
Just a couple of days ago, Amazon introduced EC2 A1 Arm instances based on custom-designed AWS Graviton processors featuring up to 32 Arm Neoverse cores. Commenters started a discussion about price and the real usefulness of Arm cores compared to x86 cores since the latter are likely to be better optimized, and Amazon Web Services (AWS) pricing for EC2 A1 instances did not seem that attractive to some.
The question whether it makes sense will obviously depend on the workload, and metrics like performance per dollar, and performance per watt. AWS re:Invent 2018 is taking place now, and we are starting to get some answers with Amazon claiming up to 45% reduction in costs.

It sounds good, except there’s not much information about the type of workload here. So it would be good if there was an example of company leveraging this type of savings with their actual products or services. It turns SmugMug photo sharing website has migrated to Amazon EC2 A1 Arm instances. Their servers run Ubuntu 18.04 on 64-bit Arm with PHP, Nginx, HAProxy, Puppet, etc…, and it allegedly only took a few minutes to compile some of the required packages for Arm.

So at least they managed to migrate from Intel to Arm with everything running reliably on SmugMug website. But how much did they manage to save? Based on the slide below, costs went down by 40% per core for their use case. Impressive, and they also claim running Arm instances feel the same as Intel instances. Having said that, I find it somewhat odd to use “per core” cost savings, as for example if they went from 16-core Intel instances to 32-core Arm instances both going for the same price, the Arm instances would be 50% cheaper per core, assuming similar performance.

Phoronix also ran benchmarks on Amazon EC2 A1 instances, and here the results are quite different. As expected Intel or AMD based systems are still much faster in terms of raw performance, but if you expected a performance per dollar advantage for Arm instances, it’s not there for most workloads.
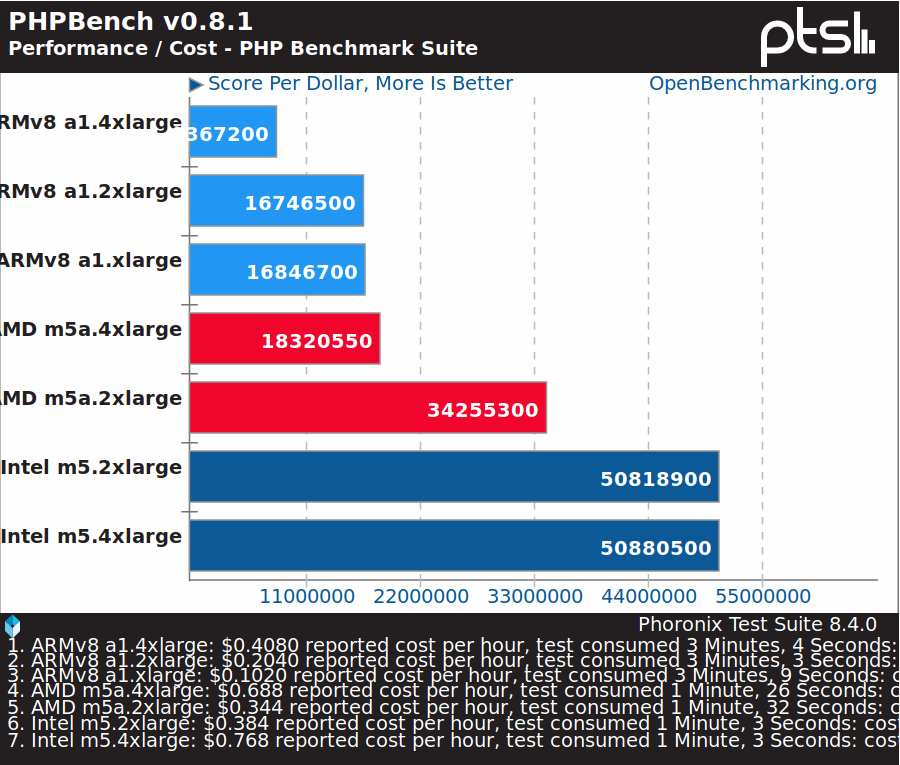
PHP runs on many servers, and you’d expect Arm to perform reasonably well in terms of performance per dollar, but some Intel instances are nearly three times cheaper here.
