
Bzip2 is still one of the most commonly used compression tools in Linux, but it only works with a single thread, and I’ve been made aware that lbzip2 allows multi-threaded bzip2 compressions which should lead to much better performance on multi-core systems.
lbzip2 was not installed by default in my Ubuntu 16.04 machine, but it’s easy enough to install:
|
1 |
sudo apt install lbzip2 |
I have cloned mainline linux repository on my machine, so let’s see how long it takes to compress the directory with bzip2 (one core compression):
|
1 2 3 4 5 |
time tar cjf linux.tar.bz2 linux real 9m22.131s user 7m42.712s sys 0m19.280s |
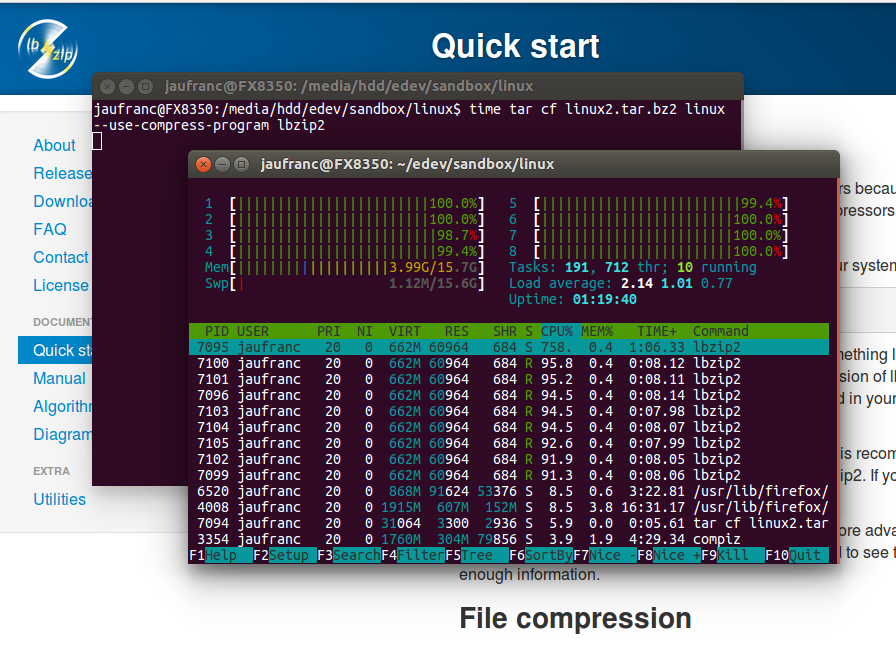
9 minutes and 22 seconds. Now let’s repeat the test with lbzip2 using all 8 cores from my AMD FX8350 processor:
|
1 2 3 4 5 |
time tar cf linux2.tar.bz2 linux --use-compress-program=lbzip2 real 2m32.660s user 7m4.072s sys 0m17.824s |
2 minutes 32 seconds. Almost 4x times, not bad at all. It’s not 8 times faster because you have to take into account I/Os, and at the beginning the system is scanning the drive, using all 8-core but not all full throttle. The files were also stored in a hard drive, so I’d assume the performance difference should be even more noticeable from an SSD.
We can see both files are about the same size as they should be:
|
1 2 3 4 5 |
ls -l total 4377472 drwxrwxr-x 25 jaufranc jaufranc 4096 Dec 12 21:13 linux -rw-rw-r-- 1 jaufranc jaufranc 2241648426 Dec 16 10:17 linux2.tar.bz2 -rw-rw-r-- 1 jaufranc jaufranc 2240858174 Dec 15 20:50 linux.tar.bz2 |
I’m not exactly sure why there’s about 771 KB difference as both tools offer the same compression.
