
In the pool of 32-bit RISC-V microcontroller cores (E20 by SiFive, VEGA ET1031 by C-DAC), CloudBEAR showcased its 32-bit small and efficient MCU core – BM-310 at RISC-V GLOBAL FORUM 2020. CloudBEAR works on providing services like processor IP customization, support for RISC-V ISA extensions, product integration within a system-on-chip, and configurable instruction and data cache.
Let’s first look into the CloudBEAR processor IP portfolio. It has three different product lines- BM series, BR series, and BI series. First, the BM series targets small and efficient MCUs cores. Second, the BR series targets fast and compact embedded cores. The third and most important BI series is about Linux capable application cores. In this article, we will look into the details of BM-310, which is the RISC-V MCU core for embedded and IoT solutions.
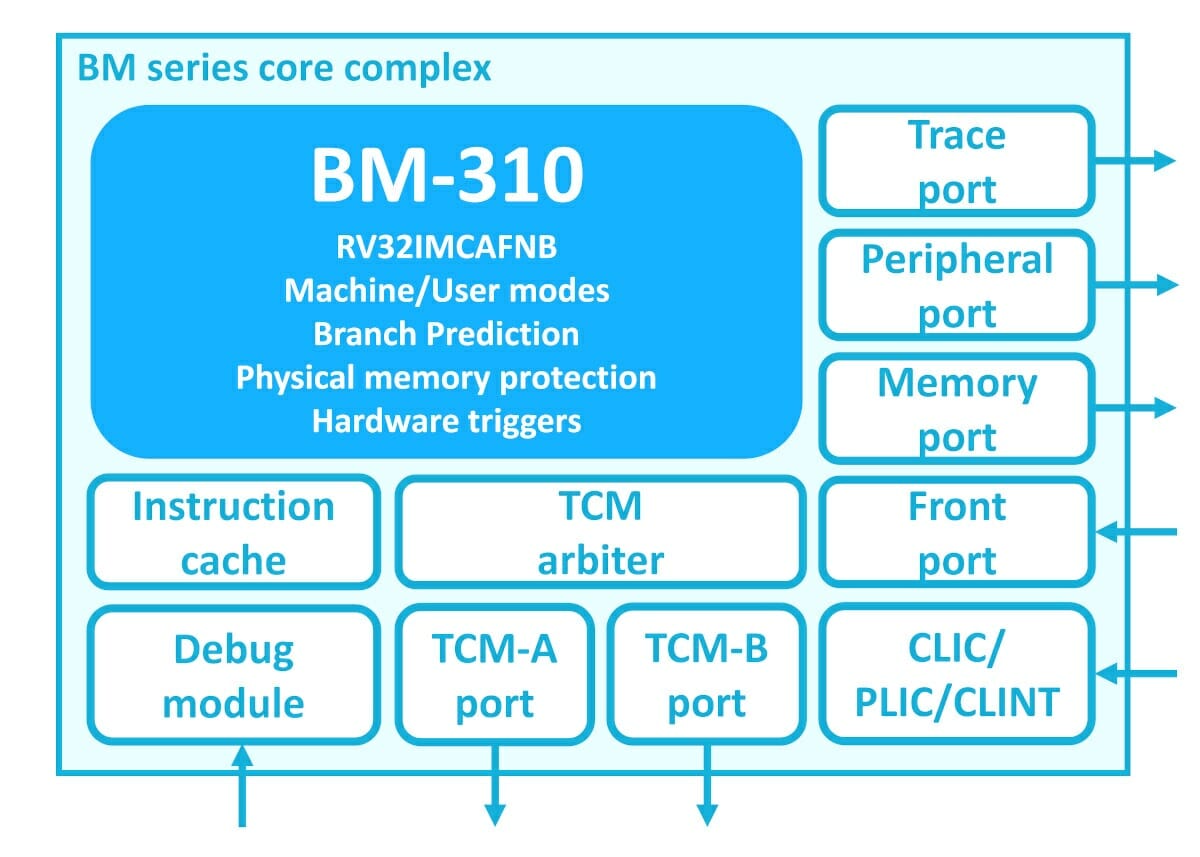
BM-310 Architecture
As RISC-V is a modular instruction set, extensions are optional for the developer. BM-310 architecture (RV32IMCAFNB) includes many ISA extensions. It has RV32I as a base instruction set (32-bit RISC-V with 32 integer registers). The other extensions are integer multiplication and division (RV32M), compressed mode for better code density (RV32C), atomic operation support (RV32A), IEEE 754-2008 compliant single-precision floating-point (RV32F), user-level interrupt support (RV32N), bit manipulation instructions support (RV32B).
Pipeline options

BM-310 has several pipeline options that allow customers to configure their core from a performance-efficiency tradeoff point of view. For the first configuration, it provides maximum efficiency, whereas the fourth configuration provides maximum total performance.

The ideal configuration for use cases requiring a small area, low power, and also low frequency is the first configuration as shown in figure 2. In this configuration, it has a 2-stage pipeline with a zero cycle branch penalty. Hence, an instruction is processed in a clock cycle, which results in no stalls during branch operations in the pipelined processor. This configuration comes with low frequency and maximum efficiency with no branch prediction needed.

Now, if there is a requirement for higher frequency and overall performance, we can select the second configuration (figure 3). In this, there is one branch penalty that means one stall during branch misprediction. So branch prediction becomes necessary to compensate for branch penalty loss.

If there is a further increase in frequency, we select a third configuration (figure 4) that has a 3-stage pipeline. Because of the rise in the frequency, the load to use latency has increased to two cycles.

The fourth configuration (figure 5) becomes ideal to attain the maximum total performance. It has two cycle branch penalties and a two-cycle load to use.
Additional features
It has many additional features like Memory subsystem, power management, interrupt control, security, and multi-core support. Licensing BM-310 involves a simple evaluation process and flexible licensing models. Pipeline option (1) is 19% faster than the reference machine that is Cortex-M4. Developers can develop their application for BM-310 using FreeRTOS, Apache Mynewt, Zephyr Project. Finally, BM-310 has low power and a small area with leading performance in MCU class and makes it best suited for IoT and Embedded applications. Check out the processor’s page for more details.
Acknowledgment: I thank Alexander Kozlov (CTO, CloudBEAR) for his support in providing insights and images.

Abhishek Jadhav is an engineering student, RISC-V Ambassador, freelance tech writer, and leader of the Open Hardware Developer Community.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



The photo made me think this was going to be about a RISC-V ATTiny like chip. 🙁