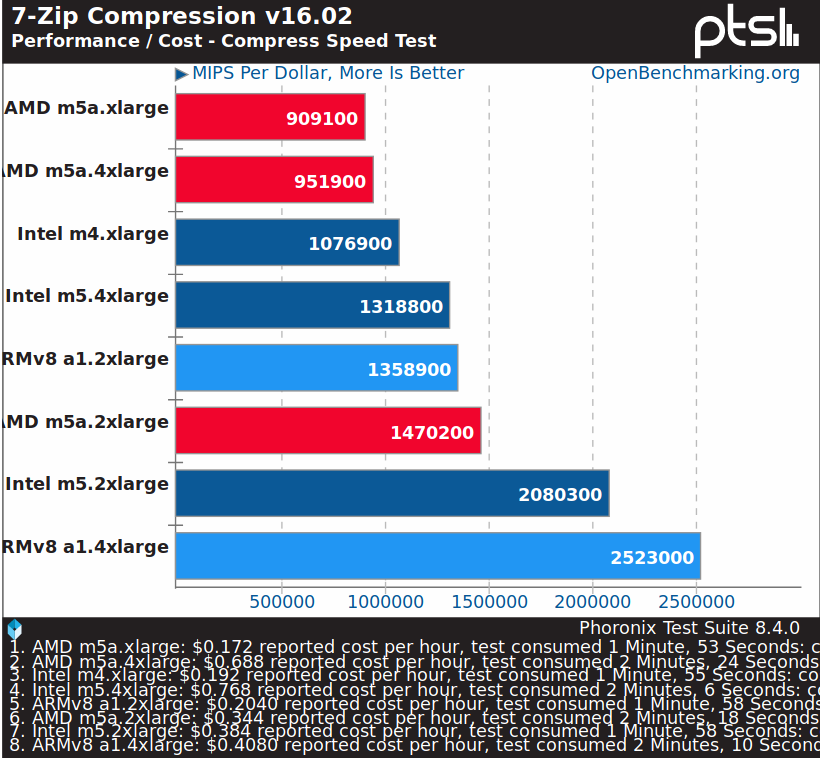
7-zip compression benchmark is one of the rare benchmarks were an Arm instance deliver a better performance/cost ratio than competing offerings. This lead Michael Larabel to conclude “at this stage, the Amazon EC2 ARM instances don’t make a lot of sense”.
My conclusion is that whether Arm instances make sense or not highly depends on your workload.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



EC2 A1 instances presentation slides for re:invent 2018
https://www.slideshare.net/AmazonWebServices/new-launch-introducing-amazon-ec2-a1-instances-based-on-the-arm-architecture-cmp391-aws-reinvent-2018
BTW, I can attest to the bare-metal-like performance mentioned on slide 11 — I was really surprised to see vCPUs doing so close to metal on tasks with some io (for reference — better than the VM in chromeos)
Details for the 45% saving are a must if you want to take it seriously.
My guess looking at the phoronix benchmarks is that they had many many x86 instances that were far bigger than they needed and they were pouring money down the drain for the sake of having each layer of their stack running in a different instance.
Or Amazon gave them a massive amount of coupons for being an early adopter. 😉
I’ve just realized the 40% cost savings for SmugMug is per core, not overall cost savings. So the actual savings are hard to predict/guess. I’ve updated the post to reflect that.
Thanks for removing any guilt about sticking with Intel.
We still have no info about the core’s frequency, memory bandwidth nor I/O bandwidth. I wouldn’t be surprised at all if these instances were really interesting for network-bound workloads. Today it’s normal to saturate a 10 Gbps link with TCP traffic using a single A72 core, and for this type of workloads you don’t need to pay more than the smallest cores they can provide you, but ideally you’d want real cores and not something that gives you 1 millisecond of CPU every once in a while. I know people who have left AWS because of extreme costs for the… Read more »
> We still have no info about the core’s frequency, memory bandwidth nor I/O bandwidth
At least memory latency isn’t bad, see the Phoronix 7-zip numbers (maybe the only number generated that’s not totally meaningless for this type of system comparison).
