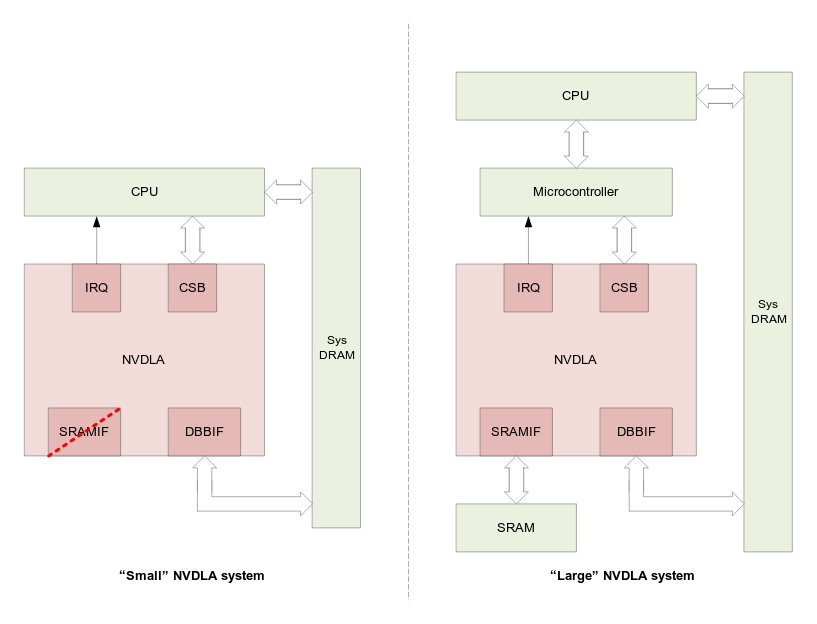
A large patchset has been submitted to mainline Linux for NVIDIA NVDLA AI accelerator Direct Rendering Manager (DRM) driver, accompanied by an open-source user mode driver. The NVDLA (NVIDIA Deep Learning Accelerator) can be found in recent Jetson modules such as Jetson AGX Xavier and Jetson AGX Orin, and since NVDLA was made open-source hardware in 2017, it can also be integrated into third-party SoCs such as StarFive JH7100 Vision SoC and Allwinner V831 processor. I actually assumed everything was open-source already since we were told that NVDLA was a “complete solution with Verilog and C-model for the chip, Linux drivers, test suites, kernel- and user-mode software, and software development tools all available on Github’s NVDLA account.” and the inference compiler was open-sourced in September 2019. But apparently not, as developer Cai Huoqing submitted a patchset with 23 files changed, 13243 insertions, and the following short description: The NVIDIA Deep […]
NVIDIA NVDLA AI accelerator driver submitted to mainline Linux