
Parallella project’s goal is to ” democratize access to parallel computing by offering affordable open source hardware platforms and development tools”, and they’ve already done that with their very first $99 “Supercomputer” board combining a Xilinz Zynq FPGA + ARM SoC to the company’s Epiphany-III 16-core coprocessor. But the company has made progress after their 64-core Epiphany-IV, by taping out Epiphany-V processor with 1024-core last October.
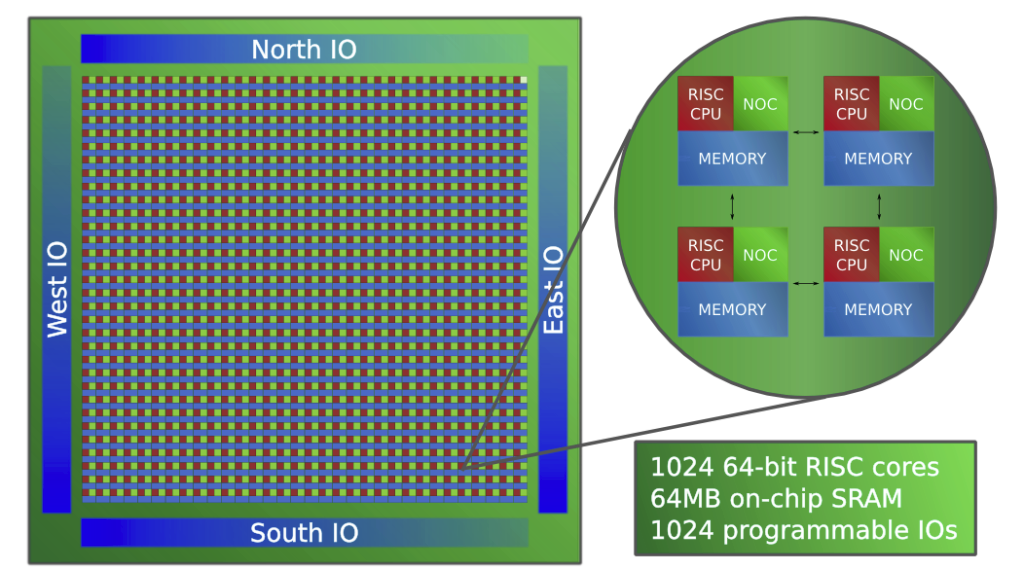
Epiphany-V main features and specifications:
- 1024 64-bit RISC processors
- 64-bit memory architecture
- 64-bit and 32-bit IEEE floating point support
- 64 MB of distributed on-chip SRAM
- 1024 programmable I/O signals
- 3x 136-bit wide 2D mesh NOCs (Network-on-Chips)
- 2052 separate power domains
- Support for up to one billion shared memory processors
- Support for up to one petabyte of shared memory (That’s 1,000,000 gigabytes)
- Binary compatibility with Epiphany III/IV chips
- Custom ISA extensions for deep learning, communication, and cryptography
- TSMC 16FF process
- 4.56 Billion transistors, 117mm2 silicon area
With its 4.5 billion transistors, the chip has 36% more transistors than Apple’s A10 processor at about the same die size, and compared to other HPC processors, such as NVIDIA P100 or UC-Davis Kilocore, the chip offers up to 80x better processor density and up to 3.6x advantage in memory density.
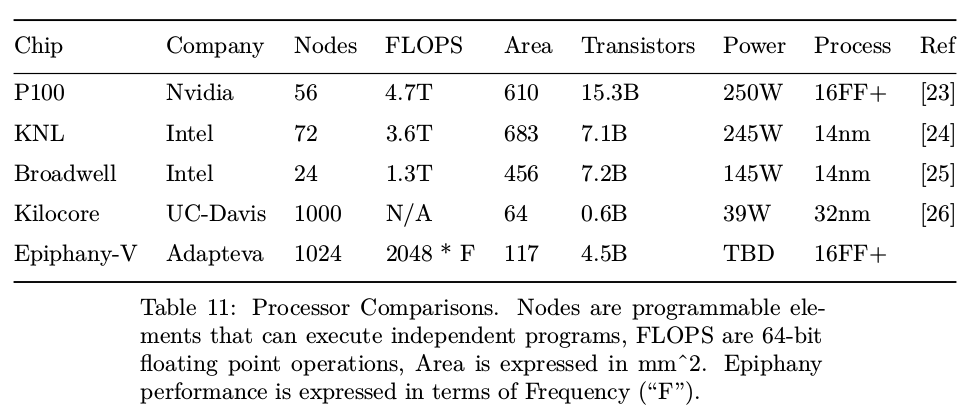
You’ll find more technical details, minus power consumption numbers and frequency which are not available yet, in Epiphany V technical paper.
The first chips taped out at TSMC will be sent back mid to end Q1 2017.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



Very interesting. Reminds me of Chuck Moore 144 core CPUs https://www.youtube.com/watch?v=-ut_b0OB2W0
It makes them hybrid between FPGA and fixed CPUs. The programming creativity is huge.
I’ve just seen they also have a 1024-core simulator that can run on a PC with 16GB RAM -> https://www.parallella.org/2016/12/21/an-open-source-1024-core-epiphany-simulator/
i only want to know the FLOPS to compare or i would never buy one to test.
@Jean-Luc Aufranc (CNXSoft)
Pretty nice pretty nice.
@CNX
So what use will they be put to?
One of Arms original folk works at the university in My town doing neural networks using custom A9 cores. If they have not upgraded yet.
Here you go http://apt.cs.manchester.ac.uk/projects/SpiNNaker/SpiNNchip/
@theguyuk
i wrote a paper about that project, http://www.idt.mdh.se/kurser/ct3340/ht10/FinalPapers/4-Lenander_Fosselius.pdf
a lot of technical details is available here: https://www.youtube.com/shared?ci=XbDLsKE9yAQ
1024 cores backed by 64MB on chip? That’s 64k per core, total. A Skylake has a 32k L1 for each core and an 8MB L2 cache shared between the 4 cores. If all the cores are pulling data at once (which they’re going to be with a cache that shallow) the best they’re going to be able to do is 25MB/s/core with DDR4-3200 (25.6 GB/s). That sucks. Except for a small set of problems, the thing is going to spend most of it’s time stalled out waiting for data. What’s even weirder is their white paper is touting the MB… Read more »
@thesandbender the RAM is distributed and locally accessible to avoid such bottlenecks
I did quite a bit of playing around with the 32-bit 16 core part on the parallella. It’s a cute core. The FLOPS are great and easy to extract. The isa is (mostly) pretty neat and all that. But the RAM bandwidth was abysmal. Even a single core can saturate it and the mesh network routing mechanism means it’s hard to get fair access – each column away from the side connected to the ram gets 1/2 as much access as the previous in a saturated situation. There’s not enough on-core ram, insufficient interrupt capability and too many registers to… Read more »