Take it with some salt, particularly the latency times, as run’s from an a1.medium single-vCPU instance: $ ./tinymembench tinymembench v0.4.9 (simple benchmark for memory throughput and latency) ========================================================================== == Memory bandwidth tests == == == == Note 1: 1MB = 1000000 bytes == == Note 2: Results for 'copy' tests show how many bytes can be == == copied per second (adding together read and writen == == bytes would have provided twice higher numbers) == == Note 3: 2-pass copy means that we are using a small temporary buffer == == to first fetch data into it, and only… Read more »
And the clocks from the same instance:
$ ./mhz 16
count=1008816 us50=22074 us250=110548 diff=88474 cpu_MHz=2280.480
count=1008816 us50=22064 us250=110458 diff=88394 cpu_MHz=2282.544
count=1008816 us50=22161 us250=110518 diff=88357 cpu_MHz=2283.500
count=1008816 us50=22166 us250=110488 diff=88322 cpu_MHz=2284.405
count=1008816 us50=22102 us250=110558 diff=88456 cpu_MHz=2280.944
count=1008816 us50=22138 us250=110595 diff=88457 cpu_MHz=2280.918
count=1008816 us50=22087 us250=110558 diff=88471 cpu_MHz=2280.557
count=1008816 us50=22109 us250=110535 diff=88426 cpu_MHz=2281.718
count=1008816 us50=22151 us250=110420 diff=88269 cpu_MHz=2285.776
count=1008816 us50=22138 us250=110518 diff=88380 cpu_MHz=2282.906
count=1008816 us50=22156 us250=110444 diff=88288 cpu_MHz=2285.285
count=1008816 us50=22153 us250=110487 diff=88334 cpu_MHz=2284.094
count=1008816 us50=22162 us250=110477 diff=88315 cpu_MHz=2284.586
count=1008816 us50=22169 us250=110525 diff=88356 cpu_MHz=2283.526
count=1008816 us50=22158 us250=110457 diff=88299 cpu_MHz=2285.000
count=1008816 us50=22121 us250=110537 diff=88416 cpu_MHz=2281.976
Here are some SIMD (GEMM) results as well (^f Graviton): https://github.com/blu/gemm/blob/master/README.md
And of course brainfuck results (^f Graviton):
https://github.com/blu/brainstorm/blob/master/README.md
> My conclusion is that whether Arm instances make sense or not highly depends on your workload. And that’s the only reasonable conclusion. Fun anecdote, yesterday at work I did a quick-n-dirty port of a compute unittest to my CA72 chromebook – at first it started at a significantly lower normalized per-core perf compared to my desktop xeon, but 10 minutes of fixings later it was doing the per-clock per-core prformance of my workstation. The reason I’m sharing this it to demonstrate it takes a bit more than a successful compile to get the most out of another architecture (and… Read more »
> generic benchmarks of the phoronix kind often miss that And that’s just one problem with this Phoronix stuff (generating random numbers due to different compiler flags and (missing) optimizations chosen on some platforms vs. another). The more severe problem with Phoronix is generating wrong conclusions all the time. Just take his first ‘benchmark’ using PHPBench for example. This is a single threaded set of 56 different tests checking some PHP related performance aspects (some influenced by CPU performance, some more by memory performance — no idea whether IO also interferes). The only insight this benchmark will provide is whether… Read more »
Your post made me actually go carefully through the phoronix article, and this is .. benchmarking gone terribly wrong.
As I always put it: “there are lies, damned lies and benchmarks” ….
Benchmarking done right is actually helpful, but that normally takes way more effort and knowledge than what was put in the majority of benchmark figures out there.
The only way to do benchmarking right is to openly announce what you’re measuring (and why you believe your method is reasonably relevant). I do benchmarking all the time on haproxy, at least to measure the impacts of certain code changes. It definitely is a requirement. But I’m well placed to know that it’s possible to make your benchmarks say what you want them to say, even by accident, using your own bias, because the same method cannot be used all the time and need to evolve to take new possibilities into consideration. In my opinion, the goal of the… Read more »
I agree. I profile and benchmark the wazoo out of everything that I find remotely interesting, not simply because it’s my job, but because I find performance awareness fundamental to most things we do in computing. That said, I find most benchmarks that yield a number without looking at the reasons to that number, well, not that useful.
