
CNXSoft: Another guest post by blu where he looks at how a small piece of code involving divisions behaves on different architectures.
Once upon a time (i.e. the other week) I was giving tips to my 5th-grader how to efficiently compute least common multiples, when it struck me I could do better I could write a prime factorizer that could be useful to the elementary-school-goers in this house, as well as to the people checking the formers’ homeworks. Moreover, a naive prime factorizer could show kids how computers would carry out algorithms taught in class. There was also a bit of curiosity involved last time I wrote a prime factorizer I was in high school, and the language was Applesoft BASIC, so 30 years later, armed with a modern C++ arsenal and a supercomputer (by late ‘80s standards), I wondered what one might come up with today, approaching the problem from first principle (sorry, no Euler today).
The naive factorizer was ready in no time thanks to, well, being naive, but mostly to not bothering with arbitrary-precision integers I just used an integral type I thought was suitable to elementary-school problems. The story would have ended there, if it wasn’t for my kid’s reaction with the typical child’s awe, ‘Wow, it’s so fast!’ ..Hmm, was it? It surely was fast compared to pen & pencil (duh), but to a coder ‘fast’ means something else, and this algorithm was definitely not fast. Moreover, I have a professional character deformation of sorts I tend to benchmark and profile most of the code I write. Particularly when the code is small and portable I tend to do that across multiple architectures for education. So I examined the naive factorizer across these (micro-)architectures:
- CA53 armv7l
- CA72 armv7l & arm64
- SNB amd64
- IVB amd64
- HSW amd64
- MIPS P5600 mips32r5
The results did turn out educational. Which is why I decided to share them in this writing.
I did not use the Sieve of Eratosthenes but rather an algorithm I might have first encountered at the age of my kid today; it relied entirely on integer quotients and remainders. Divisions have abysmal throughput and glacial latencies, but at least on the x86 and mips ISAs integer divisions provide simultaneously a quotient and a remainder, and compilers usually utilize that. In addition, I had ‘strategically’ omitted a handful of optimisations for the sake of brevity, resulting in sub-optimal data locality (AoS vs SoA) and a silly selection of candidate factors. All that, topped off with a missing major algorithmic optimisation I had originally overlooked from the outermost loop, naturally resulted in a computationally-taxing ‘benchmark mode’ when fed with a prime argument to factorize, the code would compute all smaller-than-that primes. A bit like the Sieve of Eratosthenes, just very taxing on the div ALUs. Here is the code I went on to benchmark against the ISAs, expecting x86-64 to dominate and armv7l to perform subpar, for lack of division in the ISA (main loop only shown):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
VecFactor factor; // prime factors and their powers go here factor.reserve(1024); Number number = Number(input); Number candidateFactor = 1; while (1 < number) { while (isFactored(factor, ++candidateFactor)) {} // reject composites Number power = 0; while (0 == number % candidateFactor) { power += 1; number /= candidateFactor; } factor.push_back(Factor(candidateFactor, power)); } |
At prima vista, one would expect such a code to use two divisions on x86 one in the inner loop doing power de-factorisation (remember, x86 div yields both a quotient and a remainder from the same arguments), and one in the isFactored routine, used to test candidate factors against already accounted-for primes. What was my surprise to see no less than five divisions in the x86 disassembly! A cross-check with the rest of the architectures showed a similar picture:
- arm7l 4x div/mod (CRT routes for lack of hw div)
- arm64 4x div/mod
- mips32r5 5x div/mod
But why? Loop unrolling? Nope, another of the compilers’ tricks of the trade was at play here. But first some disassembly (all disassembly courtesy of https://godbolt.org/).
