
Rockchip RK3399 hexa-core processor with ARM Cortex A72 and A53 cores and a Mali-T860MP GPU will soon be found in TV boxes, development boards, tablets, Chromebooks, virtual reality headset and more, and is widely expected to offer a significant performance boost against previous Rockchip processors, including RK3288, and outperform SoCs from competitors like Amlogic and Allwinner.
We can have a first clue about the performance as Rockchip RK3399 boxes and one tablet are now showing up on GeekBench.
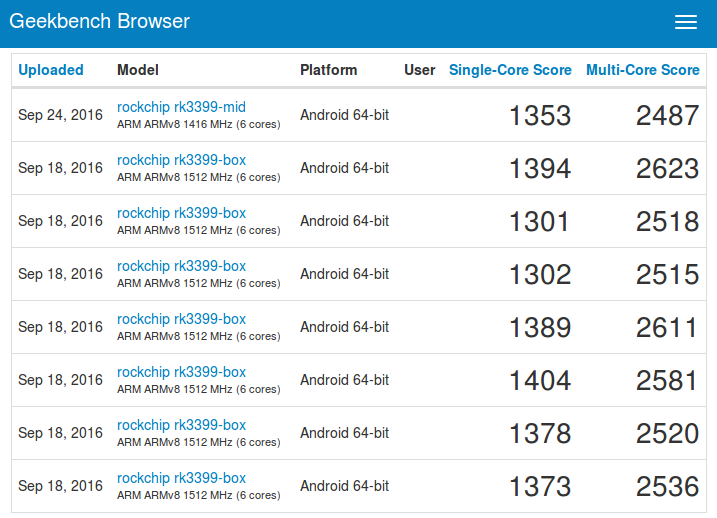
The box is clocked at 1512 MHz, while the tablet is limited to 1416 MHz, but overall single-core score is about 1350 points, while multi-core score hovers around 2,550 points. I’m not that familiar with GeekBench so number don’t tell me anything. Let’s compare it against RK3288 which CPU-wise is the fastest processor I known of from Chinese silicon vendors targeting TV boxes.
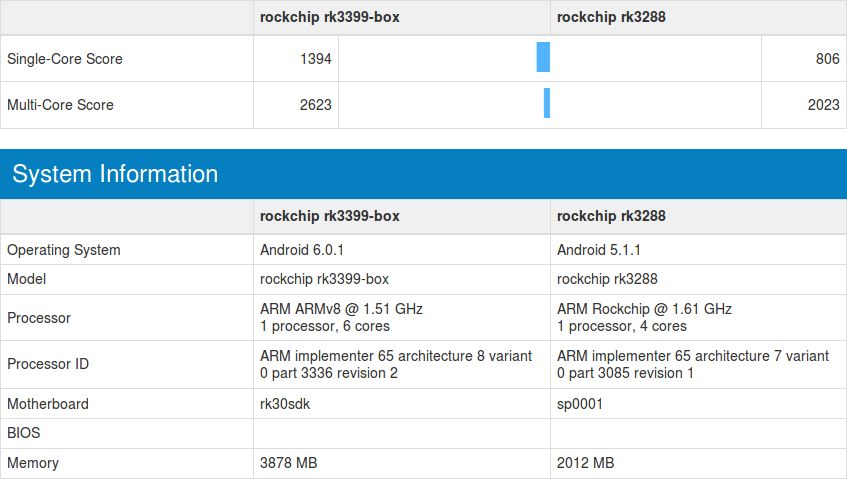 There’s a significant single-core performance boost (+73%), and lower multi-core delta (+30%) as expected since RK3399 has 2 fast Cortex A72 cores, 4 low power Cortex-A53 cores, against 4 fast Cortex-A17 cores for RK3288. If you look into the details AES is over 10 times faster on RK3399, so there must be some special instructions used here, or AES hardware acceleration.
