
SSDs may eventually replace HDDs, but the latter still have many years of life, as they come with higher capacity, and much lower price per gigabyte. But as capacity increases, performance also needs to increase, and new technologies are being developed.
Seagate is currently working on two technologies for their next generation hard drives: HAMR (Heat-Assisted Magnetic Recording) to increase data density, and hence allow for larger capacity drives, and multi-actuator technology that uses several actuators (currently just two) on the drives to improve IOPS per GB, i.e. random I/O performance.
HAMR is said to “use a new kind of media coating on each disk that allows data bits, or grains, to become smaller and more densely packed than ever, while remaining magnetically stable. A small laser diode attached to each recording head heats a tiny spot on the disk, which enables the recording head to flip the magnetic polarity of each very stable bit, enabling data to be written.”
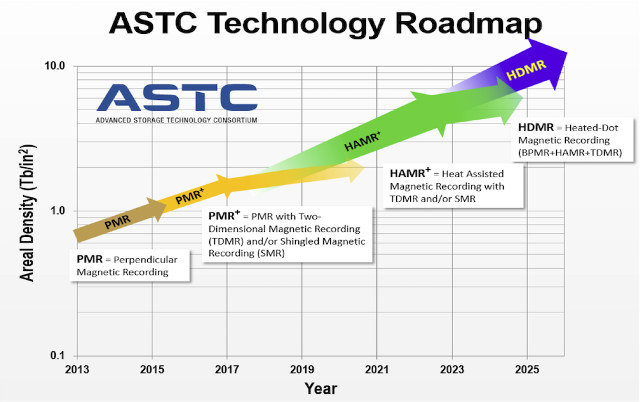
Seagate has already built over 40,000 HAMR drives, and volume shipments of 20TB+ drives are expected in 2019. The new technology is transparent to the host computer, so the same code can be used, and projected cost per TB path beats current PMR technology. Based on the chart from ASTC (Advanced Storage Technology Consortium), HDMR (Heated-Do Magnetic Recording) will then displace HAMR around 2025 providing even greater density and capacity (100 TB drives anyone?).
 Higher densities may negatively impact random I/O performance (in terms of IOPS per TB), and larger capacity hard drives are normally used in datacenter where applications, such as artificial intelligence or IoT, require lots of data, and are sensitive to random I/O performance. So Seagate is currently working on multi actuator technology, where there’s not only a single actuator (component that moves the hard drive’s heads to read and write data), but two independent actuators – for now – operating on a single pivot point, potentially doubling the IOPS (input/output operations per second) performance of the drive.
Higher densities may negatively impact random I/O performance (in terms of IOPS per TB), and larger capacity hard drives are normally used in datacenter where applications, such as artificial intelligence or IoT, require lots of data, and are sensitive to random I/O performance. So Seagate is currently working on multi actuator technology, where there’s not only a single actuator (component that moves the hard drive’s heads to read and write data), but two independent actuators – for now – operating on a single pivot point, potentially doubling the IOPS (input/output operations per second) performance of the drive.
The host computer can treat a single dual Actuator drive as if it were two separate drives, meaning it can request two different data requests simultaneously in order to offer better performance.
While HAMR drives can already produced in small quantities, Seagate did not provide a roadmap for the implementation of dual / multi actuator technology. Nevertheless, we should expect HAMR multi actuator drives for the enterprise in a few years, and potentially for the consumer market a little later.
Via Liliputing and Tom’s hardware.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.


Spinning metal storage drives aren’t going to compete with solid state drives for random I/O. They should stop putting so much effort into that. What they need to address is sequential read and write speeds so that these huge drives can at least be read and written fast enough for their RAID group to have a non-zero MTBF.
As aerial density increases, conventional drives only improve sequential read/write speeds at the square root of density. That means it takes longer and longer to read a drive. That leads to a point where a drive spends its whole life rebuilding the array it’s part of and very little of its life actually doing work. If spinning drives are to have a place in the future of storage, they need to address that problem.