That was for compression. What about decompression? I’ll decompress the lbzip2 compressed file with bzip2 first:
|
1 2 3 4 5 |
time tar xf linux2.tar.bz2 -C linux-bzip2 real 2m49.671s user 2m46.500s sys 0m13.068s |
2 minutes and 49 seconds. Now let’s decompress the bzip2 compressed file with lbzip2:
|
1 2 3 4 5 |
time tar xf linux.tar.bz2 --use-compress-program=lbzip2 -C linux-lbzip2 real 0m45.081s user 3m14.732s sys 0m10.088s |
45 seconds! Again the performance difference is massive.
If you want tar to always use lbzip2 instead of bzip2, you could create an alias:
|
1 |
alias tar='tar --use-compress-program=lbzip2' |
Please note that this will cause a conflict (“Conflicting compression options”) when you try to compress files using -j /–bzip2 or -J, –xz options, so instead of tar, you may want to create another alias, for example tarfast.
lbzip2 is not the only tool to support multi-threaded bzip2 compression, as pbzip2 is another implementation. However, one report indicates that lbzip2 may be twice as fast as pbzip2 to compress files (decompression speed is about the same), which may be significant if you have a backup script…
tkaiser also tested various compression algorithms (gzip, pbzip2, lz4, pigz) for a backup script for Orange Pi boards running armbian, and measured overall performance piping his eMMC through the different compressors to /dev/null:
|
1 2 3 4 5 |
gzip -c: 10.4 MB/s 1065 MB pbzip2 -1 -c: 15.2 MB/s 1033 MB lz4 - -z -c -9 -B4: 18.0 MB/s 1276 MB pigz -c: 25.2 MB/s 1044 MB pigz --zip -c: 25.2 MB/s 1044 MB |
pigz looks the best solution here (25.2 MB/s) compared to pbzip2 (15.2 MB/s). lbzip2 has not been tested, and could offer an improvement over pigz both in terms of speed and compression based on the previous report, albeit actual results may vary depending on the CPU used.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.


Xz is more and more the most used one those days (used at least by archlinux fo its packages, i believe deb had changed or had plan to. Most source distribution has bz2 and xz version now). Compress far better uncompress faster. But use lot of memory and can really be slower both depending on compression level. At level 3 it has compression size and speed similar to bz2. It can be multithreaded too qince version 5.1 or 5.2 I forgot this point. But in the case of xz, multithreading also mean a bit less efficient compression.
Thanks zoobab for the tip 🙂
No seriously the problem is deeper, most programs (python, nodejs, etc…) don’t handle multiple cores very well, because programming in parrallel is way harder. Some people manage to achieve much better performance by using messaging within their application, for example by using zeromq IPC. I remember someone from BeOS said they had multicore support by default in their C library. Welcome to 2017!
Good reminder. I think there’s a whole army of parallelized decompression programs. I swear I’ve seen others.
I’ve done some basic benchmarking on this before for improving file transfer rates when copying a large amount of data. Pigz always appeared to come out the best for compression with low memory usage although decompression was still single threaded for some reason. Not that it mattered too much as this was all done concurrently through piping the compressed output through and SSH tunnel and decompressing on the destination at the same time.
@Rob
Agree on pigz, what’s especially nice with it when the target platform is OS X that you can create ZIP archives too (pigz –zip -c) that are able to be decompressed on OS X with the internal decompressor (using OpenCL and GPU cores and being many times faster than usual CPU bound decompressors!)
Another important criteria (at least for me) is whether the tools act multithreaded when fed via stdin (not all do!) and since it’s almost 2017 we all should have a look at zstd/Zstandard and don’t rely too much on tools developed 20 years ago 😉
https://code.facebook.com/posts/1658392934479273/smaller-and-faster-data-compression-with-zstandard/
@tkaiser
On the same topic, elliptic-curve based encryption defeats all the other algos CPU-wise. I wanted to do a comparison of VPN throughput with the same hardware, but it got lost in the meantime. At some point, curvetun was able to achieve encrypted gigabit speeds while openvpn unencrypted was stuck at 150mbps.