There’s a significant single-core performance boost (+73%), and lower multi-core delta (+30%) as expected since RK3399 has 2 fast Cortex A72 cores, 4 low power Cortex-A53 cores, against 4 fast Cortex-A17 cores for RK3288. If you look into the details AES is over 10 times faster on RK3399, so there must be some special instructions used here, or AES hardware acceleration.
Rockchip RK3399 “reference” TV box also has 4GB RAM, so I’m expecting RK3399 devices to come with 2 and 4 GB versions.
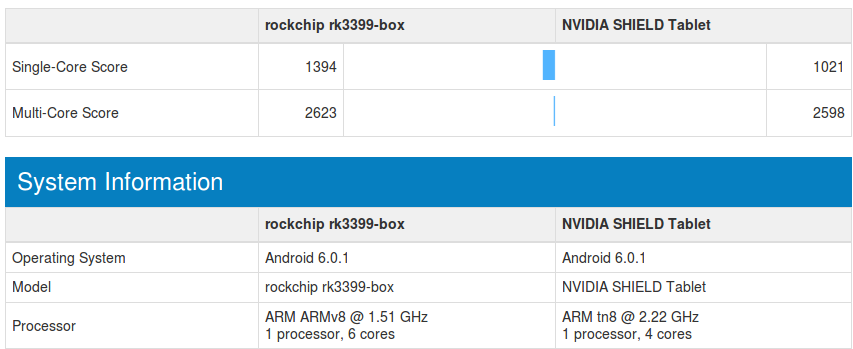
Rockchip RK3399 is also faster than Nvidia Tegra K1 quad core Cortex A15 @ 2.2 GHz for single thread performance, and about equivalent for multi-core tests.
[Update: I also found GFXBench 3D graphics results for RK3399, and compared it to Nvidia Tegra K1.
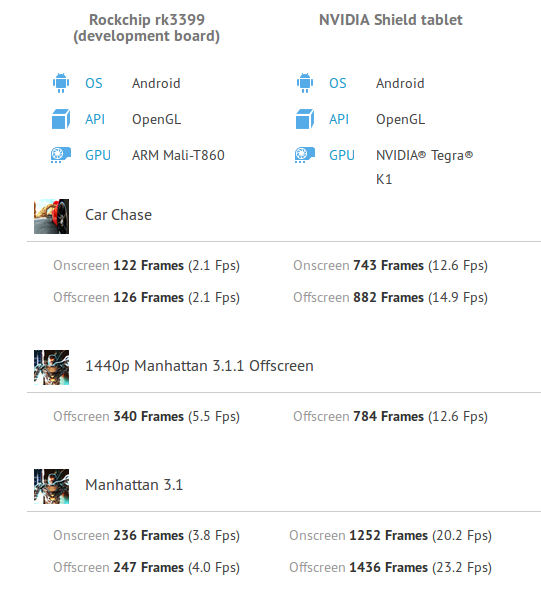 The Mali-T860MP used in RK3399 is still far from the performance delivered by the Kepler GPU in Tegra K1.
The Mali-T860MP used in RK3399 is still far from the performance delivered by the Kepler GPU in Tegra K1.
Now if I compare the results to RK3288 (Mali-T764 GPU) based Ugoos UT3s TV box, the score on RK3399 (Mali-T860MP4) is also lower.
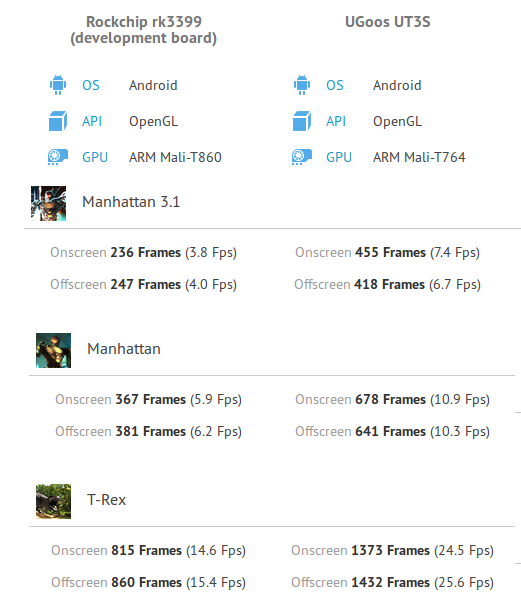 We’ll have to wait and see here, as we don’t know at which frequency the GPU is running. Both GPUs are supposed to have the same performance according to Wikipedia.]