>blu Hand optimising stuff is impractical for most people. If you have time to mess around optimising your whole stack like that you might as well fire a dev and hire a sysadmin to deploy your stuff on dedicated servers that are about a fifth of the price of AWS. >tkaiser Whether the numbers are very good or not doesn’t really matter here as long as the tests are like-for-like. The claim from Amazon that it’s 45% more cost efficient. If that were true/generally applicable even bad benchmarks would reflect that in someway but they don’t. The benchmarks show the… Read more »
> The claim from Amazon that it’s 45% more cost efficient. If that were true/generally applicable even bad benchmarks would reflect that in someway but they don’t. While I really don’t care about Amazon’s claims I think by carefully looking at what Michael Larabel provided it’s obvious that these ARM instances perform pretty well if it’s about a ‘performance / cost’ ratio. Of course this requires dropping the 100% BS ‘benchmarks’ (like Apache Benchmark executed in most stupid ‘fire and forget’ mode possible) and where his whole methodology is completely flawed (using single-threaded PHPBench and PyBench numbers for multi-core server… Read more »
>these ARM instances perform pretty well if it’s about a ‘performance / cost’ ratio How? You pay for time on AWS. The ARM instance used is $.4 an hour and an X86 with half the cores is $.33 an hour. Even if your application scales perfectly and can utilise every core on the ARM instance the X86 is still producing more work in an hour, for $0.07 less with less latency. A dedicated server that does the same amount of work costs $0.1 an hour so either AWS instance is actually expensive for the work produced. >using single-threaded PHPBench and… Read more »
> There’s no way of benching marking how well every application will scale so the best you can do is take the single threaded number, multiply it by the number of cores and then by some faction to factor in that it’ll never fully utilise all of of the cores And now look at the Phoronix numbers that simply forgot to ‘multiply it by the number of cores’. That’s my whole point. Michael Larabel generating fancy graphs based on numbers without meaning and people looking at them and thinking ‘damn right, this other platform sucks’. The most simple performance metric… Read more »
>The most simple performance metric I use for ‘general server workloads’ >is simply 7-zip since this workload depends on CPU and memory performance > in reasonable ways. I don’t know many people running 7-zip-as-a-Service.. but anyhow presumably the performance there is good because there is an optimised filter for armv8. That’s the only benchmark to shows that the ARM instances could get better. There is hope at least. Whether or not that optimisation happens for whatever you’re using is another question. >None of this happens in Phoronix land — instead this totally misleading BS gets published… The benchmarks are mostly… Read more »
> I don’t know many people running 7-zip-as-a-Service None I would assume. But that’s not the point. It’s about how to get a quick idea about the performance to be expected based on a certain workload. And for ‘server tasks’ without taking IO into account not just me found that 7-zip is working fairly well to get a rough estimate. It’s also not that dependent on compiler versions unlike a lot of other popular benchmarks and it provides a routine calculating CPU clockspeeds comparable to Willy’s mhz tool. See the ‘CPU Freq’ line below: 7-Zip (a) [32] 16.02 : Copyright… Read more »
I think the 7-zip result being so good is highly dependant on it being optimised for ARMv8 so I’m not sure if that’s a good bench mark for general performance i.e. for any old package I would install in ubuntu. If PHPbench is throwing random bits of PHP at the interpreter and working through a lot of it’s code then that would be a better representation of overall performance. Benchmarks need to be taken with a pinch of salt of course. I’m sure the difference isn’t actually that bad but based on what I’ve seen I’m not convinced it’s anywhere… Read more »
> So unless you need to run ARMv8 code what’s the point? That I’ve yet not seen any such ‘performance / cost’ comparison of different AWS platforms. The Phoronix stuff at least is fundamentally broken (especially the ‘performance / cost’ calculations that generate pure nonsense numbers since using single-threaded performance scores on multi-core instances without taking exactly this into account. The other flaw is missing accuracy when calculating costs due to working with only two decimal places) BTW: 7-zip seems not to be optimized in any special way. At least this is one of the reasons why I use it… Read more »
> Hand optimising stuff is impractical for most people. Most people don’t have a use case for running anything in the cloud, and yet here we are discussing clouds. And I surely have time ‘to mess around optimising the whole stack’ (hint: the whole stack does not need optimisation — bottlenecks do) — that’s what I’m being paid for to do at my job. Likewise with the Cloudflare usecase which got publicity recently — they surely had time to optimise their stack, and oh, miracle! — they had material benefits to reap. > If you have time to mess around… Read more »
>they surely had time to optimise their stack, and oh, miracle!
A big industry player that could save millions of dollars from saving fractions of a cent has the time to do it. Amazing. Who would have thunk it. It’s almost like you couldn’t come up with an example for an average AWS user so had to come up with something that isn’t even in the same ball park.
