
Last year, the CERN published a paper comparing Applied Micro X-Gene (64-bit ARM) vs Intel Xeon (64-bit x86) Performance and Power Usage, and they’ve now added IBM Power 8 and Intel Atom Avoton C2750 processor to the mix in a new presentation entitled “A look beyond x86: OpenPOWER & AArch64“.
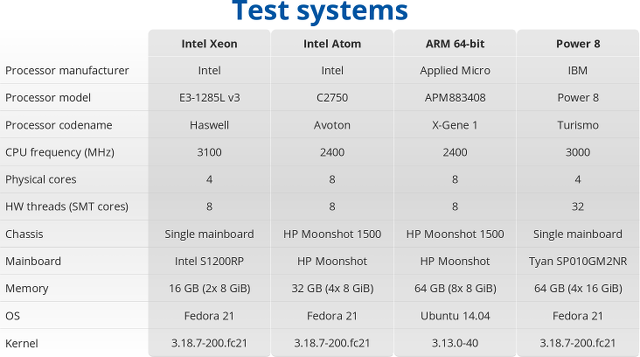
So four systems based on Intel Xeon E3-1285L, Intel Atom C2750, Applied Micro X-Gene 1, and IBM Power 8 were compared, all running Fedora 21, except the HP Moonshot 1500 ARM plarform running Ubuntu 14.04 and an older kernel. All four systems use gcc 4.9.2, and Racktivity intelligent PDUs were used for power measurement.
I’ll just share some of their results, you can read the presentation, or go through the benchmark results to find out more.
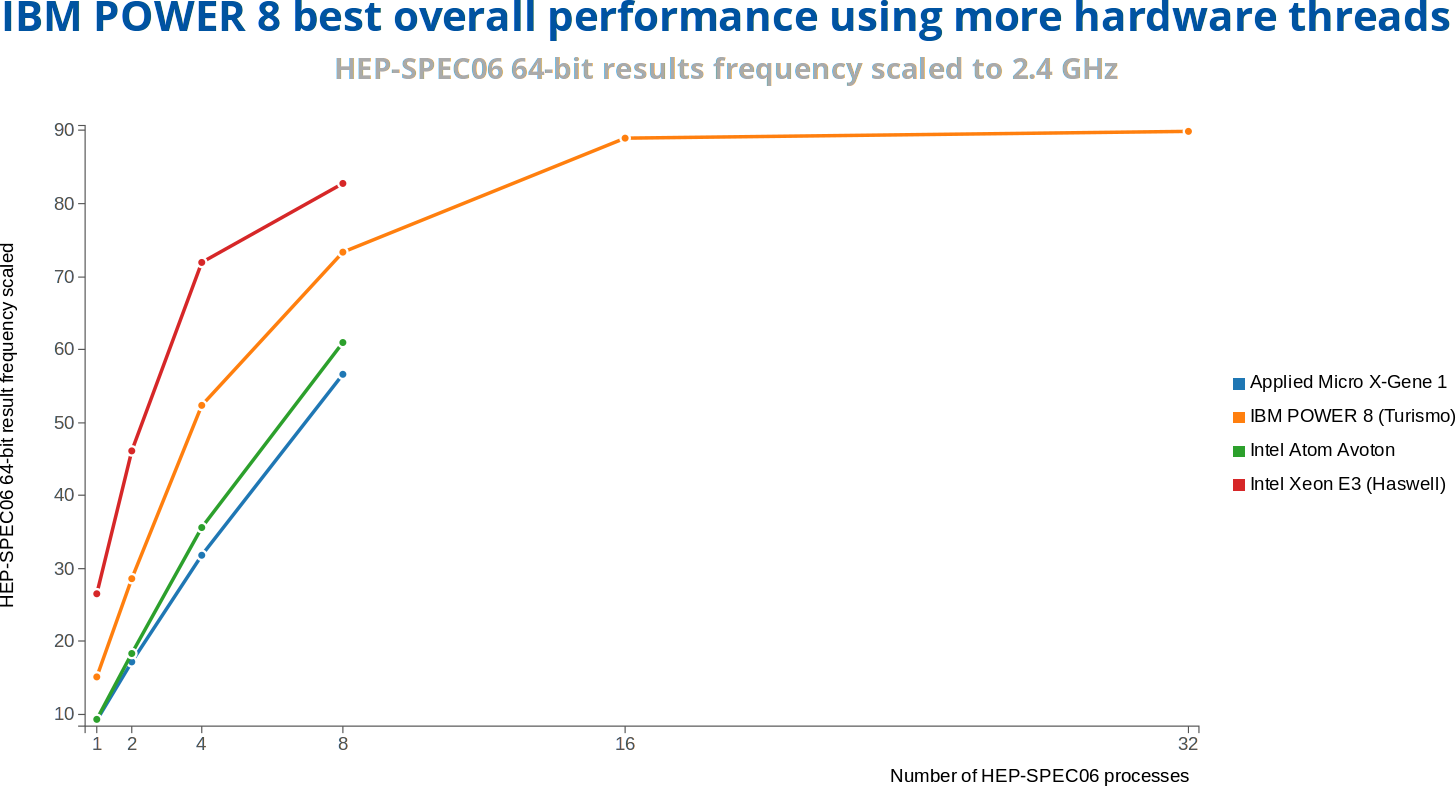
HEP-SPEC06 is a new High Energy Physics (HEP) benchmark for measuring CPU performance developed by the HEPiX Benchmarking Working Group, and here it’s not surprising to see the low power solutions under-perform the more powerful Intel Xeon and Power 8 processors, with the latter taking the crown.
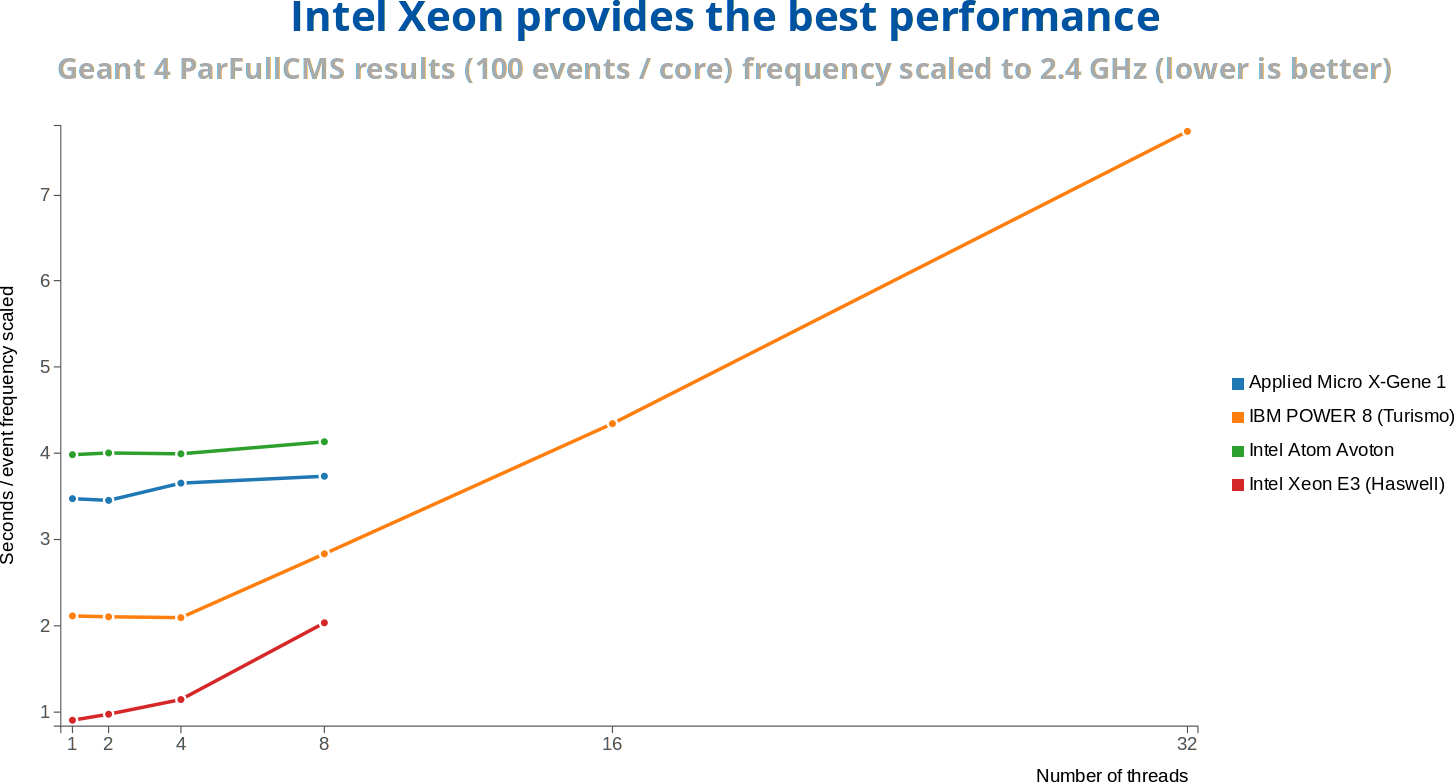
Geant 4 simulates the passage of particles through matter, something that you would expect the CERN to do regularly. Intel Xeon E3 outperforms IBM Power8 processor here.
But let’s move on to power consumption, and performance per watt.

