
Arm has just announced two new processors for compute workloads with a power efficient Neoverse E1 platform targeting edge devices like 5G base stations, as well as the more powerful Neoverse N1 platform designed for the cloud, and aiming at challenging Intel Xeon processors.
Arm Neoverse E1
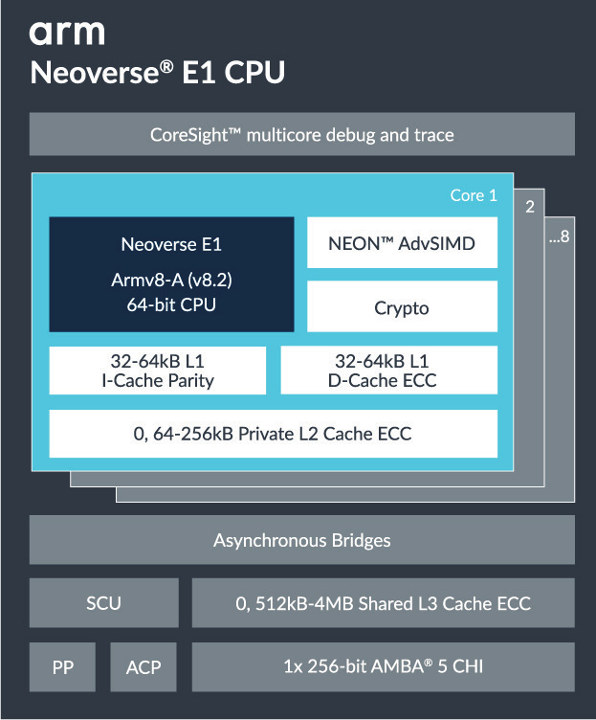
Key specifications and features of Arm Neoverse E1:
- Simultaneous Multithreading (SMT) supporting two threads
concurrently - Up to 8 cores (16 threads) per cluster
- Superscalar, out-of-order pipeline
- Configurable private L2 cache
- Configurable L3 cache
- Low-latency Accelerator Coherency Port (ACP) for closely coupled accelerator integration
- Support cache stashing into L2/L3 cache
Arm Neoverse E1 is the first Arm processor to support SMT and is best suited for data plane compute workloads such as 4G/5G transport, software-defined networking, software-defined storage, and SD-WAN. The platform features a scalable architecture suitable for 10Gb wireless/wireline devices to high-performance 100G+ Dataplane Processing Unit (DPU).
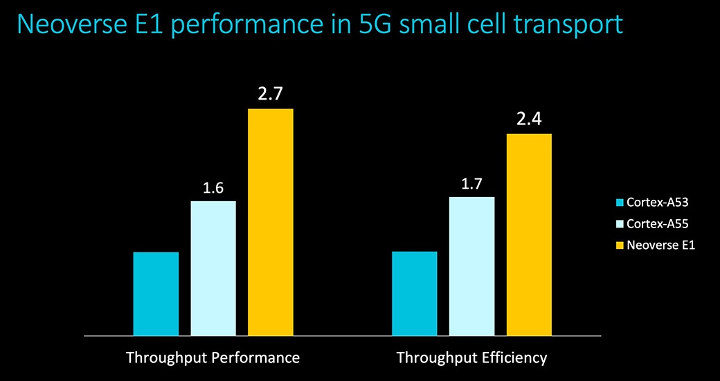
Arm developed a 5G small cell transport software prototype which simulates packet processing workloads at a 5G base station in order to evaluate the platform and found Neoverse E1 to boost throughput performance by 2.7 times over Cortex-A53, and throughput efficiency by 2.4 times.
Neoverse E1 Edge Reference Design through its paces. The Neoverse E1 Edge Reference Design includes sixteen Neoverse E1 cores arranged in two clusters of eight cores, connected through the high-performance CMN-600 mesh interconnect, MMU-600 system MMU, and 2-channel DDR4-3200.
The prototype ran on Neoverse E1 Edge Reference Design with 16 E1 cores arrange in two 8-core clusters, and consuming less than 4W at 2.3GHz.
More details can be found in the announcement’s blog post and the product page.
