
We’ve previously reported Pine64 had developed “Sopine Clusterboard” for a specific project with support for up to seven SOPINE A64 SoMs powered by Allwinner A64 quad core Cortex A53 processor.
At the time (August 2017), it was unclear whether the company would sell to the solution publicly, but they’ve now gone ahead and launched Pine64 ClusterBoard for $99.99 plus shipping, including one free SOPINE A64 module for a limited time.

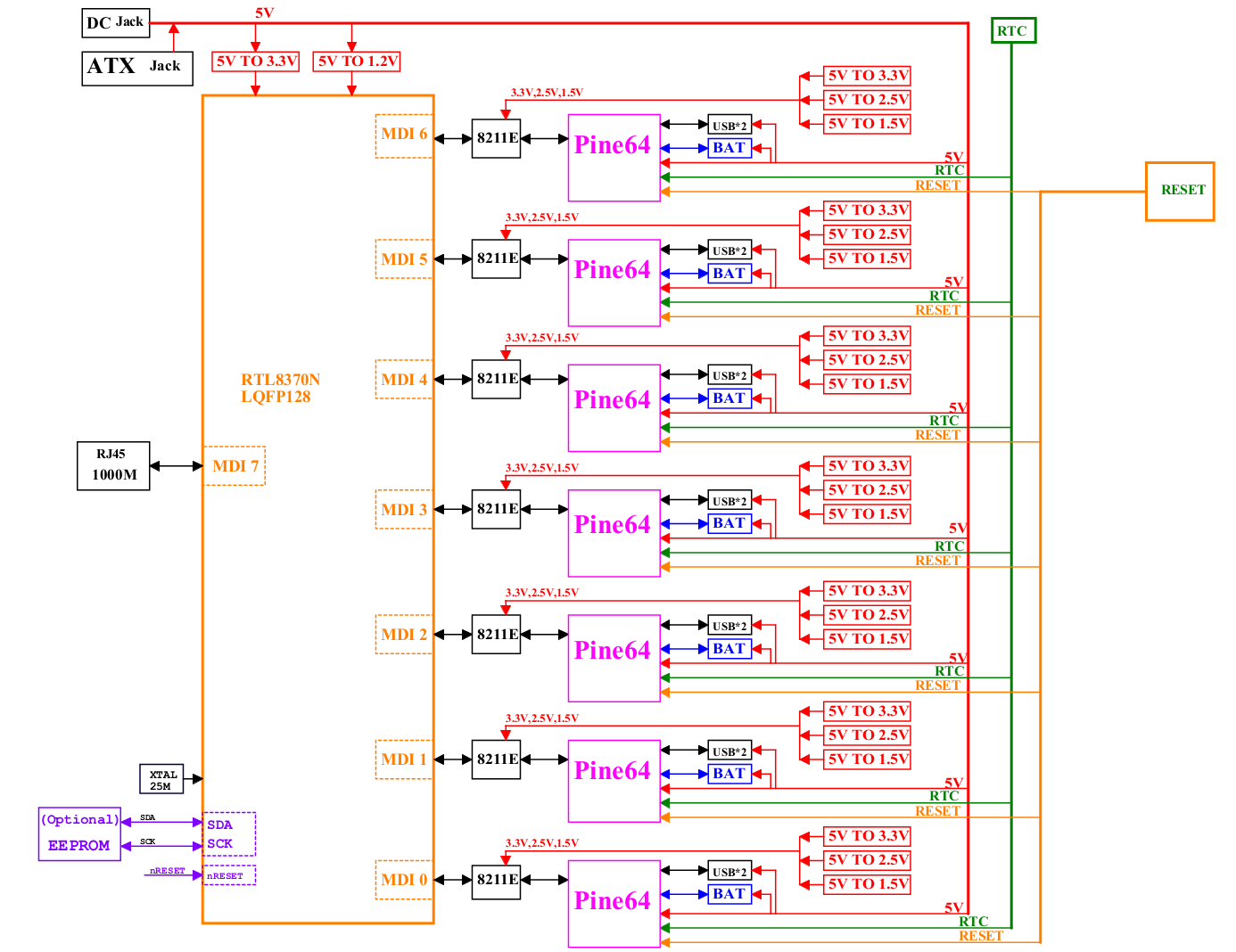
PINE64 ClusterBoard specifications:
- SoM Slots – 7x SO-DIMM slot for SOPINE A64 modules
- Connectivity
- 1x Gigabit Ethernet port (RJ45)
- All SoMs are connected via Gigabit Ethernet using 7x RTL8211E transceivers and RTL8370N network switch (See diagram below)
- USB – 7x USB 2.0 port, one per SoM
- Expansion – Headers for each SoM with UART (serial console), I2C, key ADC, GPIOs, SPI, RESET/POWER 5V and GND
- Misc – RTC, reset button, optional EEPROM connected to RTL8370N
- Power Supply
- 5V/15A via power barrel jack
- ATX connector
- 2x battery slot for RTC battery backup, and buffer the AXP803 PMICs in deep suspend
- Dimensions – 170 x 170 mm (mini-ITX form factor)
You’ll find software for SOPINE A64 module, as well as the hardware design files (PDF and native) on SOPine Wiki. You’ll also want to purchase extra SOPINE A64 SoMs ($29) and a power supply ($15.99) on Pine64 store to have a complete system.


Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.


Nice!, can they be netbooted without an sd card?
@Jeroen
Yes, each SOPine module has a SPI NOR Flash that is bootable, so you can install u-boot on there… check out ayufan’s first proof-of-concept implementation here… https://github.com/ayufan-pine64/bootloader-build/releases
But it still won’t have raspberry’s level of support. A cluster of pi zeros is a decent alternative. Armv6 has better software support too.
A nice.
@Jerry
The A64 has pretty good mainline kernel support by now, and i think the pi’s still have there nic over usb and i guess 100mbit.
I run happily on my SoPines swarm cluster over PXE with NFS drivers. Bootloader is in SPI and since you have GbE it works decently well. You can also have local storage for persistent data if you need, but so far this is very interesting 🙂
Grab this bootlader: https://github.com/ayufan-pine64/bootloader-build/releases
And compile this repo (no docs now): https://github.com/ayufan-rock64/cluster-build to have mainline kernel ready for netbooting sopine or rock64
The fact is that the GbE is the faster interface on A64.
Pi Zeros have no network at all and also aren’t able to netboot (the bootcode for this has only been added to the VC4 in the BCM2387 used currently on RPi 2 and 3). Though RPi Zero can use the OTG port with Ethernet gadget module and is then even ‘faster’ than RPi 3 since with this USB Ethernet mode you slightly exceed Fast Ethernet ‘performance’. So yes, if you love to deal with tons of crappy SD cards and want to implement USB only networking in a horribly stupid daisy-chaining architecture a Pi Zero is the way better alternative. Also the adventure to order these Zeroes in volume 🙂
BTW: I would assume the poor RPi network speeds will soon be ‘fixed’ by the mythical Foundation using Microchip’s LAN7850 on next RPi model in a few weeks basing on BCM2388.
I would have never used this as an occasion to even compare RPi’s to other boards.
Yes, they are underpowered compared to plenty other ones and lack correct connectivity.
But, to their immense credit:
They have brought to the world an amazing piece of hardware for a handful of bucks with a broad support and pretty hackable despite having BCM chips, GigE speeds has never been part of their goals, but accessibility for educative purposes has and still is, and they excel in this area.
Plus, I’m pretty sure their little board has kicked so well it inspired other to make a broad variety of boards, some who fit specific needs and use cases, without them, we would have waited long years to get affordable ones.
Hat’s off to RasPi, imho, it’s thanks to them we have so many cheap Exynos, H4, A64, Rk* cards around nowadays 🙂
@tkaiser
Try to be fair. As demonstrated a zero-cluster dosn’t require sds for every zero. See :
https://www.raspberrypi.org/forums/viewtopic.php?f=49&t=199994, Zeroes are available in volume – at another picepoint than the single one. That said, a SOPINE A64 module gives you 4 a53 cores and more bandwidth – also to another pricepoint.
@tkaiser
I am skeptical there will be a new RPi this year. Broadcom is now a Singapore company (that is relocating headquarters to USA). They are also pursuing Qualcomm. I believe this puts RPi in the ironic position that they could not purchase enough volume (MOQ) to warrant another custom silicon part. RPi likely needs to purchase a minimum amount of chip for any product to maintain their pre-existing supply contracts. The Pi-zero was likely a solution to this dilemma. However, it has put RPi in the untenable situation of competing with their own customers (Farnell/Element 13) by cannibalizing sales of the RPi 2/3. Due to all these factors I do not expect to ever see a “RPi 4”. Any “new” products should be derivatives of existing products or “refreshes” to meet MOQ. The caveat is that in the near future, they may simply sell the “Raspberry Pi” trademark to another company that would make a “RPi 4” in name only.