We’ll have to wait and see here, as we don’t know at which frequency the GPU is running. Both GPUs are supposed to have the same performance according to Wikipedia.]
Thanks to Feelgood for the tip.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.



Nice to see how a dual-core A72 is able to perform (count of cores used can be seen when comparing single and multi threaded Geekbench results)
That’s very impressive, but I expect the multicore score to improve somewhat with time.
2K for multicore is what the current crop of RK3368 achieves.
I’ll be taking a look at the compute scores, that’s where you’ll probably see a significant gain in performance.
Interestingly enough, the compute score is very low compared to what I expected
https://browser.primatelabs.com/v4/compute/102235
Not looking good at this point.
@shomari
How should ‘multicore score’ improve? Geekbench is just a dumb passive benchmark and simply runs single or multi threaded. It depends on the kernel and active settings what happens then (and of course switching to the quad-core A53 cluster would improve numbers). What does Geekbench numbers tell then? Not that much as usual 🙂
But people love comparing numbers even if they’ve no meaning at all (since it’s so easy). Still true: Passive benchmarking is in 99.x% of the times just ‘benchmarking gone wrong’ 🙂
Those Geekbench numbers could be used to dig deeper into a) how to improve scheduling (when/if these devices run on Linux) and b) why do AES numbers look that good. Nobody will do that of course…
I don’t disagree. I use Geekbench for very specific reasons, not just a simplistic look at the numbers.
@shomari
It’s faster compared to RK3368 (and RK3288) https://browser.primatelabs.com/v4/compute/compare/111581?baseline=102235
Compute relies on the GPU, and Tegra K1 is way faster with the Kepler GPU -> https://browser.primatelabs.com/v4/compute/compare/112632?baseline=102235
For some reasons Nvidia Shield Android TV (Tegra X1) has about the same compute results as RK3399 -> https://browser.primatelabs.com/v4/compute/compare/108223?baseline=102235
What’s going on here?
My comment was more in relation to the contrast between the current A53 and the RK3399.
Configuration is a big deal with this kind of benchmark. The results measure settings and even environments more than they validate hardware performance. There’s no telling what was really being tested when a user launched/executed the benchmark just by looking at the number itself.
Passive benchmarking gone wrong? Just another quick&dirty Android benchmark measuring software/settings and claiming to test hardware instead? 🙂
Unfortunately that does not only apply to Android but to the other platforms Geekbench ‘supports’ too (we had a customer buying outdated Macs a few years ago based on moronic ‘Multi Core’ Geekbench scores that were absolutely irrelevant. They paid a lot more money to get the slower machines thanks to ‘benchmarking gone wrong’)
… except it’s not really the benchmark that’s gone wrong. The benchmark suite does what it does, spews the data and of course most people either misinterpret or at best only half-interpret the results.
Some 3D graphics benchmarks for RK3399 -> https://gfxbench.com/device.jsp?benchmark=gfx40&os=Android&api=gl&D=Rockchip+rk3399+%28development+board%29&testgroup=overall
@shomari
Please look at these Pine64 results: https://browser.primatelabs.com/geekbench3/search?q=a64
A benchmark that hides throttling and even killed CPU cores is bad. There are results collected with only 3, 2 or even 1 active CPU cores without warning the clueless target audience that something’s wrong. And then people start to draw the wrong conclusions (like ‘Android 7.0 is faster than Android 5.1 on Pine64’ while in reality the community Android builds simply rely on community and not vendor settings — that’s dvfs / cpufreq scaling and improved throttling settings). And obviously something similar happens when ‘benchmarking’ Tegra X1 where for whatever reasons GPU is not active?
