
Artificial intelligence is handled at different levels in the ecosystem with ultra-powerful systems in the cloud equipped with dedicated hardware such as FPGA or GPU cards, while on the other side of the spectrum we have Arm or RISC-V based processor with AI accelerator for low power systems like smartphones or battery-powered smart cameras.
Centaur Technology aims to provide a solution catering to the middle segment of devices that don’t need ultra-low power consumption, nor the highest possible peak performance, but still require a relatively compact form factor and low costs.
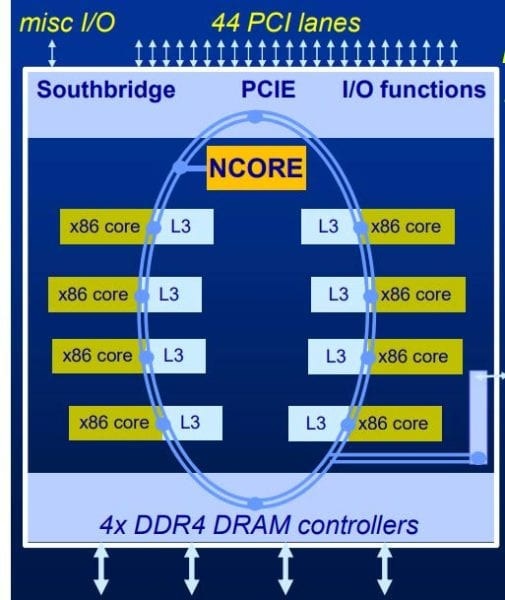
Their solution is a still-unnamed octa-core x86 processor featuring Centaur NCORE AI coprocessor. SoC with built-in NPU (Neural-network Processing Unit) is pretty common in the Arm and RISC-V world, but it’s apparently a world’s first in the x86 space since existing solutions are all based on external accelerators.
Key features of the Centaur x86 AI processor:
- x86 microprocessor with high instructions/clock (IPC)
- Microarchitecture designed for server-class applications with extensions such as AVX-512
- New x86 technology now proven in silicon with 8 CPU cores @ 2.5 GHz (in reference platform) and 16MB L3 caches
- System Memory I/F – 4-channel of DDR4 PC3200 RAM
- AI Coprocessor – NCORE AI accelerator with “32,768-bit very-wide SIMD architecture” delivering 20TOPS and 20 terabytes/second peak performance from dedicated 16MB SRAM
- Expansion – 44x PCIe lanes
- Footprint – 195mm2 in 16nm TSMC
