
Many people assume newer processors will be faster, or that 64-bit processor will provide a performance boost compared to 32-bit processors, but the reality can be quite different, and I’ve decided to have a look at ARM Cortex-A cores using ARMv7 (32-bit) and ARMv8 (64-bit) architecture, and see what kind of integer performance you can expect from each at a given frequency. To do so, I’ve simply use DMIPS/Mhz (Dhrystone MIPS/Megahertz) values listed on Wikipedia.
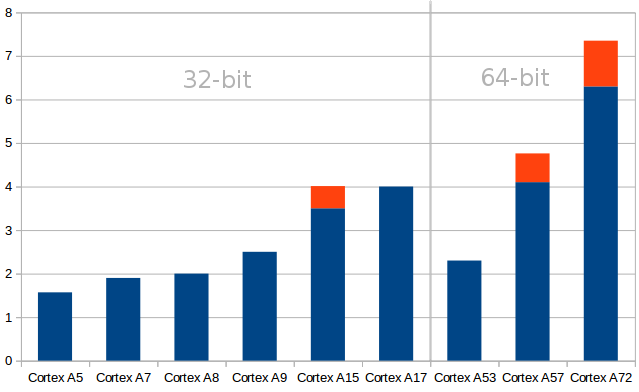
Drystone benchmark has no floating-point operating, so it’s a pure integer benchmark. I’m only looking at ARM core here, and once integrated in an SoC, other parameters like memory bandwidth, amount of cache, GPU, etc.. will greatly affect the overall system performance. The figure above are per MHz, and it does not mean for example that a Cortex A5 processor will be slower than a Cortex A7 processor, as can be seen by the comparison between Amlogic S805 (4x Cortex A5) and Broadcom BCM2835 (4x Cortex A7), which shows the Amlogic processor is about 40% faster due to higher clock speed.
With that in mind, it can be seen than you may not expect all recent Cortex A53 processors to outperform existing Cortex A15 and A17 processors, and in some case even Cortex A9 processors, and the real performance benefit with 64-bit cores only start to show with Cortex A57, and especially Cortex A72 cores which is some cases could be twice as fast as Cortex A15 cores. The red zone on top of some bars represents the possible performance variation due to different implementations of the cores.
ARMv8 also brings some other improvement such as additional cryptographic extensions, an increase in the number of SIMD/floating point, and general purpose registers, and more, as shortly explained in that article. All of these should also deliver benefits provided the firmware and applications support them.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



the graph looks sensible with just little detail and this is difference between A15 and A17 performance. A17 is just fine-tuned A15 so it should be the same or little bit better IMHO.
Well on the mighty Internet have you found to say that Cortex A17 is 3 DMIPS/Mhz? Also based on ARM information Cortex A7 has 90% of a Cortex A9 so I really doubt about Cortex A7 being under Cortex A8. Also according to ARM Cortex A53 is 30-40% faster the Cortex A7 on the same process, which would make it 20% faster than Cortex A9.
Also techreport says it “In fact, ARM tells us the A53 is roughly 15% faster than the mid-sized Cortex-A9 rev4.”
http://www.arm.com/White_Background_PNG_Cortex-A7.png
http://www.arm.com/Performance_Graph_A53_to_A7.jpg
So I would conclude your graph is deeply flawed.
@kcg
I could not find the figures for A17, only for A12, and I understood both just have the same performance… so ARM even phased out A12.
@RAF
The source is Wikipedia as stated in the article…
You may be right about the DMIPS of the A17 being roughly 3: [img]https://slideplayer.com/slide/12179214/71/images/137/4.+Overview+of+ARM%E2%80%99s+Cortex-A+series+%285a%29.jpg[/img]
Anandtech has a table with about the same numbers, including Cortex A9 > Cortex A53, except for Cortex A17, so I’ll update the chart with 4.0 instead of 3.0.
http://www.anandtech.com/show/7739/arm-cortex-a17
It would be nice to see some real world performance figures for these, not from Android benchmarks line Antutu but from some benchmarks running on Linux.
I am interested to know more about the red zone, is that related to manufacturing process or core revision? I have noticed the later A15 revisions like in the Tegra K1 have a big improvement in power consumption over the early versions ie Tegra 4. A72 looks like it’s going to be a Chromebook champion considering that my Tegra K1 HP is already more than powerful enough.
@GMR 73
I got the range on Wikipedia. For example with Cortex A72: “At least 6.3 DMIPS/MHz per core (up to 7.35 DMIPS/MHz depending on implementation)”, and unfortunately I don’t know the reason.
So you are concluding wikipedia (which I do not totally trust, because any one can post on wikipedia if that is what he really want) and anandtech (which indeed is a pretty accurate source of information) are more reliable than ARM slides?
It really gets interesting with Cortex-A57 octa core like the Nvidia Tegra X1
http://bitkistl.blogspot.co.at/2015/03/cortex-ax-vs-performnace.html
Bring on the low cost A54 and A72 boards and gadgets so we can all do “testing”!!
@RAF
I think they are two different set of data. I’m using Drystone MIPS data, which Anandtech says comes from ARM, but I could not find it on ARM website, while the ARM chart you provided must be using some other benchmarks, but they did not specify which one. If I have data for Cortex A5 to Cortex A72 with these benchmarks, I could make an alternative chart.
DMIPS/MHz for A7 is 1.9, for A53 2.3, so a difference of about 21% against 30% integer performance on ARM charts. So not quite exactly the same, but not such a massive difference either.
Cortex A15 and A17 may have the same integer performance (DMIPS/Mhz or SpecInt2k), but Cortex A17 is faster for web browsing. http://community.arm.com/groups/processors/blog/2015/04/20/cortex-a17-powers-new-generation-of-chrome-os-devices
http://images.anandtech.com/graphs/graph9878/79519.png
Only problem is that Cortex A9 is missing.
