
Codasip has announced the L31 and L11 low-power embedded RISC-V processor cores optimized for customization of AI/ML IoT edge applications with power and size constraints.
The company further explains the new L31/L11 RISC-V cores can run Google’s TensorFlow Lite for Microcontrollers (TFLite Micro) and can be optimized for specific applications through Codasip Studio RISC-V design tools. As I understand it, this can be done by the customers themselves thanks to a full architecture license as stated by Codasip CTO, Zdenk Pikryl:
Licensing the CodAL description of a RISC-V core gives Codasip customers a full architecture license enabling both the ISA and microarchitecture to be customized. The new L11/31 cores make it even easier to add features our customers were asking for, such as edge AI, into the smallest, lowest power embedded processor designs.
The ability to customize the cores is important for AI and ML applications since the data types, quantization, and performance requirements differ greatly from application to application, and off-the-shelf processors may not be optimized for a specific task.
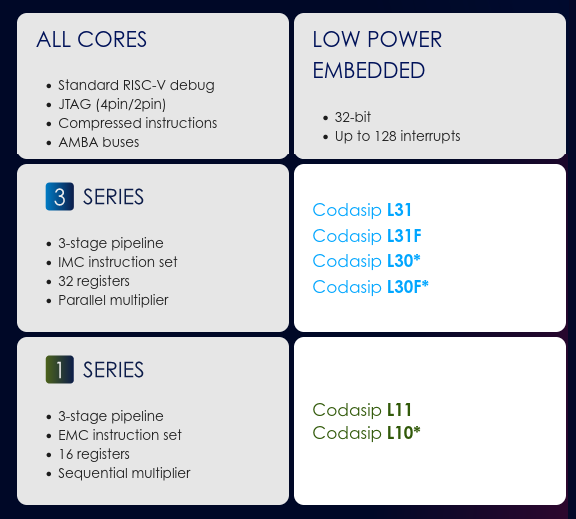
We’re not given a lot of details about the new cores except they all come with a 3-stage pipeline, while the Codasip L31/L31F (with FPU) use the RV32IMC instruction set, offer 32 registers and a parallel multiplier, while the Codasip L11 relies on RV32EMC instruction set, comes with 16 registers and a sequential multiplier. They also supersede the earlier Codasip L30(F) and L10 cores which are not recommended for new designs anymore.
Codadip showcases the benefits of using TFLite-Micro and customization in a white paper entitled “Embedded AI on L-Series Cores – Neural networks empowered by custom instructions” (registration required, but you can use a fake email). They used “MNIST handwritten digits classification” as an example and compared various implementations in terms of cycle, power, and area.
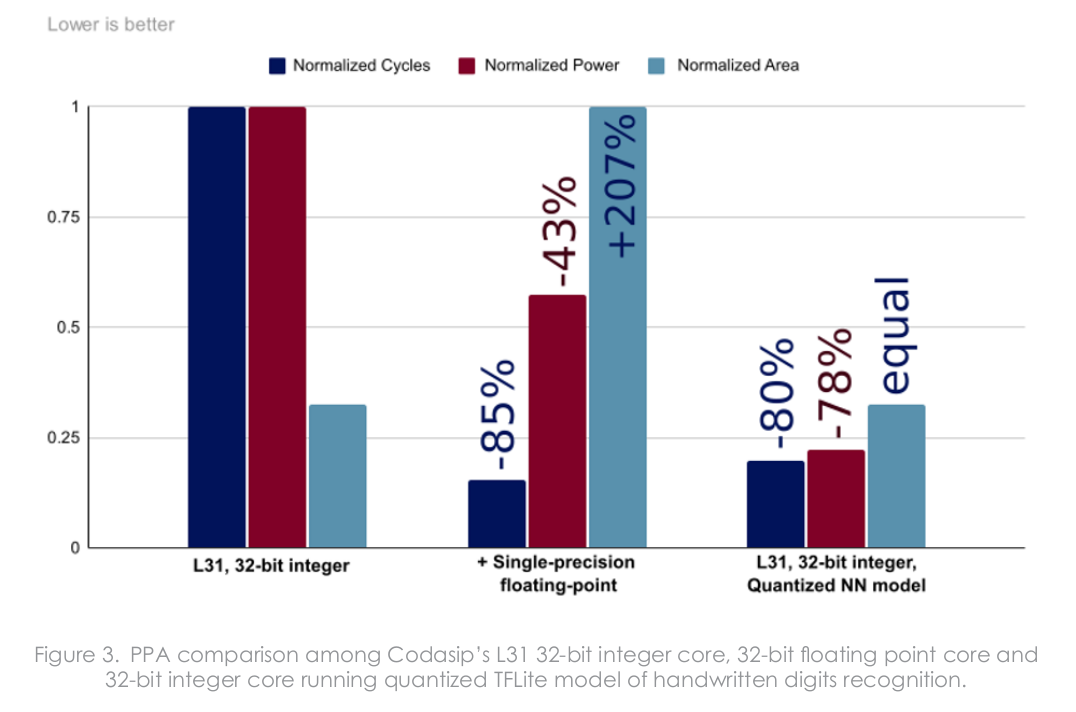 The L31 with FPU (31F) in the middle is much faster, consumes significantly less, but it would make a much larger chip. A solution is to use L31 with quantization of neural network parameters and the input data supported by TFLite-Micro, with almost the same performance as the hardware FPU solution, even lower power consumption, and the same area since the chip did not need to be changed. Switching to integer instead of floating-point had a negligible impact on accuracy: 98.91% (fp32) and 98.89% (int8) on a set of 10,000 images.