@crashoverride
Well, combining BCM2837 with a 6-port USB hub and Microchip LAN7850 is an option too of course 😉
hello Why the only use 1Gbs for all out put each module SOM alone can support 1Gbs
That’s the result of using the RTL8370N as internal switch IC (supports only 8 x GbE). Replacing this with something with one or two 10GbE links is possible but much more expensive. But of course you can design your own baseboards that do so (and this happens in reality, people use SoPine modules on their own clusterboards).
BTW: in real world compute cluster scenarios this ‘1 GbE to the outside’ limitation isn’t that much of an issue anyway. Those workloads do not saturate Gigabit Ethernet constantly while nodes highly benefit from full 940 Mbits/sec peak bandwidth and low GbE latency (unlike Raspberry Pi based clusters for example, they’s bottlenecked by their single USB2 port where all is behind all the time)
On a related note: Seems like Pine folks evaluate now a compatible RK3399 based SO-DIMM module 🙂
An RK3399 SO-DIMM would be neat! Would allow for some proper compute-density builds.
@michael
That’s interesting! I wasn’t aware that they added USB booting capabilities to the BCM2835 too. And it’s also interesting that this is possible in this topology. So in fact the newer BCM2835/BCM2837 do contain a copy of ThreadX that had to be loaded from an SD card’s FAT partition with earlier SoCs now also in silicon?
Now loading the VideoCore’s RTOS from SD card (bootcode.bin and start*.elf) has higher boot priority but in case SD card is missing the VideoCore boots ThreadX from an internal copy stored in the chip. And they added g_ether functionality to ThreadX too since otherwise it wouldn’t be possible to ‘netboot’ a Pi Zero over USB.
Well, while interesting I clearly miss any use cases for Pi clusters and the same applies to SoPine. Nice and maybe exciting but how to use this productive?
@tkaiser
Well, after reading through hackaday.io/project/27142-terrible-cluster it seems that’s just a more minimal bootloader (though g_ether capable) contained in the newer BCM2835/BCM2837 since the primary RTOS operating system contained in bootcode.bin and start_cd.elf has still to be loaded through USB, then the main CPU will be fully brought up and then later the secondary CPU core(s) will be booted through network after the VC4 loaded kernel, DT and initramfs from the remote location. And the whole stuff seems to be somewhat unreliable too.
Nice to play with but from an educational point of view I fear you learn almost only irrelevant stuff related to the VideoCore IV platform, its limitations and the limitations of USB in general. Close to nothing you could rely on with real clusters.
@tkaiser
Well, clusters of RPis are an important educational tool. You can program with OpenMPI and other cluster solutions that are popular in the industry since services need to scale now adays.
Also if you buy a big cluster of RPis, it’s headline news on many computer news sites.
@tkaiser
I’m assuming you’re only speculating regarding the next RPi in a couple of weeks. From what I’ve found online, the next one will come in 2019 at the earliest.
While I agree in general that’s not true for Pi Zero since here you almost only deal with the VC4 platform limitations (these things have no network at all). If you play clustering with RPi 3 as it’s done in large scale things might be a bit different but it’s still such a waste of money using these incapable devices for clustering especially if you keep in mind that all these RPi thingies need an Ethernet cable and an own switch port. Rack density is laughably low.
But it depends on the use case of course. Recently we learned that Los Alamos National Laboratory ordered sets of large RPi 3 clusters (that wasted half of the rackspace for cabling — too funny to be true) to help their staff building better nuclear weapons. Then using a bunch of slow devices with ultra slow USB networking (speaking about RPi 3) could better simulate real-world behaviour with 10GbE/40GbE/InfiniBand networking or whatever real clusters today use.
@Gabriel
This ‘RPi 4 in 2019’ thing is funny. The mythical Foundation spoke:
«”Raspberry Pi One lasted for three years,” Upton explained. “Then we had Raspberry Pi Two that lasted for a year, I think Raspberry Pi Three is more like a three-year product. We may tweak some peripheral bits of it at some point but probably not even that.”»
That’s it. Then journalists did some math 🙂
What’s on those Raspberries today is still the same as what BroadCom sold in 2010: the VideoCore IV running a proprietary RTOS. In the beginning there was one old ARM core added (BCM2835), then replaced with 4 ARMv7 cores (BCM2836), now 4 x Cortex-A53 (BCM2837). Still in 40nm, still the VC4 taking more die space than the ARM co-processors for the secondary OS even with 4 x A53: lb.raspberrypi.org/forums/viewtopic.php?f=63&t=189231#p1192295
VC4 hardware development is dead since a long time so how ‘innovate’ one more time? Add Gigabit Ethernet since the RPi community won’t realize that it’s crippled/crappy anyway. And in the meantime they prepare to loose their most important asset helping in founding that large community: backwards compatibility will break when having to move on to a new design (maybe in 2019, maybe earlier, maybe never)
@tkaiser
I was curious about the new Pi as I’m interested in getting a new one to act as a media player (with libreelec). After reading that the Pi 4 will not be out soon, I’m now looking at the Pi 3 and the Odroid C2. I know the C2 is better, but the Pi 3 will probably be enough and I’m assuming cheaper (will need to run the numbers).