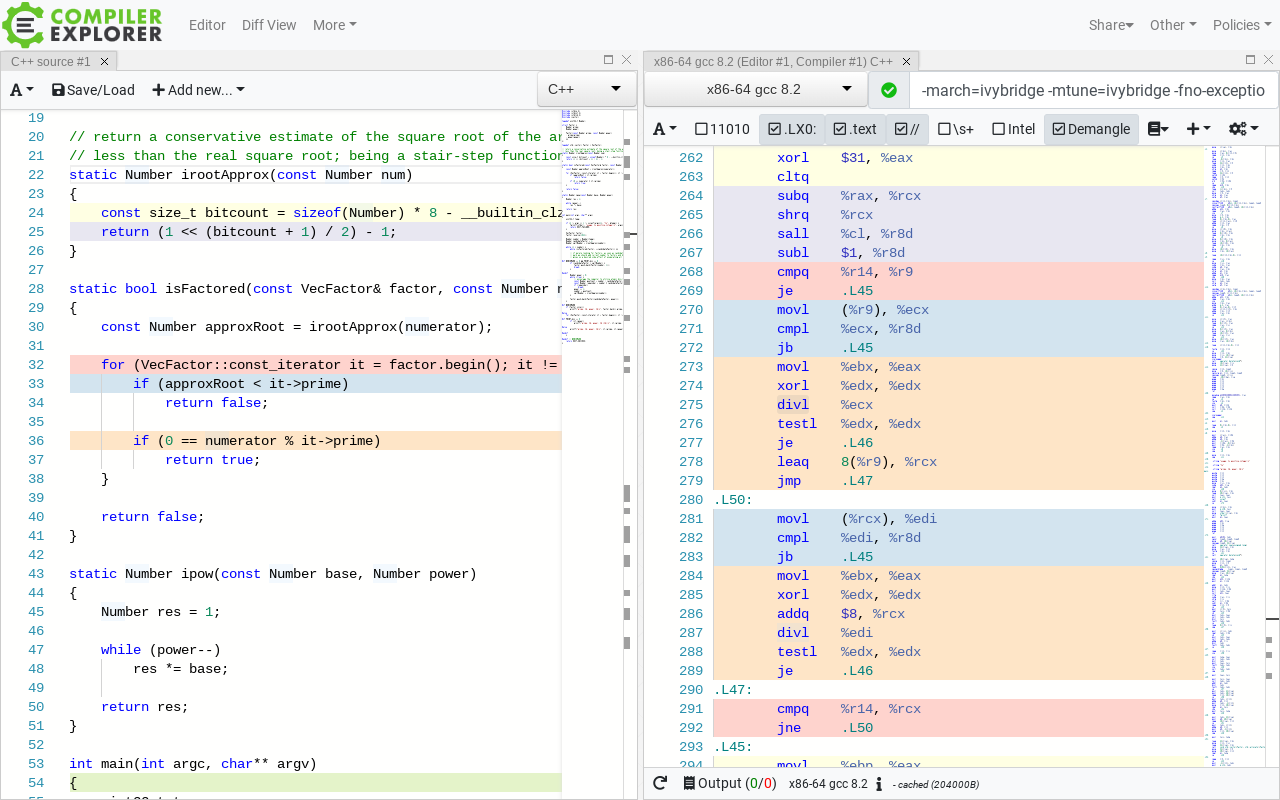
In the right-hand pane above is the isFactored routine, inlined into the factorizer main loop; routine’s sole purpose is to check if a number is divisible by any of the elements on a monotonous vector. For that the routine relies on an early-out algebraic property of monotonous divisors, and a modulo/remainder computation. In the disassembly, though, we see the loop in a special form its first iteration is taken out in front, and the rest of the loop continues from the second iteration. This is a technique known as Loop Peeling, where the leading or the trailing (or both) iterations of a loop would be handled out of the loop, in order to improve the performance characteristics of the remaining (assumed majority) inner iterations. The latter, in this case, happen between label .L50 and the branch on line 292. Only in this case the benefits from the peeling are not clear the peeled first iteration is virtually identical to the remaining iterations, just using different regs that code could’ve been left in an unpeeled loop just the same.
OK, that accounted for two of the five divisions. But this particular loop peeling was also in the rest of the participating ISAs + compilers (read: those ISAs featuring a div op arm64 and mips32r5). Most importantly, this peeling could not pose a performance detriment, aside from code density, so it was OK. What about the remaining three divisions?