If you’re doing serious benchmarking you know that you throw results away almost always since mistakes happened or environmental conditions invalidated results. Popular benchmarks like those we’re talking here about instead spit out and even collect numbers without meaning to keep the target audience happy — unfortunately there’s no button ‘hide BS results’ in primatelabs’ geekbench browser 🙁
But you’re absolutely right that results have to be interpreted correctly.
Compare with mt8693 in mibox 3 pro
Do the RK3288 and RK3399 both have the same number of copies of the GPU? RK3399 might have two, and RK3288 has four? That would explain the 2:1 performance difference.
@Jon Smirl
RK3399 has Mali-T864, RK3288 has Mali-T764, Geekbench score is CPU only here and seems to use the 2xA72 cluster exclusively?
@tkaiser
I see this: RK3399 has Mali-T864, RK3288 has Mali-T764. But you can put down between one and four shader units with those GPUs. Did both chips put down the same number of shader units on the chip? A T-864 shader may be equal to the T764 one, but if one chip has four copies and the other only has two, performance is not equal.
They supposedly both use MP4 (quad core) configurations.
We also have to remember that early builds are often not optimized and sometimes even run at slower speeds.
I’m guessing/hoping that performance is equal, possibly slightly better on more advanced stuff (due to generational advances) on the new SoC.
As for AES, from what I understand ARMv8 has built-in support for it while v7 doesn’t (which supposedly even has to do with some mainstream devices not supporting upgrades).
Good point @Tarwin, that early units are not optimized and may run slower. That’s my new default statement on STB’s, as demonstrated by S905 ( nevermind the A,X,912 units) though comparing Rockchip and Amlogic is not really an accurate comparison.
@Jon Smirl
Might be true but this Geekbench ‘single vs multi core’ non-sense is only about CPU (cores) — see the Pine64 numbers above (there are numbers where Allwinner’s weird ‘kill CPU cores instead of throttling’ settings combined with overheating before led to A64 running on a single CPU core any more and then single and multi core scores are identical)
Hi, wird der RK3399 besser sein als der AMLS.912? Und wird RK 3399 AES Verschlüsselung unterstützen?
@Jon Smirl
I think the “4” at the end of the part number represents the number of cores. The must be using different nomenclature, with Mali-T864 = Mali-T860MP4, and Mali-T764 = Mali-T760MP4.
@Reflexion
CPU and GPU wise RK3399 will be significantly faster than Amlogic S912 SoC.
For video quality and decoding capabilities, Amlogic S912 might still be ahead however. This will have to be tested.
@cnxsoft
If RockChip deliver on the promised I/O capabilities, RK3399 will be an outstanding allrounder. If they can also deliver on the promised 2 GHz capability for A72 and A53 cores then RK3399 may be able to dominate the market in the way that RK3188 did a few years ago.
@Curmudgeon
Except the promotional material only said “up to 2ghz” and never said if it applied to both core clusters. It could be only for the 72s or only the 53s with the other one being a shower frequency (I hope it’s not the case but I’m hedging my bets).
@tarwin
A72 and A53 cores will likely run at different frequencies.
I think Cortex A72 cores are currently clocked @ 1.512 GHz in the devices used in the benchmarks.
Can someone explain why the cluster of 4 cortex A53 cores from Nvidia is faster than the same cluster but from Allwinner ? Also, I use geekbench every day and sometimes it doesn’t make sense, so I can see what you mean by dead cores. For example, why does RK3399 have similar performance to Tegra K1, it has two cortex A72 cores and a cluster of Cortex A53, yet on Geekbench it has similar score for multicore, but higher for single but yet again why is does a more modern hexa core CPU have similar scores to an old quad core ? Should we trust Antutu more ?
And isn’t the Allwinner A80 better than the RK3288 ?