@Gabriel
LibreELEC and then only on either BCM2837 or S905? Why not saving money, getting more memory bandwidth (necessary for higher video resolutions), better display features and better codec support as well?
If Gigabit Ethernet is not a must I would always choose S905X over S905 (and of course I would never choose VideoCore IV for anything graphics related today, it’s a 2011 design showing its age everywhere)
BTW and totally unrelated to the media player use case. RPi 3 and ODROID-C2 are the only known Cortex-A53/ARMv8 boards around that miss ARMv8 crypto extensions (AES encryption/decryption 15 times faster — but ok, that’s only stuff for people who want to run VPNs or full disk encryption)
@tkaiser
Most RPi fans buy RPi no matter if it’s compatible or not. The name is compatible. It’s the brand that matters. There might still be backwards support if Raspbian runs ARMv6 binaries compatible with RPi 1-4. The potential speedups from NEON, ARMv7 or AArch64 are insignificant for most users.
@tkaiser
Raspberry provides HDMI CEC. It’s not available with open source drivers on many other ARM platforms. The kernel API was just stabilized with little support from vendors. Most pirated video is still 8b color channel H.264. For many it’s time to switch to HEVC and 10b colors only when they’ll upgrade the TVs next time in few years.
@tkaiser
Cost is an important factor. I’d get the C2, but shipping from Korea is quite expensive and prices in Europe are rather high. I remember trying to find another S905X board, but don’t recall finding something at a decent price. I’m currently only playing 1080p/h264, no HDR. Because of that, its price and its availability, the Pi seems the most attractive option. But, as I’ve mentioned, I’d gladly get a S9xx, should I find it at a decent price.
And that’s the most funny part. No one is realizing how this backwards compatibility is defined. On the VideoCore IV there’s a main processor and that’s the VC4 itself. There runs also the main operating system having total control over the hardware. It’s a RTOS called ThreadX. RPi users are told it’s just a ‘firmware’ but it’s the OS that controls the platform (just check the issues after kernel updates that also required a fix in the ‘firmware’ later)
The ARM core(s) are just guest processors that can run independently a second OS like eg. Linux/Raspbian. A lot of hardware features and even hardware bringup rely solely on the VC4 part with the proprietary RTOS controlling everything. The kernels running on the guest processors have to take care about interaction with VC4/ThreadX and what happens in userspace (ARMv6, ARMv8, anything) is pretty much irrelevant except those binaries and libs that interact with the main part of the hardware, the VC4 (that’s stuff below /opt/vc and such tools as raspivid or omxplayer — those BLOBs below /boot like bootcode.bin or start*.elf are not included since those are the primary OS loaded by the main CPU called VC4 at bootup).
The platform is tight to VC4 and it’s not about user expectations (since as you correctly said the potential RPi customer is clueless in this regard anyway), it’s about the Foundation managing a seemless transition to another platform or not or how many more fairy tales they’re able to tell their users 🙂
Only a moron would buy a Raspberry tart
When for £29.99 including p&p you get box, power supply, remote, more ram, inbuilt emmc and working Android, sata.
https://m.geekbuying.com/item/Tronsmart-Vega-S95-Telos-Amlogic-S905-TV-Box-4K-2G-16G-AC-WIFI-Gigabit-LAN-SATA-Bluetooth4-0-XBMC-H-265-Miracast-OTA-359700.html
Better than a lame tart media player.
It’s really cool to see this happen. The boards are far too slow for my build farm unfortunately but I really like to see clusters like this being put in the hands of everyone, because it will encourage developers to start to think parallel again and start to wonder about the cost of sharing.
I have certain doubts about the ability of the jack connector to stand 15A without starting to melt to be honnest, so I guess it’s fine if you just have one or two boards and then it’s more convenient than the ATX PSU.
I thought there were switch chips with many RGMII ports so that they don’t have to install as many PHYs on board to talk to a switch but I failed to find one. I suspect it proves that making boards communicate directly on the same board via a switch is still something fairly recent and that switch vendors have not yet identified this opportunity.