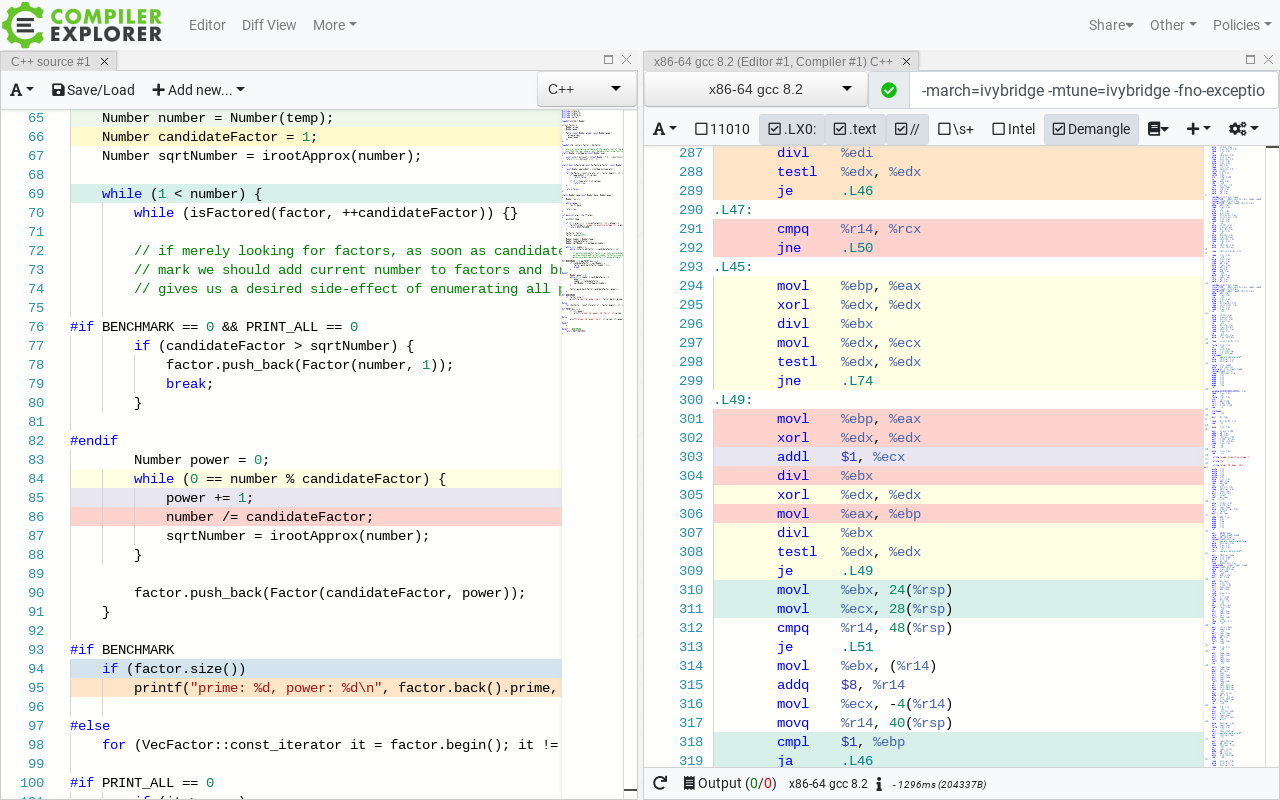
It’s here where things get a bit sinister. Between label .L49 and the branch on line 309 sits the loop of the power de-factorizer from our algorithm (lines 84-88 in the source). Right before it sits the first iteration of the loop, again in a peeled form. Altogether, the loop was reshaped into the following form:
- check first remainder 1x div
- get quotient corresponding to last-computed remainder 1x div
- check next remainder 1x div
- goto (a)
If that loop is bothering you it should. While the first iteration of the peeled loop is OK, the inner body of the so-peeled loop has a redundant division yes, one redundant divisions of abysmal throughput and glacial latency. On an ISA that computes quotients and remainders with one instruction, nonetheless.