If these two head groups can read/write at once, then we might have something useful–but not the random performance.
@willmore
Since I was a kid I was complaining with my ST225 (20 MB) hard drive having a single actuator when the mechaniscs was very easy to replicate. Later we started to see the newer voice coil actuated drives, with much smaller motors and I thought that instead of having a single actuator, they could place one per corner and have 4 set of heads to allow parallel I/Os to work fine. This is magnified in video recording+reading where that can easily save the heads from having to go back and forth. The proposed design above is far from being optimal since certain heads are on an actuator and others on another one, so I guess that they’ll cut the time in half for half of the requests overall, resulting in something around 25% gains. It will not even allow RAID rebuild to work in parallel with normal operations.
Regarding the time taken to read a full disk, it’s becoming unmanageable. My 20 MB hard drive used to transfer at 240 kB/s, resulting in 2 minutes to read the whole drive. Now at 100 MB/s, a 4 TB disk requires half a day to be full read. That’s not acceptable anymore for backups.
Remember an old hard disk made by Conner Chinook ?
https://commons.wikimedia.org/wiki/File:Conner_Peripherals_%22Chinook%22_dual-actuator_drive.jpg
@willmore
I’m guessing the solution improves both sequential speed and IOPS, but Seagate talks a lot about IOPS in their blog.
The drives are mostly for datacenters, and according to Seagate, they need good performance in terms of IOPS per TB. So the plan is to get cheap and large storage with usable performance.
@willmore
A quick look through these slides could be interesting: https://www.usenix.org/node/194391
It is all about getting the most from the investment in already developed standards.
Speaking about hard drives I recent read.
Toshiba is sampling a new generation of 10,500rpm enterprise performance hard disk drives for mission-critical servers and storage. The series has a 2,400GB capacity model. Built to deliver superior low-latency performance, the AL15SE Series supports 12Gbit/s[2] SAS dual-port interface to optimize the host transfer rate.
All models utilize a space-efficient, power-saving 2.5 inch, 15mm form-factor. Advanced format models support 4K native and 512e emulated sector technologies, increase areal density in capacities from 600GB to 2,400GB and feature a 15 percent increase in sustained transfer rate over the prior AL14SE generation. New 512n sector technology models increase areal density in capacities ranging from 300GB to 1,200GB. Source electronics weekly.
Also Western Digital Company to Transition Consumption of Over One Billion Cores Per Year to RISC-V to Drive Momentum of Open Source Processors for Data Center and Edge Computing.
Well, that’s one of the reasons backup filers use RAID and at least 10 GbE to increase restore and desaster recovery performance by 4-5 times. But you’re right and classical backup requiring full restores is dead and here around we moved to full sync systems almost a decade ago. So if the storage array on the main server died the whole server will be replaced by the backup server that provides everything settings included (making use of ZFS features like snapshots and send/receive functionality to transport changes from here to there).
With appropriate drive firmwares an increase in count of actuators should also allow to increase sequential throughput, right?
Mechanical drives are dead…they just don’t know it yet. This year the five year TCO of flash has crossed over and is now less than that of spinners
@Occam
Yeah, I suppose tape died a decade ago….WRONG!!!!
Just because you don’t use it doesn’t mean it’s dead – tape is still big business because it still has, by far, the lowest cost per bit.
Tape died here… Replaced by Amazon Glacier @ $O.OO5/GB. The only tape cheaper is Scotch tape ;-). No extra cost for off-site storage, No tape drive/loader failures, no tape grooming and refresh, etc,etc,etc.
@Occam
Handy for people wanting their data available to the deep state establishment.
Tinfoil hats and 256-bit AES encryption is good enough for us. You’re more likely be hacked by stupid employee falling victim to phishing or some other social attack. I don’t think the NSA is interested in my data. We use a Veeam backup server then from the Veeam server to Glacier. Gives us fast restore from most likely data losses, users deleting files followed by crashes or hardware failure.