Good job guys, it looks more serious than my MiQi-based build cluster 😉
The issue of support is rapidly changing if you are interested in running Linux on these boards. A whole lot of ARM code has gone into ARM support in 4.15 and much more is in line for later kernels. For the Odroid C2 it looks like they are now running a fairly stable kernel for exmaple, it isn’t perfect but they are getting there. Once you have mainline support I could see a proliferation of well supported ARM boards.
In other words I expect to see a rather massive shift where Linux actually runs well and fairly completely uses available hardware on ARM based boards. This may well happen before summer 2018.
@michael
Where? How much?
@michael
To clarify, I am asking about “Zeroes are available in volume – at another pricepoint than the single one.”
@Mike Schinkel
Pi zero with header : 2-20 units, 9.5 $ (ex Vat, ex postage)
Pi zero with WiFi, header : 2+ units, 13.2 $ (ex Vat, ex postage)
source: https://www.modmypi.com
(free uk delivery on orders over £50 ex.VAT – T&C’s apply)
If you need quatities >500 units contact RasperryPi
it just seems moronic to only include USB 2.0 ports on a base carrier board in 2018 when you know everyone and his dog
wants at least USB 3 on anything today if its to become actually a must buy in the home consumer DIY department, hell mini pci-E is the new must have even on £170 mini PC’s that people might actually buy as you can potentially upgrade some of the base components later…
as per GeeekPi Banana Pi R2 BPI-R2 Quad-code ARM Cortex-A7 SATA Interface Development Board
by GeeekPi £86.99 & FREE UK delivery
This is a cluster baseboard. The USB here is only used to facilitate manual intervention on the individual boards (eg: mounting a local FS or simple operations like this). There’s no need for performance here. You cannot compare this to your mini-PCs where the USB’s goal is to plug anything from external drives to keyboard or VGA adapters.
In fact I think that one cool thing on this board could have been to have one OTG port for each board, so that you can enable serial console or emulate ethernet over USB for debugging or ease of installation. But I don’t know if the SOPINE64 supports this.
I saw that Bootlin (previously Free Electrons) ported Linux (enough to boot, anyway) to a MicroSemi MIPS switch core. (https://bootlin.com/blog/free-electrons-contributes-linux-support-for-microsemi-mips-soc/). One of them has 10 RGMII ports.
(Bah, make that SGMII ports, I’m honestly not sure about the difference ¯\_(ツ)_/¯ )
Not bad at all. So in full configuration it does have 7×4 = 28 cores and 7×2 = 14GB of RAM. Not bad, but still a cluster of machines. I’d rather wait and see once SocioNext SC2A11 24-core board gets to market. This supports 24 core CPU already and RAM up to 64GB *ECC*. Yes, the core is slight slower but RAM is usable since it’s not divided into 2GB islands… Let’s see.
Anyway, thumbs up to creators for this board and its sweet low price…
@kcg
Math like these 7×4 = 28 cores and 7×2 = 14G are pointless. In the real world you need software which use each core separate, if the SoC design allows individual core use. Then does the SoC design handle chip heat by shuting cores off, or slowing them down.
People may use those Maths but it is not a real world model based on the SoC design or features..
/scratches head over this post
The software you’re referring to exists, and the ability of the SoC to sustain performance of all their cores is there, so I’m not sure what exactly you’re disagreeing with.
@blu
On Allwinner SoCs we have total control over all thermal and performance aspects. We can use any DVFS/cpufreq settings we want since on this platform no so called ‘firmware’ controls the ARM core behaviour but we ourselves with our settings and our software. So we’re not subject to a firmware cheating on us like it’s the case with all RPi or Amlogic devices but can use optimal settings and this even on a ‘per node’ basis.
We all know that those cheap SoCs vary a lot, some of them run fine at pretty high clockspeeds, some not. So default DVFS settings take care of this and add a huge safety headroom to prevent instabilities which in turn leads to default settings with DVFS OPP that are not optimal (using higher core voltages on all OPP, leading to higher temperatures and throttling happening more early).
But we have simple tools at hand in the meantime to let any Allwinner device run through an automated test parcours, testing for this individual chips limitations and then come up with an optimal DVFS/cpufreq table with only some limited additional safety headroom. Direct result: A cluster node after running through this test routine can from now on work with individual DVFS settings that can be stored also on the device itself (that’s the nice thing about Pine Inc. now everywhere putting at least 128 Mbit SPI NOR flash on every device).
So since with Allwinner devices we as users fully control the platform (and not the SoC vendor writing some firmware or those guys sitting in the ‘Pi towers’ and controlling RPi behaviour) we can do such optimizations and just by tuning each individual cluster node (only DVFS and thermal settings involved) might be able to improve overall cluster performance by 30% or even more and at the same time even increase lifetime expectations of individual cluster nodes since the less core voltage is used the better (until stability is affected).