This is generic Linux stuff, and BTW not mentioning pixz is a big omission.
@tkaiser just run some quick benchmarks on a Centos 6 64-bit VM with 4 vCPU, 8GB RAM, with a ~5GB uncompressed database backup chunk ….
gzip 5GB to 2.1GB Comp = 3m 1s / Decomp = 1m 24s
pigz 5GB to 2.1GB Comp = 1m 4s / Decomp = 52s
zstd 5GB to 1.95GB Comp = 1m 1s / Decomp = 34s
So points to note here are that;
1) zstd compresses slightly better than zlib
2) Both gzip and zstd are running single threaded
3) pigz is running multi-threaded (on 4 cores) and is roughly the same comp time as single threaded zstd!
4) Decompression time is also improved with zstd
This is impressive and it looks as though they will be bringing multi-threaded support, akin to pigz, in future releases. I will be very interested in how much more the times can be reduced then.
Instead of making an alias (which doesn’t work for any scripts), you can put symlinks in /usr/local/bin:
cd /usr/local/bin
ln -s /usr/bin/lbzip2 bzip2
ln -s /usr/bin/lbzip2 bunzip2
ln -s /usr/bin/lbzip2 bzcat
ln -s /usr/bin/pigz gzip
ln -s /usr/bin/pigz gunzip
ln -s /usr/bin/pigz gzcat
ln -s /usr/bin/pigz zcat
Now if you have /usr/local/bin in your PATH before /bin or /usr/bin, the parallel programs will be called instead of the old ones.
@GanjaBear
While this might be ‘generic Linux’ it’s especially important to know such stuff when dealing with weak multi-core embedded systems. Applies also to eg. Intel Avoton servers (4 or 8 cores but per-core performance not that high).
Imagine you have to sync a lot of data with eg. rsync (single-threaded by design). On an octa-core machine the following might be 10 times faster compared to the ‘usual approach’ since parallelism and using a weaker cipher:
And now imagine patching rsync to not rely on horribly outdated zlib stuff from last century but to use zstd instead 🙂
I know, I’ve been compressing my stuff on a quad core system with a wrapper one-line script:
$ cat ~/bin/tarx
tar cvf “$@” -I pixz
@Rob
The reasons why it’s like this are explained in detail in the aforementioned post. TL;DR: We prefer to use tools/concepts that were developed decades ago and simply do not match with today’s technical reality and are now horribly inefficient (100% CPU utilization while running brain-dead code).
While zstd comes with reasonable defaults you’re also able to tune everything and even ‘train’ the tool for specific data patterns (dictionary compression resulting in 2-5 times better results with specific data types).
And zstd running single-threaded can be an advantage (3 cores free to do encryption on a quad-core system if you’ve to send a compressed data stream through a VPN for example) or a little challenge: A common use case is ‘device backup’ so simply split the whole device in ${THREADS}*16 chunks, process them in random order (dd feeds zstd) and end up with 64 chunks later on a quad-core system (backup-00.zst — backup-63.zst). Since the .zst format can be concatenated it’s then just the following to restore such a backup/clone:
Does Linux parallelize internally for bzimage / initramfs?
@Galileo
I would better have a look in other areas where the kernel (or ‘drivers’) do the job. It’s almost 2017 and people still use filesystems that origin back to +25 years ago. We have both btrfs and ZFS available and by using their features so many tasks get easier. Both fs do not only provide end-to-end data integrity (checksumming), overcome stupid partition / volume manager restrictions but also provide transparent file compression and deduplication features.
Imagine the ‘make a SD card backup once a month use case’. You could stop your SBC, eject the 16 GB SD card and do a device clone on your host computer (piping dd output through bzip2 or gzip since you did this already 10 years ago this way). Given the SD card is filled with 20 percent you’ll end up with a backup file 1 GB in size each time.
