
As a StarFive Technology in-house developed RISC-V 64-bit ultra-high-performance core, Dubhe showcases the best performance RISC-V CPU core IP yet. It utilizes the latest RISC-V instruction set which includes RV64GC, bit operation extension (B), vector extension (V) V1.0, and hypervisor extension H (Hypervisor), making it ideal for high-performance computing.
To pair with the Dubhe performance core, StarFive is now releasing “StarFive Perf Performance Profiling Tool”.
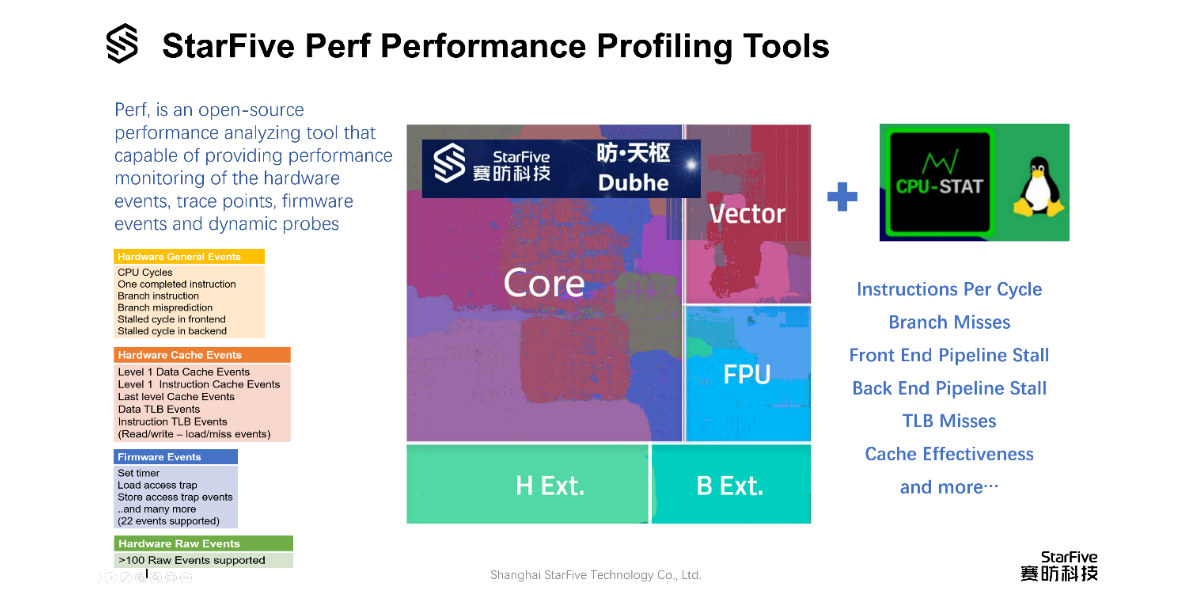
StarFive has made Perf compatible with the hardware performance monitor (HPM) and micro-architecture events at the hardware level. Perf provides a reliable performance verification platform that not only facilitates customers to further discuss the Dubhe technical specifications but also accelerates the implementation of high-performance applications with RISC-V processors.
Perf is an open-source and Linux-based performance analyzing tool capable of providing performance monitoring of the hardware events, tracepoints, firmware events, and dynamic probes. With the Perf profiling tool, we can monitor the performance of the predefined hardware events, predefined hardware cache events, and hardware raw events with programmable hardware performance monitor counters. It provides per task, per core, and per-workload counters sampling on these hardware events. A good example of usage is
|
1 |
perf stat -e cycles -e instructions -e branches -e branch-misses -e stallled-cycles-backend dhrystone 10000000 |
For more information about “StarFive Perf Performance Profiling Tool”, please visit https://github.com/starfive-tech/meta-starfive, or contact sales@starfivetech.com.
This account is for paid-for, sponsored posts. We do not collect any commission on sales, and content is usually provided by the advertisers themselves, although we sometimes write it for our clients.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.


Now if someone could make a RK3588 performance level SoC with RISC V and a open source GPU, Video encoding and decoding. Running Linux, Android that would set the Cat amongst the Pigeons.
Dont forget the pricetag for this rk3588 grade chip should also be in line with an esp32 c3 and leadtimes of less than a week…
People are working on software that builds chips like Lego but on a connected fabric bus. A move on from chiplets. As well as self iteration software writing. Use macro blocks of code, crazy to see working, its at MCU level so far. No GPU yet. People noticed the same design work and code being paid for repeatedly over and over. To much money being made with present designing methods yet to change money model. 🙄
Well, do not forget that performance heavily suffers when chips become too modular. This is already what makes EPYC CPUs unfit for certain workloads compared to Xeons for having a 3 times higher inter-core latency between certain cores. Just have a look below at some measurements I made on various CPUs, the numbers are in nanoseconds for an atomic operation, you can almost see how the chips are built!
https://htmlpreview.github.io/?https://github.com/wtarreau/atomic-tests/blob/master/results/all.html
We can hope that 3D chips should reduce this effect compared to chiplets but I’m not sure to what extent this will remain true since interconnection layers definitely limit frequency and add latency, and my fear is that this will be totally abused since very convenient for chip manufacturers (make smaller chips, trash less of them and wire them together).
Intel has been claiming that its “tiles” implementation of chiplets is superior, with less latency IIRC. I guess we’ll find out when Meteor Lake launches.
Careful use of 3D packaging should lead to some dramatic results. But it will be a party trick compared to monolithic 3D chips, which are not modular on their own. As for abuse, the semiconductor industry will abuse everyone in every way possible.
Needs to have 256 pci-e lanes, a max tdp of 1w under load, and uses the rpi form factor.
More performant cores for RiscV is a good thing, so congrats for that. One question, though, are all their cores still ‘soft’? Looking at the pictures above, it really looks like the cores are synthesized. ARM shows a bit of a performance uplift when you go from their soft cores to their hard cores (at least historically, so ARM9 ARM11 era). I’m curious if there still is that kind of penalty these days that’s maybe limiting the performance of RiscV cores.