This is all that’s needed: https://github.com/ehoutsma/StabilityTester (an NEON optimized Linpack benchmark that can be used to identify weak DVFS OPP, in fact this very same Linpack has been used almost two years ago to demonstrate that RPi folks shipped back then with broken DVFS settings for RPi 3 since they used core voltages too low at upper CPU clockspeeds which led to data corruption — needed a new ‘firmware’ since all RPi 3 are not under control of their users since everything hardware related runs on the primary OS on the VC4 for which neither sources nor documentation is available).
So unlike any RPi Zero clusters where you more or less only learn how to overcome the limitations of a crippled platform with this kind of cluster you can really learn for real clusters: how optimizing settings that deal with consumption, cpufreq, DVFS and thermal constraints can improve cluster performance a lot.
That being said of course Allwinner’s A64 is not the right chip for stuff like this (40nm process and needing a PMIC on every node) but if there’s interest in such solutions it would be rather easy for Pine Inc to provide another SoPine module with H6 on it which should perform much better under same environmental conditions (especially same amount of heat dissipation to handle)
Even if A64 isn’t the best choice for HPC it’s a great choice from an educational point of view since it’s really easy to learn with such a cluster attempt what’s important. Not talking about the ‘usual’ stuff here (like optimized MPI libs, compiler version/switches and stuff) but the basics below.
A64 due to it’s 40nm process throttles even with light loads (like stress, sysbench) and if really heavy stuff is running (eg. cpuburn-a53 which heavily utilizes NEON) then we’re talking already about throttling down to 600 MHz with a throttling treshold of 80°C on a rather large Pine64 board where the groundplane acts as heatsink too. Situation on a SoPine is much worse due to much smaller PCB.
So students dealing with such a cluster can learn valuable lessons and it starts at the physical layer already.
* Understanding/improving heat dissipation and reliability concerns: the whole SoM module will heat up with constant load so designing an efficient heatsink able to dissipate as much heat as possible away from the module is important. Most probably something attaching to DRAM, SoC and PMIC will be most sufficient
* Again heat dissipation. Design optimized airflow inside an enclosure with some 3D printed parts to increase airflow over the heatsink’s surface
* Understand DVFS (dynamic voltage frequency scaling) and it’s impact on both performance and reliability. Test and develop automated routines to determine each individual A64’s DVFS limits to minimize both consumption and heat on a per node basis. Learn how to store this individual DVFS table on the module’s SPI NOR flash
* Understand the importance of good DVFS/cpufreq/throttling settings: eg. provide as much DVFS/cpufreq OPP as possible since if the cpufreq/throttling code does large jumps (eg. all the time between 720 MHz and 1200 MHz instead of being able to settle at a stable clockspeed in between) performance sucks. AFAIK these optimizations currently do not exist with mainline kernel but only the community version of Allwinner’s legacy kernel. So there’s plenty of work to be done to get better performance once throttling occurs
And then as a result of all these learnings develop a simple PXE boot based system that allows to add new cluster nodes that then start into such a ‘calibration’ + ‘burn-in test’ routine, iterating first through DVFS/throttling test routines to determine an optimal DVFS table and then confirming this with a 24h reliability testing. Only afterwards the module automatically joins the pool of active cluster nodes.
On a ‘per device’ base we’ve seen that such rather simple optimizations have a huge impact on performance. In a cluster setup then there are some additional challenges like heat dissipation in enclosures and optimizing overall consumption at the same time (since adding tons of 20k rpm fans that consume more than a cluster node under load would be a rather stupid attempt for these sorts of clusters)
there’s the problem , right there, “There’s no need for performance here”
given that all so called developer boards as per this carrier board etc, are in fact sold on the premise that they have “potential” real world uses “You didn’t account for”, and so the very reason today’s home DIY consumer will buy them on mass or not, then any producer is artificially limiting this actual sellable “potential” as artificially bottlenecking the actual sodimm SOC generic IO with antiquated USB2 when for the same price you can use USB3 at least (potentially usb3.1 OC) and make the product actually sellable and usable today…
“mounting a local FS or simple operations like this” such as mounting a cheap 4 terabyte 2.5 drive per A64 modules at crippled USB2 data rates ,as opposed less cripped USB3 , sure wouldn’t want to remove the artificial bottleneck with better generic usb would we…
do you work for the antiquated ethernet or cable STB conglomerates that insist on everything be lowest specs hardware for the job of cripping the end consumers options ??? that would explain the its good enough ( when it’s never really good enough even before its speced for a home consumer ethernet/cable network use)
as for “so that you can enable serial console or emulate ethernet over USB for debugging or ease of installation.”