The L31 with FPU (31F) in the middle is much faster, consumes significantly less, but it would make a much larger chip. A solution is to use L31 with quantization of neural network parameters and the input data supported by TFLite-Micro, with almost the same performance as the hardware FPU solution, even lower power consumption, and the same area since the chip did not need to be changed. Switching to integer instead of floating-point had a negligible impact on accuracy: 98.91% (fp32) and 98.89% (int8) on a set of 10,000 images.
So the best tradeoff is to use L31 with TFLite-Micro, but to further optimize the design they profiled the program with Codasip Studio to locate the (C) code and associated instructions that consume the most cycles.
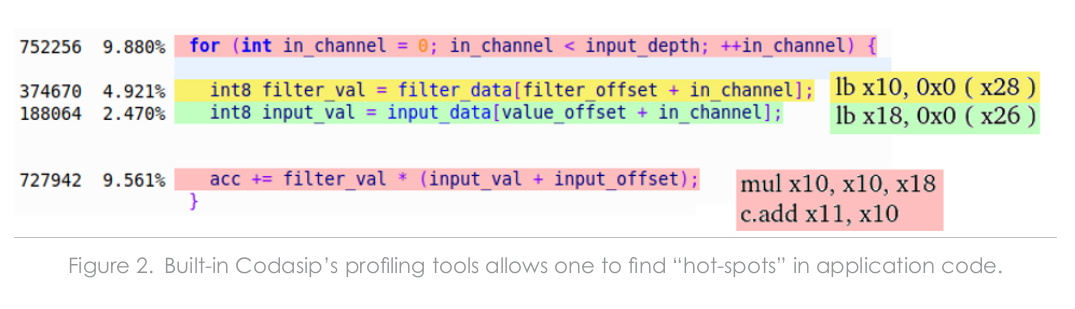
To optimize vector memory loads and sequences of convolutional multiplication and accumulation, they added two custom instructions:
- mac3 to join multiplication and addition into a single clock cycle (speeds the fourth line above)
- lb.pi to immediately increments the address after the load instruction. (join lines 2 and 3)

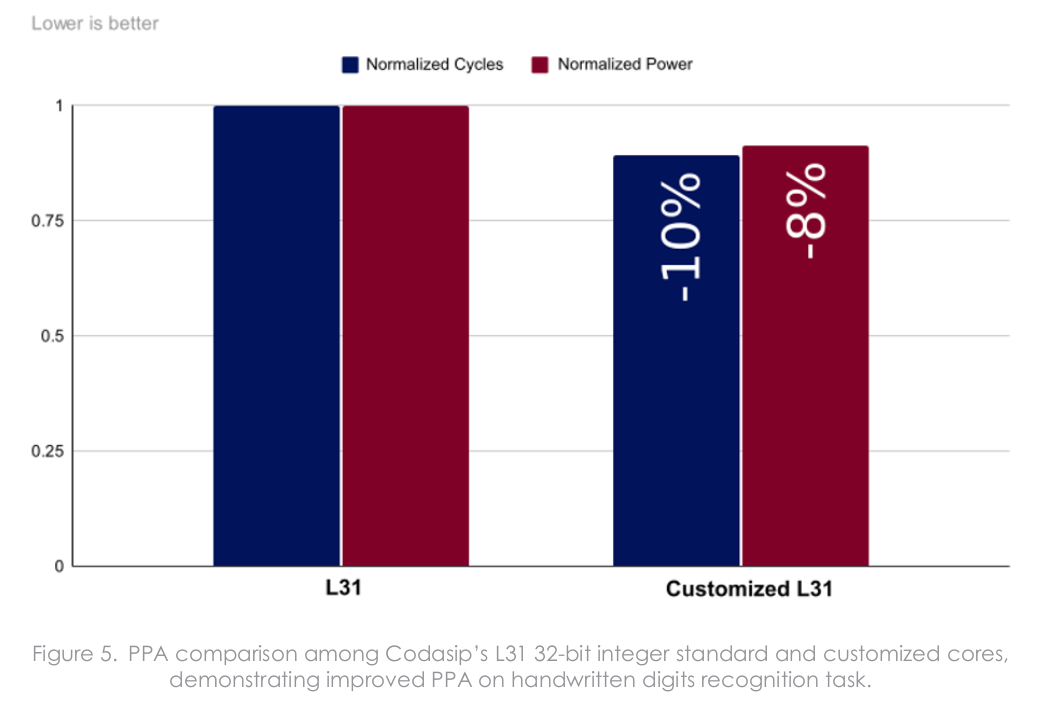
The new instructions show up in the profiles, and the whole loop consumes much fewer cycles. More specifically, this resulted in 10% fewer cycles and an eight percent reduction in power consumption. The new custom instructions did increase the area, but only by 0.8%.
 TFLite-Micro support is a new thing for Codasip’s RISC-V microcontrollers, but it’s now been added to all their cores.
TFLite-Micro support is a new thing for Codasip’s RISC-V microcontrollers, but it’s now been added to all their cores.
Evaluation of the core can be done on Digilent Nexys A7 FPGA board either running bare metal code or an RTOS such as FreeRTOS. More details about L31 and L11 RISC-V core might be on Codasip website and the press release.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



(Off-Topic) @Jean-Luc do you have any insider info on the new Radar Zero2? Some preliminary info on the Radxa Wiki, Zero sized board with Amlogic A311D; and CoreELEC has added images for the new board to their Nightly releases as of 20-Feb.
Nothing more than what is currently public.