So if Rockchip could match AMLogic (cheats ), S905 prices with their RK3288 and Android 6 or 5.1.1 things could get really interesting?
AMLogic could be given a bloody nose. Can RK3288 match or get close to S905 power consumption?
which means cortexa9(32bit) is better then cortex a53(64bit)
So A17 >> A53 .. and if RK3229 runs 1.8GHz and RPI3 runs 1.2GHz then the TinkerBoard SHOULD be a real 2x performance of RPI3 in real world apps.. emulatioN????
@Meth
Regarding raw CPU performance Tinkerboard will be twice as fast as RPi 3. Numbers are already available, just use search bar in the upper right corner for an older blog post ‘Android and Linux Benchmarks on MiQi Development Board’ and keep in mind that some numbers might have been affected by throttling back then.
RK3288 can be ‘overclocked’ to 2GHz too but then you need to take care about appropriate power supply and heat dissipation. Search the web (or directly mqmaker forum) for ‘MiQi-based build farm finally up and running’ to get the idea what’s necessary to do number crunching on these devices. Though RPi 3 could be somewhat faster here (Cortex-A53 CPU cores can make use of ARMv8 instruction set) but RPi foundation thinks it is a good idea to provide only software compiled with an outdated GCC for ARMv6 instruction set.
BTW: ‘Real world’ performance is not only about CPU performance, there’s a lot more to be considered (amount of DRAM and memory bandwidth for example, access to storage and if you’re using networking then every RPi is simply a joke with its crippled USB-Ethernet). And as soon as ‘media’ and ‘gaming’ are use cases the other parts of the SoC and driver situation become more and more important (VPU/GPU stuff — you need to overclock an RPi 3 to decode HEVC video in 1080p while RK3288 can decode this in higher resolutions VPU accelerated if drivers are available)
I found the Tinker Board indeed roughly twice as fast (in fact a tiny bit less than twice) as the original 1200 MHz Raspberry Pi Model 3 B when running WEP-M+2 on BOINC. This changed however when I installed Raspberry Pi OS 64-bit. Now the Tinker Board performs slightly less (Tinker Board 1000 credits a day vs Raspi 3 1100 credits a day -was 550 credits a day under 32-bit Raspbian).
@Meth
Tinker board runs RK 3288 not RK3299 = Quad A7 core
Tinker board upscales 1080 for 4k @30fps
http://www.cnx-software.com/2017/01/05/asus-tinker-board-is-a-raspberry-pi-3-alternative-based-on-rockchip-rk3288-processor/
Could we have Cortex-A75 on this list?
@cnxsoft
When compiling an updated list, would be more useful to use a ‘work done’ comparable, i.e. ‘performance per watt’ metric, which I have seen published for big CPU’s – Intel/AMD, but do not recall seeing for ARM based small CPU’s.
Provided adequate cooling, as others have argued, one might consider the MHz incidental to work done for energy expended.
@sola
I can’t find data for it. I should also add low power core like Cortex A35 and A55.
I’ve checked on Wikipedia, and I can see they changed some of their values. What’s a little scary is that they point to this blog post as reference for one of the values, even though I’m clearly pointing to Wikipedia as the source in the article.
Why bother? You just helped confusing people but that doesn’t matter since these are numbers without meaning anyway, the graphs look nice and most people prefer data over information. Seriously: Using DMIPS ratings today for anything else than explaining computer history decades ago is a clear indication of BS collection. Taking two minutes to read through the Dhrystone wikipedia article is sufficient to never ever rely on DMIPS again.
@tkaiser
I suggest we switch to brainfuck benchmarks ;p
https://github.com/blu/brainstorm/blob/master/README.md
@blu
‘Switching’ would assume we would actually use DMIPS. But why would anyone want to do this (except of the ARM marketing guy responsible for this weird DMIPS/MHz stuff 😉 ) I mean 30 years ago DMIPS was a real improvement over the stupid MIPS ratings but today the whole test is just useless and also as expected still more or less a compiler test.
The A53 on RPi 3 scored 2200 DMIPS few years ago (when Raspbian used GCC 4.7), when switching to GCC 4.8 ‘the hardware’ performs slightly better (2450 DMIPS) and with a GCC 6.x allowed to make use of ARMv8 features it’s now +3500 DMIPS. Now think about those weird DMIPS/MHz ratings flying around where older ARM SoCs were benchmarked with older compilers and every reported increase in DMIPS/MHz immediately starts to look very questionable.
Anyway: this whole ‘passive benchmarking’ approach is always wrong since with every new CPU generation code can run more efficient if the compiler is allowed to optimize and especially on ARM SoCs I would focus on the various ‘special engines’ instead of the CPU cores (why decoding video on the CPU cores when there’s a special video engine? Same with encryption, de/compression and so on…)
@tkaiser
I agree DMIPS is superficial, ‘switching from it’ was largely a tongue-in-cheek. That said, we still need estimates of the core CPU functionality (i.e. accelerators are great, but CPUs sometimes are just used for CPU-ing), and the one thing with compilers is that as much as I’d wish this to be the way, newer compilers are *not* always faster — sometimes it’s the opposite. Aside from the trivial ‘sometimes new things are just broken’, the main reason for that is support for older uarchs just, well, bitrot — e.g. old schedulers (i.e. back-ends) are not updated to new mid-end optimizers, performance regressions tests (where available) are left to degrade because ‘too old’, etc. My rule of thumb for every new compiler for every arch I deal with is to test that compiler by all means necessary (that includes synthetic benches), so that negative performance deltas don’t surprise me down the line.
it would be helpful also drawing a chart with DMIPS/MHz/Watt. It will show us the computing efficiency over the electric consumption.