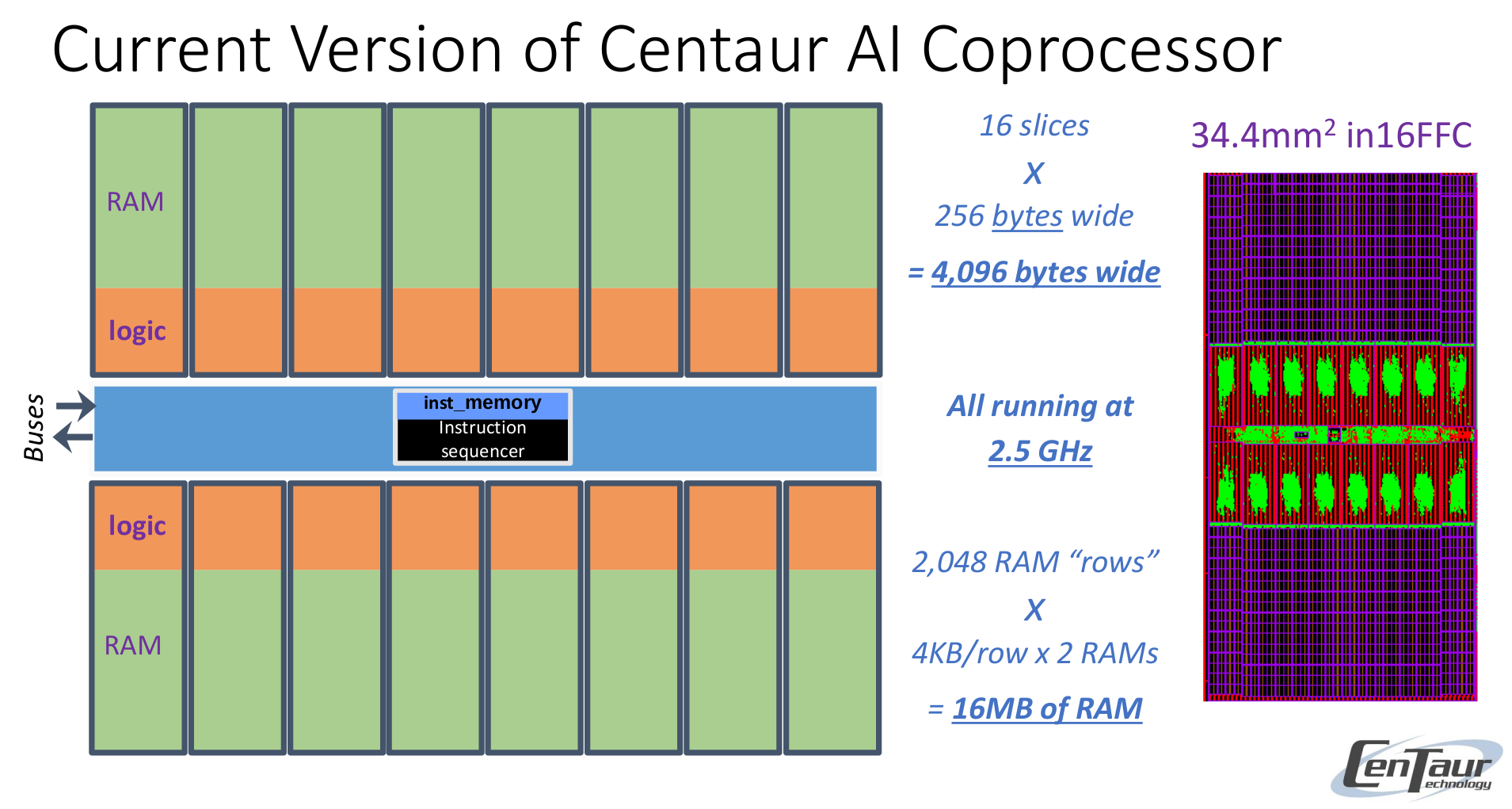
The company notes that an integrated solution is better than external accelerators since those add latency, cost, power, board space, another point of failure.
The processor currently supports TensorFlow Lite with the code running on both the x86 cores and the NCORE AI accelerator. Centaur also plans support for more frameworks including TensorFlow & PyTorch, and the company further explains its roadmap focuses on utilizing MLIR (Machine Learning Intermediate Representation) for both graph-level and code-generation optimizations.
Centaur’s reference system was used to submit official, audited (preview) scores to MLPerf, and showed that Centaur’s AI Coprocessor can classify an image in less than 330 microseconds in MobileNet v1.
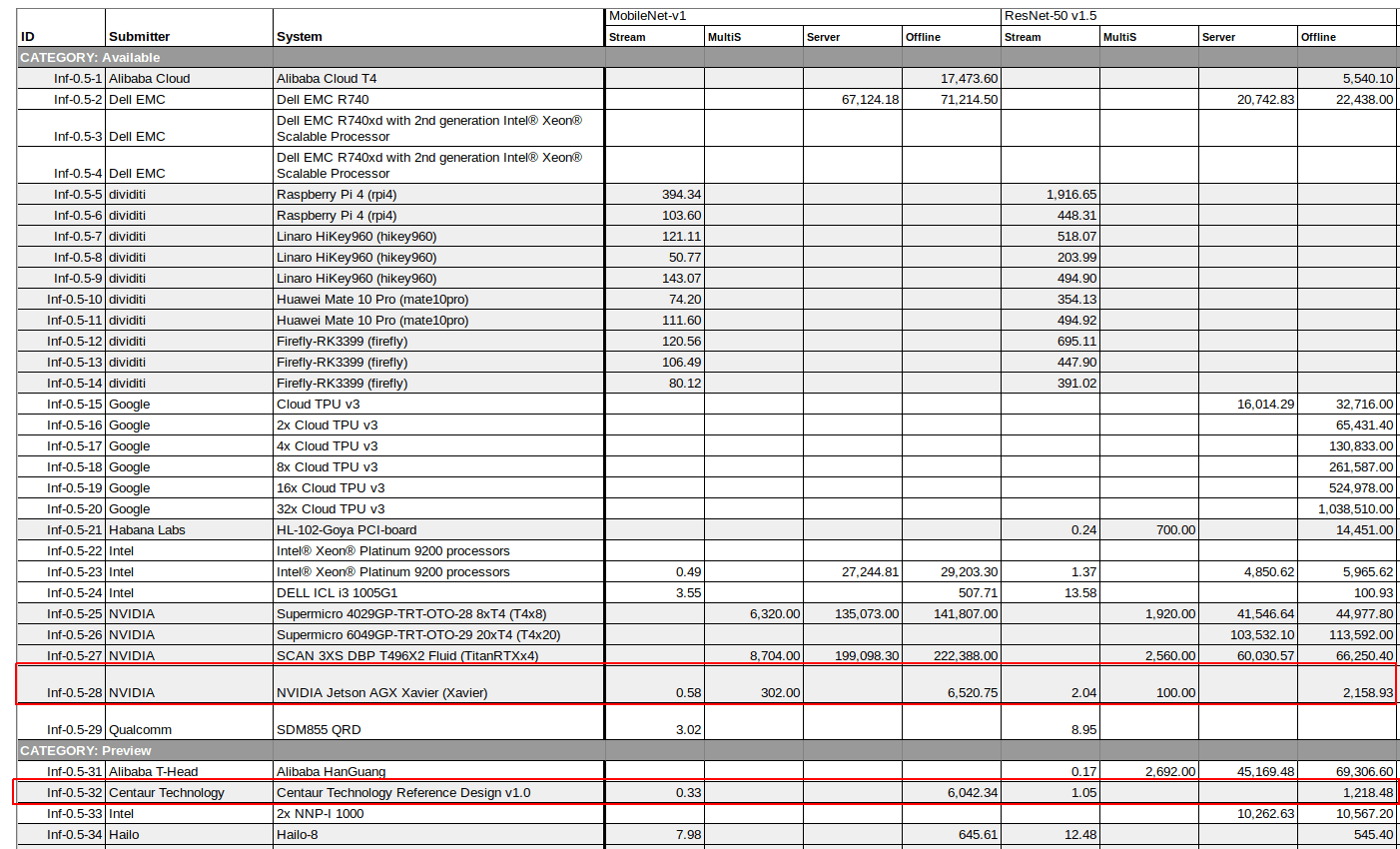
If we look at MLPerf website for results, Centaur x86 AI SoC appears to be in the same class as NVIDIA Jetson AGX Xavier, although the latter is about twice as fast in ResNet-50 v1.5. The Stream columns show the time it takes to render a single Stream in milliseconds (i.e. lower is better), while the Offline columns are expressed in inputs/second (i.e. higher is better).
For comparison, Arm-based systems that are not equipped with AI accelerators (e.g. Raspberry Pi 4, RK3399 SBCs) can render the frame at around 100 ms in MobileNet v1, or about 300 times slower than Centaur solution. On the other side of the spectrum, high-end systems like Google TPU can get a much higher throughput up to one million inputs per second against just over 1,000 for Centaur SoC (The company notes throughput numbers have not been optimized yet, and they eventually expect 1400 fps on RestNet-50 model).