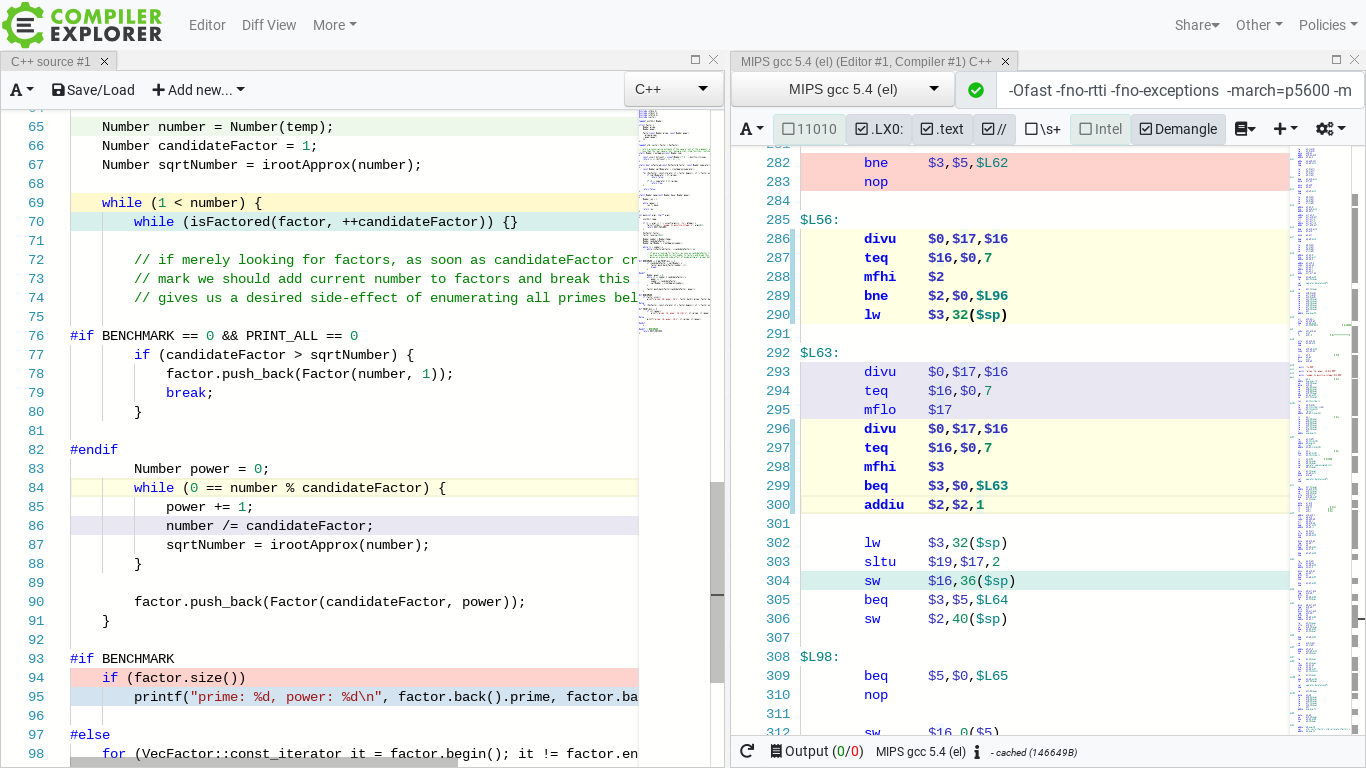
The above issue can be observed across multiple versions of g++ and clang++, and is not limited to x86, but exists also on the other div+remainder single-op ISAs like MIPS, so it’s not a backend issue per se, but apparently one of higher-level transformations (on mips2r5 the corresponding peeled loop sits between label $L63 and line 300):
So what shall we do? For this naive factorizer the issue is nil the power defactorization could never be a bottleneck as it goes up to the highest power of the underlying integral type not a big deal, even if we discussed 128-bit numbers. But this behavior of the compiler is bothersome, to say the least. Can we do something about it (aside from filing a bug with the compiler maintainers)? Well, let’s try.