@Ahmed
Nvidia Tegra K1 uses four Cortex A15 cores @ 2.2 GHz (fast 32-bit cores), Rockchip RK3288 uses four Cortex A17 cores (also fast 32-bit cores) but at a lower frequency, while Rockchip RK3399 uses two Cortex A72 cores @ 1.5 GHz (fast 64-bit cores) and four Cortex A53 cores (low power and slower 64-bit cores).
Cortex A72 is the fastest core you can get, and that why single core performance is better.
I’m not sure how GeekBench multicore benchmark works, but provided there’s no throttling and it use all cores, it means that, using Nvidia Tegra K1 and RK3399 as example, 4x Cortex A15 cores @ 2.2 GHz are about as fast as 2x Cortex A72 cores @ 1.5 Ghz + 4x Cortex A53 cores @ 1.0? GHz. The results are quite close to what you’d expect actually.
Allwinner A80 has never been very popular, probably because of cost and poor software support.
A64 on Pine64 runs with 1152 MHz max (not 1.34 GHz as reported by this Geekbench thingie) and as long as Allwinner’s original (bad) settings are used on boards without heatsink chances are great that it’s not a quad-core SoC but just one with 3, 2 or even 1 active cores any more (the default cpufreq scaling is also pretty bad so as soon as throttling gets an issue A64 will perform pretty bad). The quad-core Nvidia SoC is clocked almost twice as fast and it shows also magnitudes better memory throughput / latency (which might some/most of the benchmarks).
Apart from that RK3399 is not a hexa-core SoC (at least with the current Android kernel and settings used) but either a dual-core A72 or a quad-core A53. With Geekbench the whole benchmarks ran on the 2 A72 cores. No A53 involved.
And I really don’t think replacing one broken passive benchmark approach with another is an option 😉 The reason is simple: those benchmarks used here will ‘prove’ that Allwinner’s A83T for example (two Cortex-A7 clusters used in HMP mode == octa-cores) is faster than RK3288 (one Cortex-A17 cluster == quad-core) since multithreaded benchmark non-sense shows higher numbers. In reality RK3288 shows a single threaded performance that is 1.5 as much as A83T’s so real world performance is way better with RK3288. These benchmarks are broken by design or at least it needs a lot of knowledge to draw the right conclusions from them.
I just ran GeekBench on Xiaomi Box 3 Enhanced CPU Mediatek MT8693 same architecture RK3399 (2xA72 and 4xA53) with single core about 1559 and multi core about 3064, all higher than RK3399. I also ran GFXbench and score is higher than RK3399 with 250.7 vs 236.9
@hoangdinh86
Then Geekbench is showing that MT8693 is also just a dual-core SoC when we’re talking about CPU performance? 😉
BTW: It gets even more funny when looking at so called deca-core SoCs like Mediatek’s X20: https://browser.primatelabs.com/v4/cpu/search?q=mt6797
Obviously the benchmark sometimes runs on the 2xA72 cluster, sometimes on the slow and sometimes on the faster 4xA53 cluster and the kernel switches between the 3 clusters at runtime sometimes (maybe based on thermal/throttling behaviour?). Without continually monitoring both actual cpufreqs and reported SoC temperature this is just the usual and useless ‘fire and forget benchmark’ crap producing random numbers. But people seem to love numbers without meaning…
… you’re making really good points here, as usual.
This discussion has spurred me to continue with my once abandoned project to enable ‘true’ octacore processing, allowing mulithreading among all cores of the RK3368.
So far, I’ve disabled all throttling and lowered the vcore as a compensation at the risk of impacting stability. I’m experimenting with allowing individual cores to sleep as another method of power management … but the main task for now is to eliminate segfaults and async errors and finally accomplish true multithreading in order to gauge just what this architecture on RK3368 can do. Because as set to stock, I am convinced they’re crippled.
The differences are caused because these are not like for like comparisons.
Think of it as one race track, and three, 1.2 Litre cars,
A Ford
A Vauxhall
A Fiat
They are all petrol cars, they all use combustion engines and all use tyres. However design difference mean they don’t all finish first or handle the same.