IBM OpenPower 8 has a much higher power consumption than other systems, and HP Moonshot ARM 64-bit X-Gene 1 consumes more than both Intel servers. The chart under full load (not shown here) also shows a similar pattern.

When it comes to performance per watt however, both HP Moonshot ARM and Power 8 systems are the least efficient here, and Intel systems provide the best ratio. Bear in mind that X-Gene 1 is manufactured with a 40nm process, while Applied Micro X-Gene 2 and 3 will be manufactured using 28nm and 16 nm FinFET processes, so some large efficiency gains could be expected here.
We may find out soon, as the CERN expects to add these two new processors, as well a Cavium ThunderX to their benchmarks in the future.
Thanks to David for the tip.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



The colours at the graphs are mixed so it’s a bit confusing. You’ve written that both Moonshot systems are the most efficient, but these are the Intel platforms that are the most efficient. Power 8 and ARM systems are 2-3 times worse.
@kkarpowi
Thanks. I saw that, and changed it to “least efficient”.
Mixing colors between chart is indeed confusing.
Define efficiency. What metrics is CERN actually using (keeping in mind that they’re NOT looking at this for anything other than SUPERCOMPUTERS here…)- for the metrics they’re using, a Xeon, Opteron, and Power series CPU is going to “do better” (And it should be noted that this doesn’t get into the cruel, cruel truth that they’re NO LONGER USING THE CPUS solely- compute muscle is being provided by compute kernels on a GPU or FPGA now.)
One shouldn’t use this stuff as the basis for determining anything, to be strictly honest about it all.
@Nobody Of Import
You’re right.. I’ve changed “Server” to “HPC” in the title.
I think the X-Gene does pretty well if you consider that it´s 2 times behind the Avoton and the Xeon (as you wrote). Taking into account this was their first 64bit core and dates from 2012 and the ARMv8 Servers are still a bit in the fledgling stage i guess it gets clear why Intel should be worried. Not that their absolute lead is in danger any time soon, but there will be a lot of alternatives in that field in the not so distant future, which could hurt their prices and revenue. With other big players entering that ARMv8-Server… Read more »
@Nobody Of Import Computations done at LHC experiments heavily rely on general purpose CPUs. FPGAs are used in online systems (data acquisition systems close to detector reading sensor data). Soon after that (still underground) RAW data is processes with CPUs in HLT (High Level Trigger). CPUs are used for trigger systems, simulation, data reconstruction, and analysis. Research into using GPUs and Xeon Phi is being done, but none of them are production ready and only specific tasks can be optimized (e.g., big focus is on tracking). I think, there are a few bits GPU capable, but depends on experiment. We… Read more »