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
VecFactor factor; factor.reserve(1024); Number number = Number(temp); Number candidateFactor = 1; while (1 < number) { while (isFactored(factor, ++candidateFactor)) {} Number power = 0; while (true) { // encourage the compiler to utilize atomic div+remainder, where available const Number quotient = number / candidateFactor; const Number remainder = number % candidateFactor; if (remainder) break; power += 1; number = quotient; } factor.push_back(Factor(candidateFactor, power)); } |
The resulting codegen from the above looks like this on x86-64:
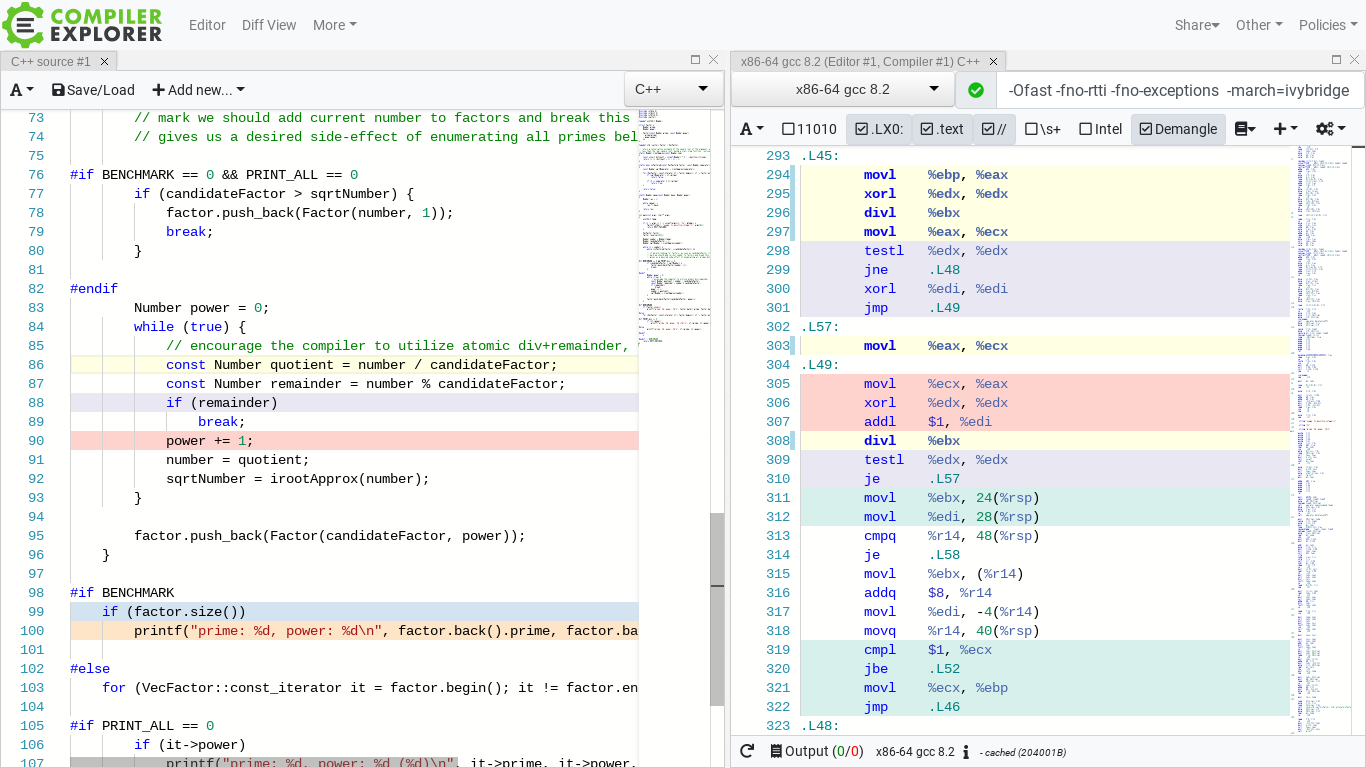
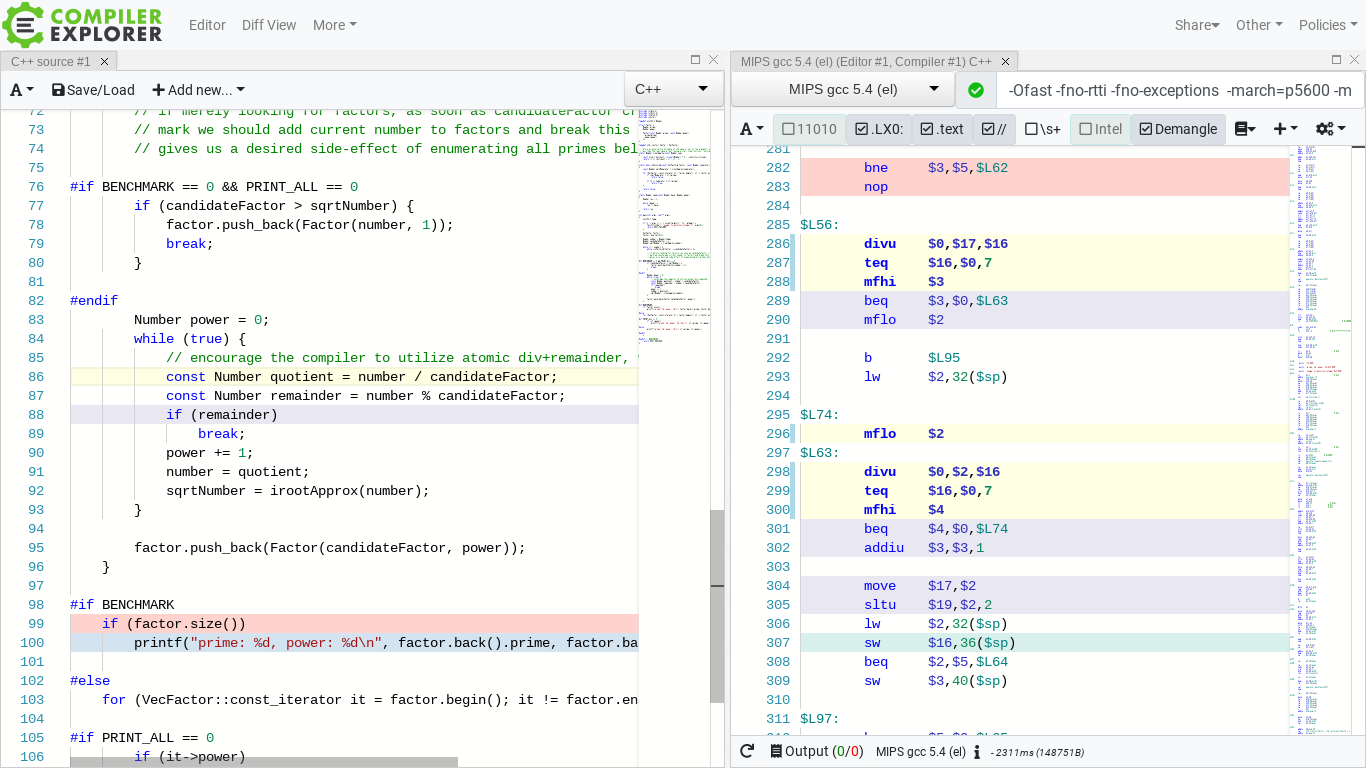
This time our peeled loop spans from label .L57 to the branch on line 310, and most importantly does 1x div per iterations yay. The fact there’s a redundant movement of data between regs $eax and $ecx (lines 303 305) should not bother us, as it’s benign, code density aside. Here is how the same loop looks on the mips32r5 label $L74 through line 302:
OK, with that bumpy detour behind us, how did the different (μ)architectures perform in the improvised benchmark mode of our factorizer, finding all primes up to, say, the 1,000,000th one? Note, that for this particular task the codegen issue with power defactorization would not matter at all it could (marginally) affect only composites, and we’re doing a prime here.