@paul taraneh
The problem with people scared about low ‘multi core’ performance numbers is that they don’t want to understand what these deca-core and hexa-core implementations are in reality. None of the big.LITTLE implementations here is using HMP: Heterogeneous multi-processing (global task scheduling), they’re all just a bunch of independent CPU clusters that work either/or.
So RK3399 is either dual or quad core as is Mediatek’s ‘deca-core’ X20 too for example. This one is not really deca-core but dual-core when it’s about ‘high performance’ and quad-core when the device is idling around or starts to overheat (this is something that can be seen easily within Geekbench browser by sorting the rows). So based on the kernel’s decisions a hexa or deca core SoC might perform not that good compared to quad or octa core implementations since there the fast or only CPU cluster consists of 4 cores while here it’s just 2 (and 4 A53 do almost always outperform 2 A72 when the workload is really multithreaded especially when throttling is an issue).
These benchmark numbers don’t tell this, fortunately most of the time multithreaded performance is irrelevant at all and many stuff happens on the GPU cores or in special engines anyway. But the target audience does not care, they prefer a deca-core over quad-core since… ‘6 is more than 4’ even if they end up with just 2 CPU cores used for performance stuff.
BTW: Switching to HMP instead (so a deca-core SoC would really run on 6 cores at the same time) can trigger funny bugs (crashes in this case): http://www.mono-project.com/news/2016/09/12/arm64-icache/
.. that last bit about switching to HMP is a real problem, I’ve been having plenty of these errors and segfaults trying to bring up an octacore in this fashion.
For the record, HMP has been working more or less ok on the RK3368, but that’s not as ‘heterogeneous’ (both big and LITTLE being A53, difference being in clocks and cache sizes) as RK3399, so your HMP mileage with the latter may vary.
I brought up all eight cores on the RK3368 as well; scaling, latency and clocks are uniform across all cores using GTS. Antutu completes and shows significant performance gains but unfortunately GeekBench segfaults once multi threading kicks in.
@blu
Nice, I searched for ‘RK3368’ on my local machine (Spotlight in OS X) just to discover that I bought a device with it 10 months ago. Now searching for the GeekBox (physically — no search engine involved 😉 ) to do some testing the next days 🙂
BTW: When looking at the Geekbench scores for Mediatek X20 the device showing the highest ‘multi-core’ score shows also the lowest CPU clockspeed (+5100 points at 1391 MHz). But as we already know Geekbench just shows random numbers here relying on cpufreq info and being blind for the real values. Maybe that’s the reason all Android SoC vendors start to ship with kernels that show nice values when querying
/sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_max_freq
but limit maximum clockspeed possible somewhere in throttling / thermal frameworks (again as example: all Allwinner A64 devices will be listed as running at 1.34 GHz while they’re limited to 1152 MHz with default settings — unfortunately I don’t know how other vendors handle this stuff but obviously they all do the same here and the usual tools used report random numbers)
@tkaiser
I think most devices support HMP. TV boxes based on Amlogic S912 can use all 8 cores simultaneously based on info returned by Kodi. I also tested Allwinner A80 in the past and all eight cores could also be used. Now I did not investigate at what freq. they were running. This mostly depends on the thermal design.
Obviously the ones we’re talking here about (RK3399 and both Mediatek MT8693 and MT6797) don’t do it. If Geekbench multi-core score is ~190% or below the single-core score then it runs on 2 CPU cores. RK3399 is a dual-core SoC in multi-threaded performance mode unless you can force the kernel to switch to the ‘slower’ 4xA53 cluster which would show higher multi-core scores.
The problem is as follows (quoting the link above): ‘Some ARM big.LITTLE CPUs can have cores with different cache line sizes, and pretty much no code out there is ready to deal with it as they assume all cores to be symmetrical.’
