
We’re often writing about new video codecs like AV1 or H.266, and recently, we covered AVIF picture format that offers an improved quality/compression ratio against WebP and JPEG, but there’s also work done on audio codecs.
Notably, we noted Opus 1.2 offered decent speech quality with a bitrate as low as 12 kbps when it was outed in 2017, the release of Opus 1.3 in 2019 improved the codec further with high-quality speech possible at just 9 kbps. But Google AI recently unveiled Lyra very low-bitrate codec for speech compression that achieves high speech quality with a bitrate as low as 3kbps.
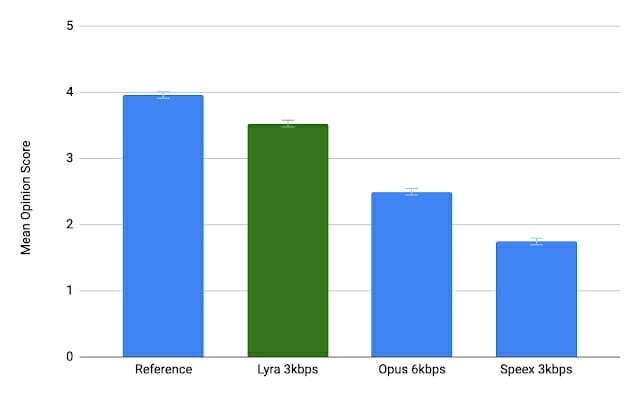
Before we go into the details of Lyra codec, Google compared a reference audio file encoded with Lyra at 3 kbps, Opus at 6 kbps (the minimum bitrate for Opus), and Speex at 3 kbps, and users reported Lyra to sound the best, and close to the original. You can actually try it by yourself.
Speex 3kbps sounded pretty bad for all samples. I feel Opus 6kbps and Lyra 3kbps sound about the same with the clean speech samples, but Lyra reproduces the background music better in the noisy environment.
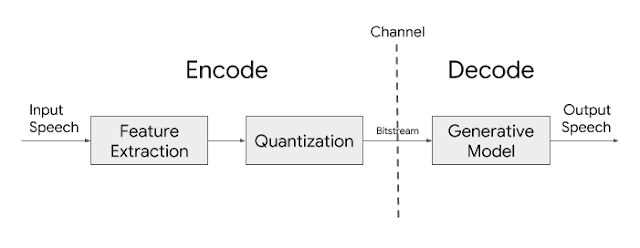
So how does Lyra work? Google AI explains the basic architecture of the Lyra codec relies on features (log mel spectrograms), or distinctive speech attributes, representing speech energy in different frequency bands, extracted from speech every 40ms and then compressed for transmission. On the receiving end, a generative model uses those features to recreate the speech signal.
 Lyra works in a similar way to the Mixed Excitation Linear Predictive (MELP) speech coding standard developed by the United States Department of Defense (US DoD) for military applications and satellite communications, secure voice, and secure radio devices.
Lyra works in a similar way to the Mixed Excitation Linear Predictive (MELP) speech coding standard developed by the United States Department of Defense (US DoD) for military applications and satellite communications, secure voice, and secure radio devices.
Lyra also leverages natural-sounding generative models to maintain a low bitrate while achieving high quality, similar to the one achieved by higher bitrate codecs.
Using these models as a baseline, we’ve developed a new model capable of reconstructing speech using minimal amounts of data. Lyra harnesses the power of these new natural-sounding generative models to maintain the low bitrate of parametric codecs while achieving high quality, on par with state-of-the-art waveform codecs used in most streaming and communication platforms today. The drawback of waveform codecs is that they achieve this high quality by compressing and sending over the signal sample-by-sample, which requires a higher bitrate and, in most cases, isn’t necessary to achieve natural sounding speech.
One concern with generative models is their computational complexity. Lyra avoids this issue by using a cheaper recurrent generative model, a WaveRNN variation, that works at a lower rate, but generates in parallel multiple signals in different frequency ranges that it later combines into a single output signal at the desired sample rate. This trick enables Lyra to not only run on cloud servers, but also on-device on mid-range phones in real time (with a processing latency of 90ms, which is in line with other traditional speech codecs). This generative model is then trained on thousands of hours of speech data and optimized, similarly to WaveNet, to accurately recreate the input audio.
