
AndesCore 27-Series VPU
Andes has developed a Linux capable RISC-V based SoC which runs on the first Vector Processing Unit (VPU) that is reported to be groundbreaking in its application ability, especially in the AI sector. The Andes 27 Series CPU has debuted in the RISC-V Summit in San Jose, to a great deal of talk in many quarters.

The AndesCore 27-Series RVV
The company reports that the AndesCore 27 offers a user-configurable vector-processing unit that has a scalable data size, flexible microarchitecture implementations and subsystem memory decisions open to system-level optimization. The use of the RISC-V Vector (RVV) instruction extension allows the CPU cores to deliver higher performance and versatility.
The TimeTable and Offerings
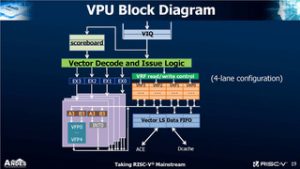
Andes is saying delivery of its first Andes 27 RISC-V based SoC will begin in Q1 2020. Already the earliest licensees have seen the delivery of the betas. Initial availability will center around a 32-bit A27 the 64-bit AX27 and the Vector Register File (VRF) access and the RISC-V Vector (RVV) instruction extension can be found on the NX27V.
Before There Was The AndesCore 25-Series
The Cores are based on the previously released Andes 25 series, which are the 32-bit A25 and 64-bit AX25MP. The new AndesCore 27 NX27V is a RISC-V based core, with a vector register file, VRF which has a user-configurable number of elements per register.
The Applications for These Cores
The cores are able to process large volumes of matrix data, that can be used in the following applications.
- AI
- AR/VR
- Cryptography
- Computer vision
- Multimedia processing
The SoC is Linux ready.
The Vector Settings
The vector can be af arbitrary length, from 64-bit all the way to a combination of eight vector registers for 4096-bit size. Each integer, whether floating point, fixed point or any other AI optimized representations can be various bit-widths, from 4 to 32-bit.
The Functions of the VPU
The vector processing unit has multiple, chainable, functional units, that can operate in multiple independent pipelines. It can realize 30X speedup on key functions in MobileNets convolution neural network (CNN).
The Aspects Not Readily Discussed
The AndesCore 27-series is closely aligned to the AndesCore 25-series which would offer a 1.2 GHz, 3.5 CoreMark/MHz performance standard. The same development tools apply, as with the A25 and AX25, the AndeSight IDE, a “COPILOT” tool to be used with ACE, JTAG and ICE debugging.
Further Information
The AndesCore 27-series announcement and the LinuxGizmos article will have further information on the AndesCore 27-series VPU cores, with RISC-V architecture.

Stephen started writing about technology after publishing sci-fi short stories. His first White-Paper, written in 2008, was well received and inspired him to continue writing about technology. Today he writes in the technology space full time, covering a multitude of topics. During the time he wrote part-time he edited hundreds of titles for large publishers, in science and technology. He lives in Staten Island, with his wife and children.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



Reading through the Vector Settings paragraph, this does not seem to be an implementation of the RV V-spec, or am I missing something? At the very least, standard element widths do not match. For reference, this is the spec: https://github.com/riscv/riscv-v-spec/releases/download/0.7.1/riscv-v-spec-0.7.1.pdf — 3.2.1. Vector standard element width vsew
According to Andes disgusting marketing BS [1] that is VLEN=512-bit and LMUL=8. So that falls into the RV-V spec if I understood correctly.
BTW isn’t that spec still a draft?
[1] http://www.andestech.com/en/2019/12/04/andes-presents-ground-breaking-27-series-processor-at-risc-v-summit-2019/
Be prepared that really is marketing BS at its worst.
My point is that element with of 4 bits is not or has ever been in the spec. And this is a rather fundamental part of the V-spec. And yes, the spec is still a draft.
Sorry I misread your comment as I was focusing on that 4096-bit value.
You’re definitely correct: that 4-bit width isn’t in the draft. I guess it’s a typo.
Surprisingly enough, that 4-bit SEW is also in the press release you linked:
It also allows each computation of integer, fixed point, floating point, and other AI-optimized representations to be any bit-width from 4 bits to 32 bits (SEW)..I guess the source of information is the same 😉
We would like to support marketing structures with explaining their difficult task shown in following comment:
https://www.cnx-software.com/2019/12/11/intel-roadmap-2019-2029-1-4-nm-processors-expected-within-10-years/#comment-569466 🙂
When I read the headline I interpreted it as a 27-core Linux RISC-V SoC, and I was definitely interested! I imagined some kooky but fun 3x3x3 collection of cores doing co-ordinated vector processing. Oh, the reality is so much less exciting…