Glacier us for archive and protection from ‘the building burning down’. Tape is dead.
@willy
Ever heard of incremental backups? You don’t need to backup all the data over and over again.
@Jerry
I would assume @willy is focussing on what’s important when talking about backup: The ability to restore and do desaster recovery in an acceptable time frame (at least that’s how I define a ‘working backup’: a tested restore that finished without problems within the amount of time allowed). And yeah, 100MB/s would be a joke and that’s why no one right in his mind relies on such slow implementations 🙂
Probably not Nsa, but you can be sure that every byte of data you store outside your company is “data-mined” for consumer and advertising patterns.
And if this also does not worry you, what about if those scanned patterns, by some “mistake”, end up in the wrong hands?
How did you miss the ‘Tinfoil hats and 256-bit AES encryption is good enough for us’ introductory sentence?
yeah, right, good enough, just like in electronic voting machines…
@JotaMG
Nice! You had the choice between a tinfoil hat and 256-bit AES encryption and chose the former. Why exactly?
Anyway, to combine your hat with strong encryption: When you do ‘Cloud backup’ with your iOS device then strong encryption is applied but not you but Apple (and the NSA of course) own the keys to your encrypted data. When you do ‘Cloud backup’ with your Android device it’s the same but Apple being replaced by Google (but still the NSA having access to your data if they want).
When you apply encryption on your own and under your control and keep the keys to yourself (that’s what @Occam is talking about) then Apple and Google are kept out and only the NSA has access to your data any more (due to master keys and backdoors in cryptographic implementations). Wait, most probably it’s not only the NSA but if you don’t use Intel (AES-NI proudly backdoored by the NSA) but ARMv8 instead then it’s UK’s GCHQ who has access (assuming the backdoors in ARMv8 crypto extensions are made by them).
So this should address your concerns already, right? The large corporations can’t do data mining any more with your encrypted data lying somewhere in the cloud?
Free tip O’Day. If you are looking for a superior home/small businesses backup system check out Cloudberry Backup. I’ve tried all the name brands in IMHO it’s the best. The Windows version checks nearly all the boxes.
As I previously posted AI broke the Enigma machine in under 12 minutes and Mathematicians have stated many encryptions have mathematical back doors. The tinfoil hats belong to the people peddling myths that because only you have the encryption key, you are safe.
Exactly. “yes boss I’m hurrying, the disk will be ready tomorrow, invite everyone to play cards” hardly is a good response anymore when restoring. Even replacing a RAID disk kills the whole unit’s performance for a full day now.
@willy
And that’s why some people have been calling RAID obsolete for years. Given storage prices, error rates, transfer speed, etc it doesn’t make as much sense as it did 20 years ago
@TonyT
There’s no need to rely on those anachronistic RAID concepts any more (except maybe for ‘cold data’ like archive storage when you implement redundancy only within a server/rack and not ‘cloud like’ accross a data center or even multiple data centers spread across the world).
These days we can make use of ZFS and while I consider RAID-Z/Z2/Z3 a far better alternative to classical RAID what we usually implement today is a bunch of zmirrors in one large zpool for three reasons (a web search for ‘ZFS: You should use mirror vdevs, not RAIDZ’ is sufficient to get a more verbose explanation on advantages/differences):
– awesome high random IO performance (only works with ‘one large zpool’)
– no trashed array performance and no disk stress when a disk has to be replaced
– easy to expand capacity when needed
But even with nice NAS disks (usually Seagate Enterprise Capacity SAS drives eg. ST4000NM0025 or ST6000NM0034) who show +200 MB sequential performance accross most of the surface with local array benchmark scores of +1000 MB/s or +600 MB/s through a 10GbE network such tasks like backup/restore are pretty limited in performance. Everything that happens at the filesystem layer gets slow as hell anyway as soon as a lot of smaller files are involved but even when sending ZFS snapshots between filers with optimised settings average transfer speeds stay mostly below 300 MB/s. And at this rate transferring a medium sized array of 50TB still needs two full days 🙁