@dgp
If you’re not going to bother reading past the first paragraph then I’ll not bother responding to you. As per usual, enjoy your day.
I read your whole post. You keep bringing up stuff that makes no sense here; This is being pushed as being cost effective i.e. not for the people that need hundreds of cores and have a whole team of ARMv8 architecture experts on $300K or more a year. Those people don’t care about what cloudflare are doing for ARMv8. Those people use cloudfare etc because they don’t want to need to care. You do a lot of hand-wringing to explain why ARM is so great like it’s a personal friend you need to protect and at the same time a… Read more »
> Which cloud customer would be that stupid to move workloads that do not scale whatsoever into the cloud? What’s the purpose of pulling in such single-threaded numbers into ‘Performance / Cost’ comparisons for multi-core systems at all? While I would generally agree, the problem with clouds is that the guy who decides on the migration decides to do it because he heard they’re using PHP or whatever that scales well, but that there are a number of satellite components around that do not scale this way at all that he hasn’t heard of but that are mandatory. Then it’s… Read more »
> it definitely is important to know how it works for single-threaded workloads
But neither is PHPBench telling you about overall performance for single-threaded workloads nor should such a single-threaded ‘score’ be used for ‘performance / cost’ ratios when judging about multi-core instances. It’s simply the wrong tool used in the wrong mode(s).
This kitchen-sink benchmarking the Phoronix style is terribly misleading and there’s no alternative other than testing your own workload after switching on your own brain to generate insights and not just funny numbers and colored graphs.
But does it not also depend which bucket ( container ) and instance is chosen. There are three types, each with different aims? When use Amazon web services.
The term “up to” is always misleading ….. as in “up to 65% of women saw an improvement with L’Oreal Paris Age Perfect”
Thanks for coming back with this piece. It’s a shame that right now it seems these instances don’t offer more bang for your buck but I wonder how much of that can be changed with compiler optimisations. I work mainly in Golang these days which works on ARMv8 but if this blog post from cloudflare (https://blog.cloudflare.com/arm-takes-wing/ ) is still accurate, doesn’t work well due to missing optimised assembly that doesn’t take much effort to add. It’d be interesting to spend a weekend hacking on it and see how far performance can be pushed.
> It’s a shame that right now it seems these instances don’t offer more bang for your buck
On which numbers is this based?
>On which numbers is this based? Cheapest ARM instance: a1.medium 1 NA 2 GiB EBS Only $0.0255 per Hour Comparable X86 instances: t3.small 2 Variable 2 GiB EBS Only $0.0208 per Hour t2.small 1 Variable 2 GiB EBS Only $0.023 per Hour a1.medium1 has to perform better than t2.small to be any more cost effective. a1.medium1 has to perform twice as well as t3.small on a theoretical load that scales perfectly to multiple cores. The *bad* phoronix benchmarks say that’s only the case for 7zip. Some better benchmarks like those here: https://www.servethehome.com/putting-aws-graviton-its-arm-cpu-performance-in-context/ make it look less hopeless but not much… Read more »
> a1.medium … t3.small … t2.small Hmm… I’ve not seen any benchmarks for a1.medium so far so no idea how to compare exactly. > The *bad* phoronix benchmarks say that’s only the case for 7zip. And for ‘Rust Mandelbrot’ (or more generalized: when multi-threaded results have been used) . But the whole ‘performance / cost’ methodology Phoronix uses is so weird that I really don’t understand why it’s mentioned anywhere else. You can’t use single-threaded scores for server instances with multiple vCPUs without multiplying the count of cores somehow in. ‘Forgetting’ this renders the whole ‘performance / cost’ ratio 100%… Read more »
Yes, the phoronix stuff is garbage. I get that. I intentionally linked a whole new set of benchmarks to get you off of the phoronix stuff. Take a look at the pricing: https://aws.amazon.com/ec2/pricing/on-demand/ These can only be cost effective if you need one of the core count/ram amounts that they don’t have an X86 configuration of. So going full cycle again: Any cost savings you have will not be because of magic ARM powers but because you can move to an instance that fits your work load better (number of core/ram) and/or you had too many under used instances in… Read more »