Using lbzip2 (lame compared to zstd by the way) most probably won’t help that much here since IO will be the bottleneck. Same when using btrfs/ZFS with transparent file compression (runs multithreaded) but by adopting modern fs and their features we could now make use of deduplication and reduce the amount of disk space needed to store those images by magnitudes.
Given you create a btrfs fs with compress-force=zlib you would simply use ddrescue to write an uncompressed image on this fs. Compression happens inside the filesystem and the result looks like a 16 GB image while it consumes just ~1 GB on disk. When you repeat this next month you already know that there has not that much changed on the SD card. With the traditional method you would now create another 1 GB large compressed device image.
By acting smart (it’s almost 2017!) it’s now just
The –reflink does the trick. This way the copied new.img shares all blocks on disk with old.img (disk space needed: Just a few KB metadata at this stage). When ddrescue now creates the new image all the compression stuff happens transparently inside the fs driver and only those blocks that have really changed will be added on disk. So you end up with 2 large 16 GB file in size when looking at externally that consume just 1 GB on disk (old.img) + a few MB for new.img (the changed blocks in compressed format).
The whole process will be somewhat CPU intensive (since compression happens even if no new data will be stored on disk if blocks haven’t changed) but you get huge savings in space just by stopping to use anachronistic methods/tools/filesystems. It’s almost stupid to do things in userspace when kernel drivers can do the job much better.
Another interesting read on this topic: https://lyncd.com/2015/09/lossless-compression-innovation/
Just to state the benchmarks I provided above were for zstd v1.0.0. I have since found there have been a few releases after that and they are now on v1.1.2. Someone also created a multi-threaded version pzstd at v1.1.0 however I can’t get it to compile on Centos 6 despite using a gcc 4.8 c++ dev env as it comes up with syntax errors.
@Rob
Hmm… Zstandard development happens completely in the open: https://github.com/facebook/zstd/releases/tag/v1.1.2
I ran yesterday some benchmarks on OS X (there it’s a simple ‘brew install zstd’) but won’t provide numbers since all other compressors are simply soooooo lame compared to zstd. BTW:
It’s literally minutes vs. seconds (at least when talking about pixz vs. pzstd) but unfortunately unlike Apple’s rather similar LZFSE which is already optimized to run on ARM devices (iGadgets) there’s still (a lot of) work to do get Zstandard working on ARM. Tried it just on aarch64 though…
And Zstd seems to have patents:
https://github.com/facebook/zstd/blob/dev/PATENTS
I just made a quick test, zstd compression still uses one core 🙁
@Benjamin HENRION
If you want more than one core used why not using pzstd instead? Though parallelizing the jobs first and then letting zstd do the job is way more efficient 🙂
Regarding ‘seems to have patents’ better read through their github issue #335
I’ve repeated the test in the post with zstd (pzstd is only enabled for Windows, and has been disabled for gcc in appveyor.yml
):
1. Installation:
2. Compression:
3. Size comparison:
4. Decompression:
Update.. Clearing the cache first, gives more realistic numbers (e.g less fast than my HDD max write speed…):
Very impressive considering I’m using the single thread version.
(Xenial stock) zstd on single, not even fully utilized core, makes just a little worse than lbzip2 on huge core count and full power waste.
real 0m24.371s
user 0m16.736s
sys 0m8.604s
lbzip2 on 28C/56T and full utilization
real 0m19.171s
user 13m59.196s
sys 0m14.032s
OK I’ve switched to a CentOS 7 instance which means I can install the zstd rpm from the EPEL repo which is v1.1.1 and has pzstd included with some pretty impressive results;
gzip 5GB to 2.1GB Comp = 3m 6s / Decomp = 1m 18s
pigz 5GB to 2.1GB Comp = 47s / Decomp = 30s (4 Cores)
zstd 5GB to 1.95GB Comp = 58s / Decomp = 27s
pzstd 5GB to 1.96GB Comp = 15s / Decomp = 10s (4 Cores)
Wow, just wow! Now off to see how this improves file transfers.