SoCs that contain two clusters made of identical cores (S912, Allwinner A83T, Samsung/Nexell S5P6818 and many others — all not implementing big.LITTLE) support HMP perfectly, on those that mix different CPU cores the cache line size matters (or will trigger crashes/segfaults). Do you know how A72 and A53 cores in RK3399 behave here?
Anyway: it would be really interesting to test through both clusters individually on SoCs like this even if HMP wouldn’t be possible since workloads that benefit from more CPU cores could run faster on the quad-core A53 cluster.
Needs real world tests
For games a heavy 3D graphics game ( just as Doom 3 on Windoz sorted the wheat from the chaff, in graphics cards )
Synthetic tests are being gamed and meaning less.
@tkaiser
I think your explanation is the most likely, but could it also be possible that the Cortex 72 cores get clocked lower when Cortex A53 cores are running are the same time? For example 2x Cortex A72 @ 1.2 Ghz + 4x Cortex A53 @ 1.0 GHz? N/B: I just made up the freq., did not do any specific calculation here.
@cnxsoft
Well, I’ve no idea what’s going on there but what I know for sure is that instead of playing games (Doom 3, Geekbench or the like) it helps more trying to understand what’s happening. Any of the owners of such a device could start to explore how the OS/kernel behaves instead of just producing numbers without meaning.
Monitoring the following (in a 1 second loop) seems mandatory to me while increasing the load with single and multi-threaded tasks one after another:
(count of active cpu cores, actual cpufreq, temperature of all known sensors found at the ‘usual’ location).
You know I had a RK3066 1GB Android TV dongle/stick a year or more back. It started in Android 4.1 and only did 1.2Ghz If CPU-Z can be trusted. I search around and flash another firmware to Android 4.2.
I could internet browse, use Kodi and my countries IPTV players, iPlayer, ITV, All 4 etc. Game wise Angry birds would play.
So what the point of my post! Simple really consumers buy stuff to do want they want done. Whether watching Films, TV, web browsing , messaging, skhping loved ones abroad or reading emails. Technical minutiae has no interest for them!.
Put another way the home PC dies, tablet sales are dying, yet these product have better specification than any £30- £ 60 TV box. Folk want good audiovisual to watch content and kids want games that don’t cost £25 – £45 like on gaming consoles. Parents want something little junior won’t smash so easy or need constant charging.
It is then content not the box Joe public desire most. Hence you can cheat, game a bench mark but if it cannot deliver the desired content it won’t sell well.
So while these are bench mark results even emmc and memory used, firmware affect the real world use. So you are comparing Oranges and Apples with the results all down to personal taste.
Enjoy the circular debate☺
So according to Geekbench, the A64 chip is usually running with at least one dead core?
And without HMP, the processor will not perform as well as we think, in this case, the RK3399?
Also when you said that the A80 is worse than the RK3288 because of software support, isn’t that because of the companies that manufacture the tablet?
So do we trust geekbench, or is geekbench telling the truth because the processor isn’t using HMP?
And one last question, Why did Allwinner cancel the A80 and continue with the A83T, even tho the A83T is worse?
@Ahmed
You find in Geekbench browser results for A64 devices running at 4, 3 and only 1 core (easy: simply look at single-core score and compare with multi-core score, if they’re the same it’s only one active core, if it’s ~350% all 4 cores are active — you might get the idea how to calculate ‘active CPU cores’ based on those 2 performance numbers). This conclusion is backed by developing better throttling settings for these SoCs (not only A64 is affected by this ‘kill CPU cores instead of throttling’ but all more recent Allwinner SoCs: H3, A83T, A33…). We (linux-sunxi community) did that half a year ago for A64 and we preferred throttling over killing cores.
A64 and all other quad-core SoCs have only one CPU cluster so there’s no need to think about HMP or the other possible modes to deal with a bunch of different CPU clusters. This is only important if the core count exceeds 4 and different CPU cores are present in the various clusters. Then various different modes are possible, HMP being the only one where all CPU cores could run at the same time. I wrote ‘could’ for a reason since the thermal design of devices containing these SoCs will prevent that.