> I intentionally linked a whole new set of benchmarks to get you off of the phoronix stuff Yeah, but how should the servethehome.com link help with getting a comparison with cheap Amazon Intel instances? I’ve no idea how those behave wrt performance and how much this might change with further Meltdown/Spectre mitigations. Anyway: let’s stop here. My whole point here was the shocking experience that people for whatever reasons believe into the Phoronix garbage that is fundamentally broken in so many ways… Time will tell how performance/cost ratio with these Amazon A1 thingies will look like. And while I… Read more »
>Yeah, but how should the servethehome.com link help >with getting a comparison with cheap Amazon Intel instances? The benchmarks show these ARM cores are not as fast per core (across the board on synthetic benchmarks) as the Xeon etc cores used for the X86 instances. They aren’t as fast as other ARMv8 cores either. I suspect these are considerably cheaper for Amazon to run (maybe not for a few years until the R&D spend cancelled out) and that’s great for them but their customers are paying in units of time and not work performed so the more work done in… Read more »
> These can only be cost effective if you need one of the core count/ram amounts that they don’t have an X86 configuration of This is a pretty valid point. Their pricing *seems* to be done to protect their x86 investment, since an equivalent-class (but slightly faster) ARM systematically is slightly more expensive than the x86. Thus unless you’re certain to use it at 100%, you can cut costs by using the cheaper x86 at a higher %CPU. In short, CPU-wise, their offering is mostly interesting for batched processing where you’re certain to use your ARM at full load. Maybe… Read more »
> Since if we want to calculate ‘MIPS Per Dollar’
Please note that one important metric often is “peak MIPS for a given dollar” : the smallest amount of time it can take to complete a task. That’s where x86 usually are interesting because they offer higher peak MIPS than anything else, at 1.5-3 times the price of the slightly smaller option. But some people are willing to pay the price to get this and it’s fine.
>these instances don’t offer more bang for your buck At least there is one apparently sane person here. >doesn’t work well due to missing optimised assembly that doesn’t take much effort to add. I wouldn’t underestimate it. The fact that that the optimisation is missing points to it being less than trivial to implement. If Amazon are really serious about this stuff they should already be working making the common stuff like Python, PHP, Java, Go etc work as well as possible on their platform. Maybe in a year or so they’ll fix the pricing or considerably improve the performance… Read more »
Quote from Phoronix.com ” At this stage, the Amazon EC2 ARM instances don’t make a lot of sense… Well, barely any sense unless you want scalable, on-demand access to ARMv8 computing resources for a build farm, ARM software debugging/testing, and related purposes. The performance of the Graviton processors powering the A1 instances came up well short of the comparable M5 general instance types with either AMD EPYC or Intel Xeon processors. Even with the cheaper pricing, the performance-per-dollar was still generally just on-par with the equivalent or slightly better than the Intel/AMD offerings. Only in the few threaded workloads where… Read more »
A more simplistic benchmark approach:
https://www.youtube.com/watch?v=KLz8gC235i8
His benchmark is crude and again he’s saying “cheaper cheaper cheaper” when he’s comparing an X86 instance with 32GB of ram to one with 16GB of ram.
That’s a perfectly normal result for properly optimised (integer) code not giving precedence to one arch or another. Keep in mind small code is easier brought to that state, compared to arbitrary collections of 3rd party libraries and frameworks that usually constitute software packages. But this is where library (and full stack) providers come in.
>compared to arbitrary collections of 3rd party libraries and frameworks
You see to have poor reading comprehension. This is exactly why I said it’s crude. But hey, it’s a single benchmark that shows that these things aren’t total lemons. That’s a massive win for you. You can sleep well tonight.
Shame the pricing is still garbage and makes no sense.
And FYI he’s benchmarking 8 threads on the X86 vs 8 real arm cores and the ARM just barely wins.
So on raw performance these things are lemons.
> You seem to have a reading comprehension.
..Says the guy who couldn’t figure out I was not replying to him.
It looked nested to me so I apologise. Other than that what I wrote still stands and no one has come up with any numbers to prove these are more cost efficient.