you dont need to “emulate” anything , the ethernet spec doesn’t care what it travels over so just look up and use the existing “usbnet” and other related Ethernet-over-USB kernel modules…
see https://en.wikipedia.org/wiki/Ethernet_over_USB
http://www.linux-usb.org/usbnet/
due to the artificial limiting of these carrier boards above you obviously can’t do ethernet over USB3 with these , but you may want to also buy for instance the “StarTech.com USB 3.0 Data Transfer Cable for Mac and Windows – Fast USB Transfer Cable for Easy Upgrades including Mac OS X and Windows 8” cable https://www.amazon.co.uk/StarTech-com-Data-Transfer-Cable-Windows/dp/B00ZR1AD4A Price: £31.48 Delivery at no additional cost for Prime Members and use that on real USB3 capable linux devices rather than buy second hand ( equivalent to Oxfam’s Online used Shops
hopefully without the old people smell 🙂 high power use 10Gigabit kit including 10Gb router etc
@tkaiser
That’s a good idea for a course right there!
@Pfsense hardware Barebones
In fact all you describe here is a bunch of individual boards. You’re really looking for a rack of many independant boards with a unified power supply, not a cluster.
The purpose of a cluster is to have to do the least possible work on any individual node. usbnet makes no sense here as it would require interconnection with another device. It could however be useful for the initial setup of the boards. Installing a SATA drive on each board doesn’t make much sense except for booting, which is equally served using a cheap 8GB flash.
It could make sense to want to use this to build storage clusters but the gigabit on each board would hurt the ability to make full use of the USB3 or SATA performance anyway.
So you’re really left with a compute cluster, and the product pretty well fits the purpose. At a very appealing price in addition!
Some nice improvements would include having a few more boards, having a 10G port on the switch, and supporting higher frequency CPUs. But at least it exists like this and that’s really cool.
If you want something a bit faster and not requiring too much external hardware, take a look at the nanopi-fire3.
The boards are well designed and can easily be installed vertically next to each other. You’ll get 8 A53 at 1.4 GHz on each board. You’ll need ethernet cables and a switch (in this case you can use a 1/10G switch). You will still need to bring your own power supply and you will still not have USB3.
@blu
The point is Math like these 7×4 = 28 cores and 7×2 = 14G are pointless
Just imagine we could change the SoC on the compute modules but keep memory etc the same and we could also mix 64 bit and 32 bit
A64, Math 7×4 = 28 cores and 7×2 = 14G
S905, Math 7×4 = 28 cores and 7×2 = 14G
S905w Math 7×4 = 28 cores and 7×2 = 14G
RK3328, Math 7×4 = 28 cores and 7×2 = 14G
S812, Math 7×4 = 28 cores and 7×2 = 14G
S805, Math 7×4 = 28 cores and 7×2 = 14G
Rk3229, Math 7×4 = 28 cores and 7×2 = 14G
H5, Math 7×4 = 28 cores and 7×2 = 14G
H3, Math 7×4 = 28 cores and 7×2 = 14G
H2+ Math 7×4 = 28 cores and 7×2 = 14G
So other than adding up cores and giving a total count of memory. The maths tell you nothing about the actual performance the SoC would give you! Now you might say but I also know the detail working of these SoC so I can guess, assume or theories how they will perform, but the maths formula above still does nothing to filter, grade or differentiate the SoC list. It does not even recognise each board has only 2G.
Pine Inc can. And most probably they will. Maybe you’re able to do the math yourself: RK3399 means not ’28 cores and 14GB’ but ’42 cores and 28GB’. This is all potential customers with specific use cases are interested in (eg. serving dynamic web pages behind a load balancer). But such a big.LITTLE design would also be great for educational purposes to study performance behaviour if you pool all CPU cores or separate the A72 from the A53.
But even better: With RK3399 you could use OpenCL 1.2 so this might also be great to explore GPGPU clustering. And in the 2nd half of 2018 then pin compatible RK3399Pro can be put on the SoM with a NPU (Neural Network Processing Unit) reaching 2.4TOPs per node.
BTW: @blu was telling you that cluster software exists (since ages!) and that what you call ‘SoC design’ is software in reality (‘shutting down CPU cores’ vs throttling and stuff).
Why would we want to keep memory the same? Since we’re clueless or even stupid? The 2GB DRAM used here are a reasonable default with A64 since while this chip is able to address up to 3GB you would need to waste a 4GB module for this (with Allwinner’s H6 it’s the same and in fact that’s what Pine Inc do on the PineH64 board: the 3GB variant has a 4GB LPDDR3 module on it so 1 GB wasted).