Arm Neoverse N1
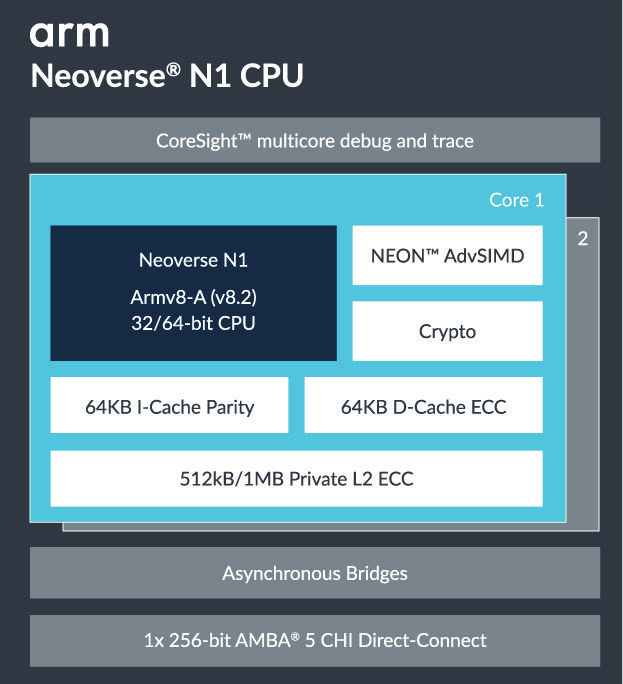 Arm Neoverse N1 highlights:
Arm Neoverse N1 highlights:
- Up to 128 cores in a single coherent system
- 64kB L1 instruction and data cache
- Up to 1MB large private L2 cache
- Up to 128MB of shared system level cache through a low-latency
direct-connect interface to the CMN-600 mesh - Microarchitecture for large footprint, branch-heavy workloads
- I-cache coherency to enable a broader range of server workloads
- Double the vector and crypto compute bandwidth over
previous generation - No-compromise, full-frequency, sustainable compute efficiency
managed at runtime - Server-class virtualization, RAS and code profiling
The Arm Neoverse N1 Platform comprises the N1 CPU and supporting
system IP connected via a coherent mesh interconnect. It is optimized for low-latency and bandwidth efficiency and targets sub-35W 8-core systems up to 128+ core in servers targeting 5G deployment, data analytics, and machine learning.
 Arm found Neoverse N1 to be significantly faster than Arm Cortex A72 in typical server workloads:
Arm found Neoverse N1 to be significantly faster than Arm Cortex A72 in typical server workloads:
- 2.5x NGINX performance
- 1.7x OpenJDK
- 2.5x MemcacheD
- 1.6x MySQL
- 6x DeepBench
- Up to 2x DPDK
- 1.6x OvS
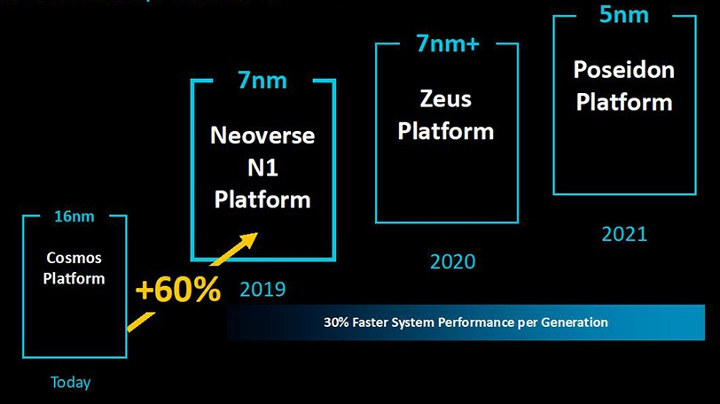 So Neoverse N1 – previously known as Ares – delivers at least 60% performance over Arm Cortex A72 at the same frequency, and the roadmap shows the company’s Zeus & Poseidon platforms will deliver 30% performance improvement per year with the latter manufactured using a 5nm process in 2021.
So Neoverse N1 – previously known as Ares – delivers at least 60% performance over Arm Cortex A72 at the same frequency, and the roadmap shows the company’s Zeus & Poseidon platforms will deliver 30% performance improvement per year with the latter manufactured using a 5nm process in 2021.
We may already know at least one part based on Neoverse N1, as Hisilicon Hi1620 processor was announced with 64 Ares cores at the end of last year.
You may want to visit Neoverse N1’s developer page and announcement for more details.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.


Arm really needed something positioned between the little CA53/55 and the big cores, and E1 seems like it. Smart move.
ps: seems like arm still can’t decide between ‘neon’ and ‘asimd’, so sure, why not both? ; ]
AdvSIMD is the official name. At least it should be 🙂
I know. Yet look at them NEONs ; )
Yeah 🙂 The first time I heard Neon was as the name of the AdvSIMD unit in Cortex-A8. I can’t say if that was the project name for the instruction set, or just the codename of the RTL block. Anyway everyone now uses Neon even internally.
The important thing is we’re at neon2 now ; )
Actually what’s the point of comparing the E1 with A53/55 only? And why they need SMT to get some performance most likely below an A75? I’m confused, is it just to be more modern, more vulnerable to spectre? Don’t serm to get it. And otoh N1 seems not to rely on SMT…
Actually E1 takes over dataplane tasks which were formerly (erm, currently) handled by CA72s. Apparently higher counts of lower single-thread-performance E1s are better suited for the task. Which is understandable — as soon as you meet the latency requirements (which are still out of CA55’s league) of the task, you want to maximize the throughput, and that means more cores and SMT.
A lot of code dealing with packet processing is in fact very simple and more dependent on frequency than on the ability to parallelize instructions. When you parse a packet you spend time incrementing offsets, comparing values and jumping. An A53/A55 there will not be far below an A72 on this task. And accesses are quickly memory-bound. So it makes sense to use a larger number of dumber cores, with SMT to improve the execution unit’s usage while waiting for memory. I really think that this approach makes a lot of sense.
Interesting thanks for the explanations!
Arm Neoverse N1 Core Technical Reference Manual
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.100616_0400_00_en/index.html