> no one has come up with any numbers to prove these are more cost efficient Maybe no one here works for Amazon’s marketing department (only they are interested in proving exactly this). As already said: time will tell how this will look like in the wild. I think we’re talking here in one comment thread about a bunch of totally different things at the same time. * benchmarking gone wrong (especially some totally flawed methodologies –> Phoronix) * platform/code optimizations (blu) * performance/cost ratio (you) At least I’m only interested in these ARM AWS instances since I still have… Read more »
>* benchmarking gone wrong (especially some totally flawed methodologies –> Phoronix) * platform/code optimizations (blu) * performance/cost ratio (you) These are all related. You need benchmarking to see if this worth bothering with. Optimisations might help close the gap if it’s close and the actual cost is dependent on both of those points. >I still have some hope that with this marketing hype around ARM as server platform Why does it have to be ARM though? I like ARM stuff but not because it’s ARM but because you can buy chips that have good enough performance for what most jobs… Read more »
> Why does it have to be ARM though? Since there are no competitive SBC and embedded devices with other architectures around. I said it already multiple times: I’m not interested in running anything on these ARM or other AWS instances (quite the opposite). My only interest in these server instances and the fresh hype around is the potential for software optimizations that might now happen (sooner) so I can benefit from on all my other ARM devices. I don’t give a sh*t about the performance / cost ratio of any of these AWS offers since I do not want… Read more »
>potential for software optimizations that might now happen (sooner) >so I can benefit from on all my other ARM devices. >I don’t give a sh*t about the performance / cost ratio of any of these AWS offers >since I do not want to run anything there or in some other ‘cloud’. These two statements are contradictory. You might not want AWS instances personally but if they are not cost effective no one will use them, they’ll die on the vine like all of the other efforts to get ARM on the server to be anything but very niche custom hardware.… Read more »
This is exactly the same BS like using sysbench --test=cpu to test for CPU performance. And it gets totally weird when bringing in the RPi at https://youtu.be/KLz8gC235i8?t=378 — the reason why the RPi can’t compete here is since the Cortex A53 on the RPi are brought up in 32-bit state and this prime number calculation stuff then uses other instructions. Use 64-bit kernel/userland on the RPi (using pi64 https://github.com/Crazyhead90/pi64/releases ) and it will run 15 times faster with this terribly useless benchmark. But that’s not due to architectural differences between the ARM cores on the RPi and those on these… Read more »
The guy is trying to show A1 to the uninitiated (youtube) masses — I think he’s far from any claims of usefulness or cloud usage practicality, which is further backed by his seemingly random inclusion of the RPi, as you note.
ps: it’s Annapurna ; )
> The guy is trying to show A1 to the uninitiated (youtube) masses But his conclusions are totally wrong and simply demonstrate the mess. People not understanding that benchmarks always test software. The primitive benchmark he chose does not perform better due to being run on a ‘proper server chip running in a huge configuration with lots of memory and lots of caches and all the stuff they need’. In fact his flawed benchmark does not depend on ‘lots of memory and lots of caches and all the stuff they need’ at all but runs entirely inside the CPU and… Read more »
>But his conclusions are totally wrong and simply demonstrate the mess. This and the way he has explained it seems to be him saying that these cores are finally the nail in the coffin for Intel when they aren’t even as good as other ARMv8s. >This lousy design unfortunately is synonym for ‘ARM device’ >and people won’t believe that ARM thingies exist that do not suck totally. I don’t think that’s all the RPi’s fault. ARM SoCs have up until recently have mainly been an ARM core with an assortment of junk IP blocks attached especially in the tens of… Read more »
@tkaiser, I agree that what the guy demonstrates has much more to do with the quality of compilers, more specifically codegen, and much less to do with A1 as a viable cloud service. But at least he gives a reference point*, in contrast to what phoronix did with many tests in their ‘proper’ review. BTW, not having seen his test code, but guessing off the top of my hat what it might be doing, a (multi-threaded or otherwise) Sieve of Eratosthenes uses 1 bit per number in the sought range of numbers, so to get 12.5M primes, he’d need to… Read more »
>BTW, not having seen his test code,
https://github.com/garyexplains/examples.git
>* point being 8x CA72 @ 2.3GHz perform equally to 4x BWL @ 3.3GHz
>(4 cores turbo) w/ SMT at this particular workload.
That might depend on the time of day, the direction of the wind etc as you have other instances running vCores(threads) on those physical cores. You are also limited on how much you can schedule on the core and have a limited number of “credits” that allow you to burst.