Typical applications for the new processors include on-premises or private data centers for applications using security video, medical images, or other sensitive data, “Edge Analytics Servers” running inference on multiple streams of data such as cameras or IoT sensors.
More details may be found on the product page, and presentation slides.
Thanks to Anonymous for the tip.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



I never heard of Centaur, how did they get a x86 license?
It’s actually VIA.
centaur was once a subsidiary of idt and designed the idt winchip. It got later sold and got bought by via long ago, to replace their other not so successful x86 designs bought from cyrix/nat semi.
Still alive on my home firewall after 10 or so years: $ cat /proc/cpuinfo processor : 0 vendor_id : CentaurHauls cpu family : 6 model : 7 model name : VIA Samuel 2 stepping : 3 cpu MHz : 533.416 cache size : 64 KB fdiv_bug : no hlt_bug : no f00f_bug : no coma_bug : no fpu : yes fpu_exception : yes cpuid level : 1 wp : yes flags : fpu de tsc msr cx8 mtrr pge mmx 3dnow bogomips : 1060.86 12345678910111213141516171819 $ cat /proc/cpuinfo processor : 0vendor_id : CentaurHaulscpu family : 6model : 7model name : VIA Samuel… Read more »
Very interesting. But where can we find the full SoC documentation and where can we buy boards?