No idea what I did wrong but zstd runs just fine on aarch64 (pzstd seems to throw segfaults). This is Pine64 running 4.9, Armbian/Xenial with a fixed cpufreq of 816 MHz (important to ensure no throttling happens). I simply compress /usr which involves some IO bottleneck since I run off an el cheapo SD card:
I chose a differing compression ratio for zstd since the default (-3) produces slightly larger results. With -5 I get an archive size and compression time similar to lbzip2. But here the more interesting part, the output from ‘iostat 120’ running in a separate terminal (zstd first, lbzip2 below):
So zstd got way more bottlenecked by slow IO than lbzip2 while not even maxing out one CPU core. This is important since while producing similar results zstd wastes way less CPU ressources and energy. On systems that are prone to overheating one expected result is also that zstd running single-threaded will even more outperform lbzip2 since the latter heating up all CPU cores will end with throttling slowing further down 🙂
Ouch, I was comparing apples with oranges:
Current version is 1.1.2 while Xenial/arm64 repo still uses 0.5.1.
Small update: upgrading to 1.1.2 doesn’t change anything on ARM but eliminating the IO bottleneck does (using good old friend mbuffer):
So by using mbuffer (the first occurence one is the really important one) and increasing compression level from 5 to 7 we can beat lbzip2 regarding archive size while taking the same time but only running on a single core and therefore saving way more energy/resources.
BTW: When sending (compressed) data streams through the network mbuffer is also of great use 🙂
Inspired by this post (or let’s better say ‘comment thread’) I tried out to improve a data sync solution for one customer (connecting Europe and Asia — high latency is a problem here). They currently use Riverbed WAN accelerators on both ends of their VPN but by switching to zstd + mbuffer + rsync/SSH data gets transmitted almost 4 times faster (on Solaris a simple ‘pkgutil -i zstd’ provides version 1.1.0 currently).
Impressive so far. I got best results by using half of the physical CPU core count to set up some parallelism but then run single-threaded zstd. And due to the minimal processor requirements we could now think about using a similar setup with homeworkers (a simple GbE equipped H3/H5 board with some USB/UAS storage can already do the job since fast enough for LAN use and sending/receiving btrfs snapshots piped through zstd due to typical ADSL bandwidth)
Last ARM related comment: at the same CPU clockspeed both lbzip2 and zstd when running on aarch (A64 or H5) are approx. 1.5 times faster than armhf (H3 in this case). So an inexpensive GbE equipped OPi PC 2 is the perfect choice for such a ‘homeworker server emulation’ combined with some good USB storage (UAS + btrfs or ZFS + compression).
Funnily almost everything needed for that is already available for H5 (Orange Pi PC 2):
– u-boot: https://github.com/apritzel/u-boot/commits/h5
– kernel: https://github.com/apritzel/linux/commits/sunxi64-4.9-testing
– DVFS patches: https://github.com/megous/linux/commits/orange-pi-4.9
The mainline kernel patches for SY8106a equipped H3 boards work with OPi PC 2 too! So unlike A64 which is limited to 816 MHz currently due to missing PMIC/DVFS support in mainline kernel H5 can already run with up to 1152 MHz with 4.9.
@tkaiser
Never heard about mbuffer, so here’s a link: http://www.maier-komor.de/mbuffer.html
It’s been around since 2001, and looks like a readahead program. I thought the OS would do this automatically, but apparently not.
@cnxsoft
While mbuffer’s advantages are obvious when dealing with tape drives or sending data streams through the network (be it slow DSL or even 10GbE) I always find it surprising that by simply adding one or more mbuffer instances to a pipe overall throughput increases (even without adjusting block and buffer sizes).
I have to admit that I missed the -I and -O options to send data through the network for a long time (we used https://sourceforge.net/projects/hpnssh/ to get strong authentication without wasting CPU resources for encryption in local networks) but will now update customer workflows since less hassles and better performance.