Thanks for the test url. Based on that: 1. Test from the repo is not using the Sieve of Eratosthenes — it’s using a naive test for primes, similarly to what I did recently in the prime factorizer article. So my bitmap usage hypothesis above is void, and L2 caches don’t affect this test one bit. 2. Test from the repo computes the primes *among the first 12.5M natural numbers*, not first 12.5M. primes per se! Test is replicated across all cores — it’s more of a multi-instanced workload, rather than a distributed multi-threaded workload. 3. gcc as old as… Read more »
> Re the indicativness of the test running on the AWS xeons in the video
Update:
I just realized the AWS xeons are BWL, but my workstation is SNB, which would not pose much of a difference in other scenarios, but in this particular test DIV throughput is essential for the multi-threaded times, and DIV throughput on BWL is 1.2x-2x the DIV throughout on SNB. So it’s possible the clock of the AWS xeons might have been as low as ~2.3GHz.
Ok, I had to get to the bottom of this Gary Explains video. Here is the exact same test on my CA72 @ 2.1GHz chromebook — remember, the number of threads barely matters for the duration of this test on non-SMT machines, the two threads specified below are just because. $ gcc-7.3 -Ofast -fstrict-aliasing threadtesttool.c -mcpu=cortex-a57 -mtune=cortex-a57 -lpthread $ time taskset 0xc ./a.out 2 12500000 Threading test tool V1.0. (C) Gary Sims 2018 Threads: 2. Primes to find: 12500000 real 0m5.292s user 0m10.336s sys 0m0.000s Vs real 0m8.993s in the video. On a 2.3GHz CA72.. But what might be wrong… Read more »
Ok, enough tomfoolery. a1.medium: $ uname -a Linux ip-172-31-2-119 4.15.0-1028-aws #29+nutmeg8-Ubuntu SMP Tue Nov 20 02:59:41 UTC 2018 aarch64 aarch64 aarch64 GNU/Linux $ cat /proc/cpuinfo processor : 0 BogoMIPS : 166.66 Features : fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid CPU implementer : 0x41 CPU architecture: 8 CPU variant : 0x0 CPU part : 0xd08 CPU revision : 3 $ gcc-7.3 -Ofast -fstrict-aliasing threadtesttool.c -mcpu=cortex-a57 -mtune=cortex-a57 -lpthread $ time ./a.out 1 12500000 Threading test tool V1.0. (C) Gary Sims 2018 Threads: 1. Primes to find: 12500000 real 0m4.766s user 0m4.765s sys 0m0.000s $ echo "scale=4; 4.766 * 2.3… Read more »
By the way, gcc-7.3 supports -mtune=cortex-a72 in case you’re interested in testing for any difference.
I know, but the uarch scheduling differences between CA57 and CA72 are close to nil for scalar integer code (for comparisons, they are smaller than those between SNB and IVB) and, for some arcane compiler reasons, I’ve seen native CA72 scheduling produce worse times on some tests, so my modus operandi is to go with CA57.
Thanks for bringing this up for the general reader, though — I usually skip these details.
>And it gets totally weird when bringing in the RPi I found that strange too. If you’re going to do the comparison between an AWS ARM and a SBC why not use any SBC that isn’t totally crippled like the RPi. >two Amazon instances is not totally flawed since using same compiler versions and 64-bit settings. The two instances aren’t like for like. The have the same “core” count but a core in the X86 instances is a thread on a core. The results of his benchmark aren’t terribly different so the only real win for the ARM instance was… Read more »
The real important bit here is context and having read numerous articles on these aws, the savings are TCO compute for Amazon.
Amazon are just using other peoples work loads for real life testing, proof of concept. The savings are power bill and hardware costs, for Amazon.
Really? people does not notice that android emulation will be WAY FASTER than in a x86 cpu? for the company I work to those are great news, since we virtualize everything through remote servers, but workers need android devices in their daily tasks. If Amazon is starting to offer this means VMWare is soon releasing tge ESXi for ARM and there we go emulating hundreds of devices instead of having those devices physically or shitty emulators slowing down everything.
Looking at the AWS instance pricing I am not seeing a 45% cost savings on the a1 instances. In fact it looks like in many cases you can get more performance at a lower cost using the t3 instances.
Hi, Amazon EC2 A1 would support nginx or apache2 ? i mean can we install nginx or apache2
https://www.scaleway.com/pricing/
but
https://www.ctrl.blog/entry/scaleway-nothanks
https://hostadvice.com/hosting-company/scaleway-reviews/
https://www.trustpilot.com/review/scaleway.com
currently (JAN 2019)
https://www.packet.com/
have a survey, please filled.
Intel getting some competition is good.
If you know different provider than amazon and scaleway
I’ll love to hear.