Lyra will enable intelligible, high-quality voice calls even with poor quality signals, low bandwidth, and/or congested network connections. It does not only work for English, as Google has trained the model with thousands of hours of audio with speakers in over 70 languages using open-source audio libraries and then verifying the audio quality with expert and crowdsourced listeners.
The company also expects video calls to become possible on a 56kbps dial-in modem connection thanks to the combination of AV1 video codec with Lyra audio codec. One of the first app to use the Lyra audio codec will be Google Duo video-calling app, where it will be used on very low bandwidth connections. The company also plans to work on acceleration using GPUs and AI accelerators and has started to investigate whether the technologies used for Lyra can also be leveraged to create a general-purpose audio codec for music and non-speech audio. More details can be found on Google AI blog post.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.


Unfortunately I cant get the Lyra samples to play on my mobile.
It would be very interesting to have also some samples of codec2 included, as this is also competing with melp, kind of.
David Rowe of codec2 / rowetel.com was also experimenting with AI decoding of codec2, that seems to be a very interesting field at the moment.
Woop. Missed that you’d beat me to that.
They’ve moved on to LPCNet which uses an AI trained function to encode the coefficients and have gotten much lower bit rates.
“I feel Opus 6kbps and Lyra 3kbps sound about the same with the clean speech samples”
I disagree. Lyra clearly sounds better to me even in that case. This appears to be a technical triumph from Google.
I look forward to seeing other comparisons, like what bitrate Lyra needs to match 32 Kbps Opus.
Agreed. Maybe he didn’t used headphones. I’m impressed with Lyra samples.
I didn’t use headphones :O
Lyra most likely won’t be effective on the higher bitrates, as it seems to be a pure vocoder.
This codec is not like MELP at all, it is FFT-based, not LPC based, closer to what speech recognition systems use, more computationally intense but clearer results. Not open-source either it seems just now 🙁
Methods differ, results remain similar, melp, ambe, codec2 all playing on the same playground, just the rates taken differ “slightly”
Lyra noisy sounds weird: “someBLIPhave accepted”.
Generally Lyra sounds like its cropping the first and last few ms of sound off of each word. Doesn’t sound natural. Opus sounds more natural, albeit noisier.
should be good for BT hand-free mode, which still stucks at its poor sound quality under its bandwidth+latency concern
Reminds me of the work that David has been doing on Codec2 (https://www.rowetel.com/?page_id=452) and subsequently FreeDV (https://freedv.org/)
Those two are in fact cousins 😉
This is impressive, really. I remember, in 1996 with a friend we started an audio compression challenge just for fun. I used FFTs and got pretty good results (by then I had never heard about the forthcoming MP3). Hearing the awful sound my step-father was getting out of his Radiocom 2000 phone made me wonder if I could use my method to compress voice. It worked remarkably well but the bit rate was not as interesting as what GSM could already do by then, and I figured that 4kbps was really the absolute limit beyond which the compression artifacts would be louder than the voice, and would make the result hardly understandable. Google just proved that I was wrong and lacking skills in this area, because their 3k samples sound way better than what I could get at 16k. That’s why I’m really impressed 🙂
Actually from quite a while there is AMBE 2+ codec which is used in the circuit switched voice services on Inmarsat’s F4 satellites (BGAN, Swift broadband, lsatphone) and sounds quite great for 2.4kbps.
So google is not doing anything ground breaking, just they will make that technology more accessible, as is also doing codec2…
Forgot about that one. I wrote about it a few years ago. AMBE+2 can be implemented by software and through a vocoder chip.
https://www.cnx-software.com/2017/10/24/ambe2-vocoder-promises-high-voice-quality-at-low-2-0-to-9-6-kbps-data-rates/
Can someone post the github link here?
AFAIK, Google hasn’t released anything for Lyra yet.