But when choosing other SoCs of course the amount of DRAM will be set to the upper reasonable limit. And that’s currently 4GB with Rockchip SoCs. And there are a lot of use cases that directly benefit from more DRAM, there are even some trends in computing (virtualization, containerization, preferring crappy software over good one) that drive demand for DRAM.
But ‘crappy software’ is the best reason to cry for better hardware (‘design’ principle: do not fix the problem but throw more hardware on it). For example most probably the worst way to build desktop applications is to use Javascript, bundle it with Node.js and Google’s V8 engine contained in Chromium since this is not only a great way to ruin performance and increase hardware requirements insanely but also to generate totally insecure software. Today’s developers love this.
Developers^W Lazy people like such attempts and as such Node.js combined with fancy frameworks is trending. It’s a great way to generate insanely bloated software in no time. Combine npm with angular/cli and generate a simple ‘hello world’ example:
The resulting skeleton contains 31 direct module dependencies, 974 total dependencies and the node_modules directory is 305 MB in size (containing 158 duplicate packages with other version numbers due to different dependencies). Needless to say that this is not only bloated on disk but also great in wasting ressources, eg. memory needed. People love it. And need more RAM in their servers.
You were talking about ’64 bit and 32 bit’ for whatever reasons but here comes the fun part: Node.js users on ARM should choose a 32-bit SoC over a 64-bit SoC for the simple reason that the 32-bit binaries need magnitudes less memory and RAM is always an issue with this type of computing. This does not only apply to laughable slow ARM devices like the ones we’re talking here about but also to the beefy Cavium servers or those from Socionext, Qualcomm or whoever else starts ARM server business lately.
Can Node.js users simply combine a 64-bit kernel with a 32-bit userland (since RAM requirements drop down to approx. 60% with almost no performance loss)? No, they can’t since this is a matter of ignorance: https://github.com/nodesource/distributions/issues/375#issuecomment-290440706
So while it’s well known that Node.js on ARM with a 32-bit userland you can run almost twice as much instances per server ‘industry professionals’ ask for the opposite (see the Github issue above, it’s really bizarre)
So it needs students with stuff like this clusterboard in their hands exploring memory requirements with different types of userlands. The obvious result (use a 32-bit userland on ARM with the majority of server and cluster use cases since due to lower memory requirements more tasks can run in parallel and so overall cluster/server performance increases even if individual tasks take a little bit longer) then results in a paper… and then maybe something will change.
But not only this example of studying how to improve memory utilization is worth a look. Exploring ways to better make use of physical memory could also be very interesting (memory overprovisioning or in memory compression techniques like eg. zram). This is educational stuff since the industry is obviously not interested. They only improve in using more shitty software on almost a daily basis and buying more cloud instances to compensate for their ‘designs’s inefficiency.
The point is that as long as your software is ok with the single-core latency characteristics of an A53, and scales (near) linearly with threads, the metric ‘N cores of a proverbial average A53’, is perfectly reasonable way to say ‘I expect N times the performance’, and low and behold, get that performance at the end of the day. Now, from all accounts (and as thoroughly explained by @tkaiser), A64 cores are well-managed — DVFS yields predictable performance, at minimal airflow effort. So using that for clustering solutions is all well defined and predictable.
@tkaiser
You have made two long and elegant posts there but I see you do not get or have not understood my argument against just adding number of cores together and adding amount of memory together, as a means to grade systems. However your long elegant and detailed posts support my argument point nicely.
Thank you
Tkasier
You obviously are not able to differentiate between your Android / Desktop world and server/cluster use cases (and I doubt it will change even if @blu takes a third attempt). But this doesn’t matter at all since I simply wanted to outline in which areas working with this specific cluster board and the SoPine modules is worth the efforts from an educational point of view (and that’s what Pine Inc.’s TL Lim always emphasized on when the idea for such a clusterboard was born in late 2016 — education)
What we look at is a docker swarm home lab for the rest of us, ready for exploring various use cases in a safe but experimental environment, where bare metal deployment in a data warehouse is yet too costly and unsafe. Running the same containers at home or in the cloud with an excellent cost-performance ratio could make arm64 clusters replace lower end vps and kvm virtualisation not only because of speculative branching and vm exploits. A qubes os without virtualisation.
R353/R371 – are those 15W resistors on the clusterboard schematics and preloading the ATX power supply? Really?
Some ATX power supply needs to sense a load to power up and these 15W resistors are use as dummy load. However, most modern ATX power supply that we tested able to power up without dummy load.