One thing went exactly as expected in the tests, as it had no chance of turning differently armv7l absolutely floundered at the benchmark, due to its lack of an integral div op. Its times were, well, bad think 6x-8x the times of arm64 target. So I see no point in discussing armv7l through the rest of this writing. How did things go among the rest of ISAs?
|
μArchitecture |
Giga-cycles till the 1,000,000th prime |
| Xeon E5-2687W (SNB) |
8.90 |
| Xeon E3-1270v2 (IVB) |
8.34 |
| Core i7-4770 (HSW) |
8.25 |
|
Marvell ARMADA 8040 (CA72) |
5.64 |
|
Baikal-T1 (MIPS P5600) |
9.04 (8.98 with SoA benchmark version) |
Notice the odd one? CA72, featuring an ISA devoid of a dedicated integral modulo instruction, stood well ahead of all the other atomic div+remainder ISAs. Technically, it takes two ops on arm64 to compute a remainder a div + a multiply-sub, with a full-force data dependency between them. And yet, it stands in a league of its own on this task. Why is that?
The answer is brutally trivial while still low-throughput, high-latency, integral division on the CA72 is much better latency-wise than its counterparts on any of the x86 participants. Actually, it’s so much better that even when paired with a data-dependent multiply-sub, it’s still much faster (x86 timings courtesy of Agner Fog’s x86 instruction tables):
|
μArchitecture |
udiv r32, reciprocal throughout, cycles |
udiv r32, latency, cycles |
| SNB |
11-18 |
20-28 |
| IVB |
11 |
19-27 |
| HSW |
9-11 |
22-29 |
|
CA72 |
&l;p align="left">4-12 |
4-12 |
To put things into perspective, it would take just a 2.67GHz CA72 to match the 3.9GHz HWS on this test.
Another thing that surprised me was the behavior of the MIPS p5600 while on the very first tests I ran on it, using shorter sequences (smaller primes for factorization) but more divisions it did notably better than the SNB, its performance seem to be greatly affected by data spilling out of L1D, so on the final test it did more-or-less on par with the SNB. A memory subsystem latency investigation is in order, but that will happen on a better day.
As this tale got too lengthy I’ll end it here. The moral of the story for me was that even ten lines of the most prosaic of code can hold a fair number of surprises. All code and test runs can be found at http://github.com/blu/euclid

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.



It’s interesting to see how you ended up modifying your “while” loop and avoid peeling at the same time, because each time I start to optimize such loops, I end up with a “do while” or “while(1)” and the break in the middle of it as well. Most of the time you need to help the compiler compute several elements at once at the beginning of the loop, instead of stopping on the first one resulting in such elements being spread around the beginning and the end of the loop.
I also noticed that the A72 has a high throughput on divisions and more surprisingly, the A53 is even faster. I also concluded about lower latency due to a shorter pipeline. In some tests, I found something around 6 cycles average on A72 for a given test vs 4 on A53 for the same test, which makes the A53 appealing for certain types of operation where in-order doesn’t matter. Typically you’ll have a single div unit on most CPUs, so if you need to factor numbers, picking the lowest latency in-order one with high frequency, low power and high core count an be interesting.
Good observation about A53’s short pipeline advantages! I suspected that might be the case on it re div, but I did not get to actually test arm64-target code on it, due to a happenstance of software limitations I’ve got across my chromebooks here, and the fact I’ve mostly decommissioned my ubuntu tablet. Regardless, this is a major omission on my part, and a hole in this article.
BTW, another similar example where an A53 outperforms A57/A72 in latency are the neon permute instructions tbl/tblx, which we’ve discussed here on cnxsoft.
Small correction: the atomic div+remainder in mips is valid through mips32r5, but is deprecated in mips32r6 in favor of separate div and mod instructions, which output to a dst register, rather than to lo/hi.