If your device using such a SoC runs in a lab with huge heatsinks + fan or even liquid cooling think about heavy loads running on more than 4 cores in parallel, otherwise not. And that’s the problem with benchmarks and some SoCs (eg. Allwinner’s A80 which is known to melt away under load).
Anyway: if we’re talking about a TV box CPU performance is more or less irrelevant (as long as the SoC supports the relevant video codecs HW accelerated) and other ‘engines’ do matter in reality (HW video decoder, GPU). The average TV box or smartphone customer will never understand that (‘Gimme more CPU cores, higher clockspeeds and more DRAM!!!). That’s the reason why hardware vendors cramp more CPU clusters inside their SoCs even if it’s pretty much useless and that’s also the reason why ‘benchmarks’ like Geekbench are both irrelevant and popular (same target audience as the devices they test — clueless people)
As of cache line mismatch: it pretty sucks that user code is trying to mess around with cache “flushing”. Worse – when it does it so lame (as in the example with Mono). This is a task for an OS. The latter should expose an appropriate API and user mode software should make use of it, consistent way, becoming HMP-aware. It should not be any harder than when transiting from a single thread to multithread design. Anyway, it’s just a quirk when some user mode program tries to do an OS job. Even JIT should just do this: compiling its code, it should ask OS – hey, this is my new code, put it appropriately please as a code. 😉 It should boil down to a sort of dynamic image loading by the OS, which will take care of what the current cache line is. User programs should not try to do a cache maintenance by itself. It’s a wrong software, not the technology. Unlike such a parasitic thing as hardware virtualization is, HMP is a good and usefull thing. Software should adopt it proper way, not through the ass. So if the you cannot take advantage of all CPU cores found in these SoCs it’s a software fault. I am not interested in linux, but I heard, ARM has an HMP ready code for it. But it is rejected to be “upstreamed”, since well, linux acrhitecture is going to blow away because of this, it is not flexible enough to incorporate this, without massive shit happenning on the entire platforms landscape.
This may help the less technical grasp there is more at work than a CPU core
https://en.m.wikipedia.org/wiki/ARM_big.LITTLE
@tkaiser
“BTW: Switching to HMP instead (so a deca-core SoC would really run on 6 cores at the same time) can trigger funny bugs (crashes in this case):”
That bug has nothing to do with HMP. It would show up on a system with “Task migration” model too. I just cannot understand why the hell gcc function does cache clean? where it is used? how it’s possible? Oh, I just realised this instruction *might* be enabled at EL0 in aarch64. So, gcc hastily run to use this new thingy, forgetting about all the consequences. it gets a value of the log2(CacheLine) from the CPU register into the local variable, and calculates cache line as if there is no big.LITTLE core differences on the system. If after it calculates the cache line, OS decides to switch CPUs, the function gets to run on the different core with possibly different cache line size, but the function didn’t bother with this, it has the result. bogus one. This will be the case both on HMP and non-HMP big.LITTLE scenarios where cache sizes of the cores differ. If it is a switch from big to LITTLE, the function’s operation misses half of locations in its cache cleaning loop, given caches differ by 2 and that of the big core is bigger. It’s just a horrible implementation in gcc. yup.
So according to what you’re saying, Geekbench will be telling the correct score of the CPU if there are dead cores, but if the CPU does not use HMP, then Geekbench will be telling us false results because, in real time performance, the CPU is much more powerful than what it says. Right?
If you are right does that mean the RK3399 can get close to the performance of Snapdragon 652 and Exynos octa-core CPUs
It seems that the first models will be available soon but at what price : http://www.android-warehouse.com/nl/ugoos-ut5-hexacore-android-tv-box-mini-pc-androidb.html
I just backed Remix IO+ on Kickstarter. They say it runs an RK3399 chip. The campaign also has a “basic” version that runs on an RK3368 chip. Are these chips going to make a difference at the end of the day for their performance?