
Kendryte K210 is a dual-core RISC-V AI processor that was launched in 2018 and found in several smart audio and computer vision solutions. We previously wrote a Getting Started Guide for Grove AI HAT for Raspberry Pi using Arduino and MicroPython, and XaLogic XAPIZ3500 offered an even more compact K210 solution as a Raspberry pi pHAT with Raspberry Pi Zero form factor.
The company is now back with another revision of the board called “XaLogic K210 AI accelerator” designed to work with Raspberry Pi Zero and larger boards with the 40-pin connector.

K210 AI Accelerator board specifications:
- SoC – Kendryte K210 dual-core 64-bit RISC-V processor @ 400 MHz with 8MB on-chip RAM, various low-power AI accelerators delivering up to 0.5 TOPS,
- Host Interface – 40-pin Raspberry Pi header using:
- SPI @ 40 MHz via Lattice iCE40 FPGA
- I2C, UART, JTAG, GPIOs signals
- Security
- Infineon Trust-M cloud security chip
- 128-bit AES Accelerator and SHA256 Accelerator on Kendryte K210 SoC
- Expansion – 8-pin unpopulated header with SPI and power signals
- Misc – 3x LEDs,
- Power consumption – 0.3 W
- Dimensions – 65x30mm Raspberry Pi Zero HAT
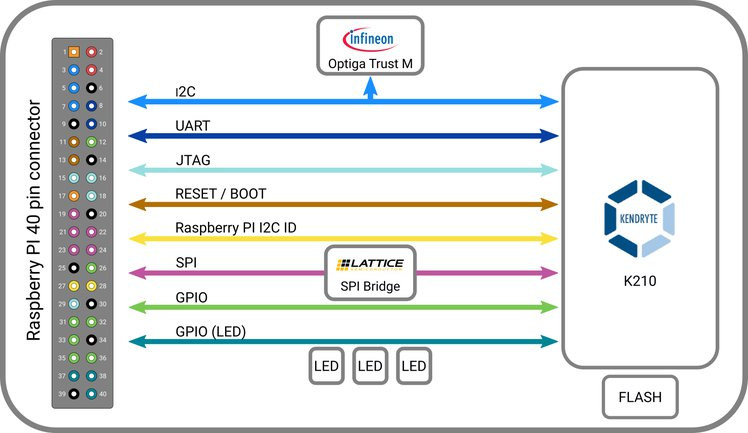
The company also offers an extender for Raspberry Pi 3B+, 4B board and future model that includes a PoE header. It’s unclear why an FPGA is needed for the SPI interface between K210 and the Broadcom processor on the SBC as both support SPI, so maybe it’s master/slave issue, or for improved performance. I also noticed one of the K210 SPI interface (it has four) is exposed through an 8-pin header. Another difference compared to other K210 board is the including of Infineon Trust-M security chip that is meant to help “establish a secure connection to AWS through MQTT without exposing the private key.”
XaLogic K210 AI Accelerator works best with Raspberry Pi Zero and camera, and allows you to use pre-trained models for evaluation including object detection, face detection, age and gender estimation, simple voice commands, and vibration abnormally detection. It will also be possible to train your own model using a more powerful host machine, ideally with an NVIDIA GPU, with TensorFlow. Conversion tools enable the use of TFLite, Caffe, and even ONNX format. The company recommends Visual Studio Code to modify K210 C code directly on Raspberry Pi if needed.
Now public information is limited, but eventually schematics, C code in the K210, all code running on the Raspberry Pi, sample Python based Caffe & Tensorflow projects will be open sourced, while pre-trained models will be provided in binary form on the company’s Github account.
XaLogic K210 AI Accelerator has just launched on Crowd Supply with a $3,000 funding target. A $38 pledge is asked for the board, and if you plan to use it with Raspberry Pi 3B+ or 4B, you may want to add $3 for a 40-pin extender due to POE header obstruction. Shipping adds $8 to the US, and $16 to the rest of the world. It’s around $10 more expensive than the Grove AI HAT, likely because of the FPGA and security chips, but sadly XaLogic did not do a very good job of clearly explaining the advantage brought out by the extra chips. Shipping to backers is expected to start at the end of May 2021.


Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.


It is quite interesting board, unfortunately the price is far to high, especially with 16 US$ shipping.
The BOM price is less than 15 US$ (calculated based on componnent price for only a single piece, so probably much lower when buying in >1000 quantity).
They could at least manage the free shipping somehow, than the price would be more fair…
The ICE40 FPGA is, IMHO, completely unnecessary, as K210 has an excelent and very flexible SPI Slave peripheral. Unfortunatelly it is not well documented, so they probably had some issues configuring it, but it can be done (the FPGA alone is almost 30% of the price!).
Isn’t 0.5 TOPS (Tera Operations Per Second) extremely low, compared to GPU / FPGA / ASIC solutions?
For Edge AI devices that’s OK. The range is usually 300 MOPS to 4 TOPS. But compared to the hardware used in the cloud, or Edge AI gateways it’s low yes. The power consumption and costs are also much higher.
The Google Coral (59 USD, USB interface): “Google Edge TPU coprocessor:
4 TOPS (int8); 2 TOPS per watt”
So 8 times faster, and an easy USB interface … ?
It should be faster, but a bit bulkier, and not security chip.
It may not be 8 times faster, as TOPS is not always a useful performance metric. It just gives an indication.
The K210 is an AI toy. V831 is probably the minimum viable SOC for a production product. RV1109 is a decent SOC for production.
There are two phases to AI use — training and production. Training needs all the TOPS you have and it can still take days. So it is common to train in cloud using hundreds of accelerators or at home using something like an RTX3080.
Then there is production. Production simply runs the model you created by training using new input data. There are two axis with this — how complex your model is, and how fast your input is arriving. Here are some ballpark estimates to run production models…
Hot word recognition in Alexa — 2 second response, single audio data stream. Needs 0.1TOPS. Usually handled without an AI accelerator.
Doorbell — low complexity — people, pets, wind blowing, 1 second response. Needs 0.5TOPS. Can be done without AI accelerator on higher end SOCs.
Facial security camera for a business — 5,000 faces, 0.5 second response. Needs about 2TOPS. Pretty much has to have NPU.
Robotic vision — lower resolution, varied objects, real-time tracking, 0.02 second response. Needs about 5TOPS
Self driving car — many cameras, LIDAR, fast movement, 0.02 second response. 20TOPS or more. Mandatory NPUs, usually multiple ones.
A common mistake made by AI beginners is to do training on a production device. Sure you can do it, it is just going to take weeks to finish. After you try this once you will go buy a RTX3080 (20TOPS).
You can try combining multi Google Corals to save a little money, but you might need eight of them to equal a RTX3080. And the RTX plays games too.
Wait! RTX3080 does have only 20TOPS?
FP32 TOPS, these edge devices are INT8 TOPS. Not sure what RTX3080 does for INT8 TOPS but it will be much higher. You do training with the FP32 TOPS.
Most edge devices can not do FP32 networks. After training your network you quantize it which converts it to run on INT8. But you can’t do this until after it is trained.
I am simplifying here, there is a lot more to the whole process.
That’s way better explanation. I was just curious what oranges got compared with apples here since even 3060 is advertised as having 101 TOPS.
I think RISC-V is a scam. Why do you need 2 low clocked incompetent cores to do the computation intensive workloads? Right, there is a FPGA chip, like all other RISC-V stun.
The computation intensive workloads are managed by the AI accelerators inside the chip.
I’m still not sure why there’s an FPGA on the board, as it’s just handling the SPI interface between K210 and the Raspberry Pi..