
Yesterday was quite an eventful day with the launch of two low cost 64-bit ARM development boards, namely Raspberry Pi 3 and ODROID-C2, and as usual there were some pretty interesting discussions related to the launch of the boards in the comments section. One of the subject that came is that while Raspberry Pi 3 board is using a 64-bit processor, the operating systems are still compiled with 32-bit instructions (Aarch32) and even optimized for ARMv6, and they intend to keep it that way according to Eben Upton interview:
Eben readily admits that not all the capabilities of the new parts are going to be used at launch, however. “Although it is a 64bit core, we’re using it as just a faster 32-bit core,” he reveals about the Pi 3’s central processing unit. “I can imagine there’d be some real benefits [to 64-bit code]. The downside is that you do really create a separate world. To access that benefit, you’d have to have two operating systems. I’m hoping that someone will come and demonstrate to me that this is a good idea. But there are some really compelling advantages to still being basically ARMv6, and because it’s [Cortex-]A53 it’s a really good 32bit processor.”
So the clear advantage of running ARMv6 32-bit code is that a single image can be used for all Raspberry Pi boards, while of they had to optimize code for each board, they’d have one image for Raspberry Pi (ARMv6), one for Raspberry Pi 2 (ARMv7), and a final one for Raspberry Pi 3 (ARMv8), and obviously that would require a lot of work behind the scene. In theory, there should be a performance advantage of running 64-bit ARM instructions, but the question is how much?
ARM brings some perspective to performance improvement in their presentation “ARMv8: Advantages for Android” where they compare performance improvements of Aarch64 (64-bit ARM instructions) over Aarch32 (32-bit ARM instructions) running benchmarks compiled with either instructions set on Juno development board.
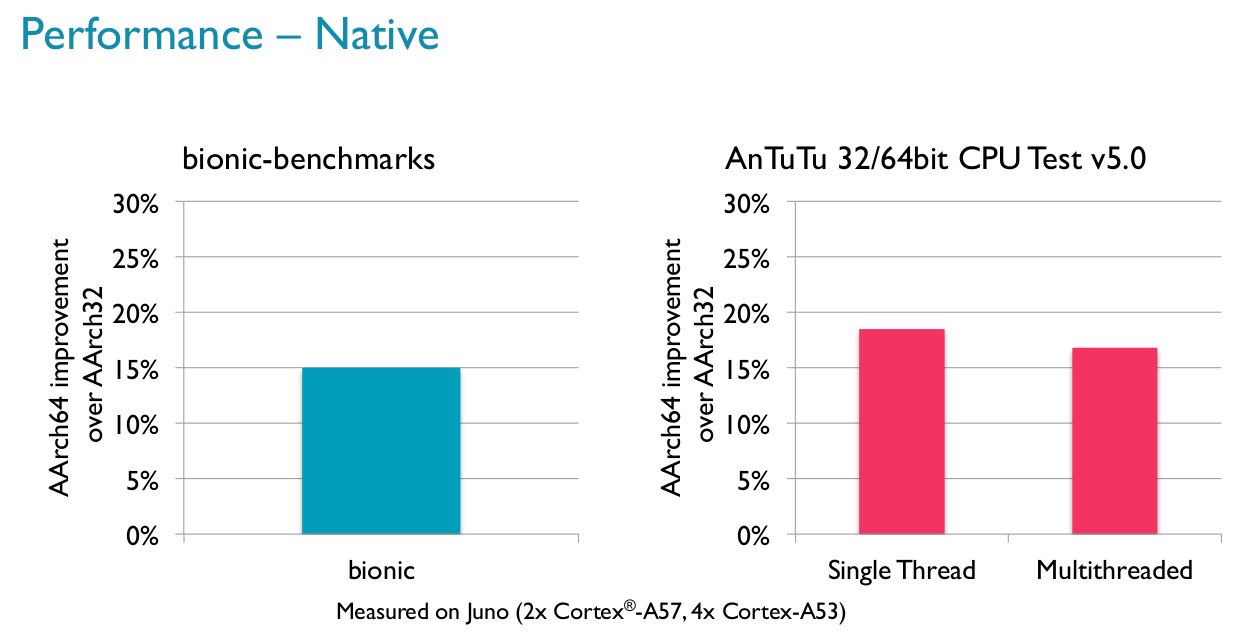
The first charts show native (C/C++ code) performance is between 15% to about 20% faster in bionic benchmarks, and Antutu 5.0 single thread and multi-thread CPU tests.
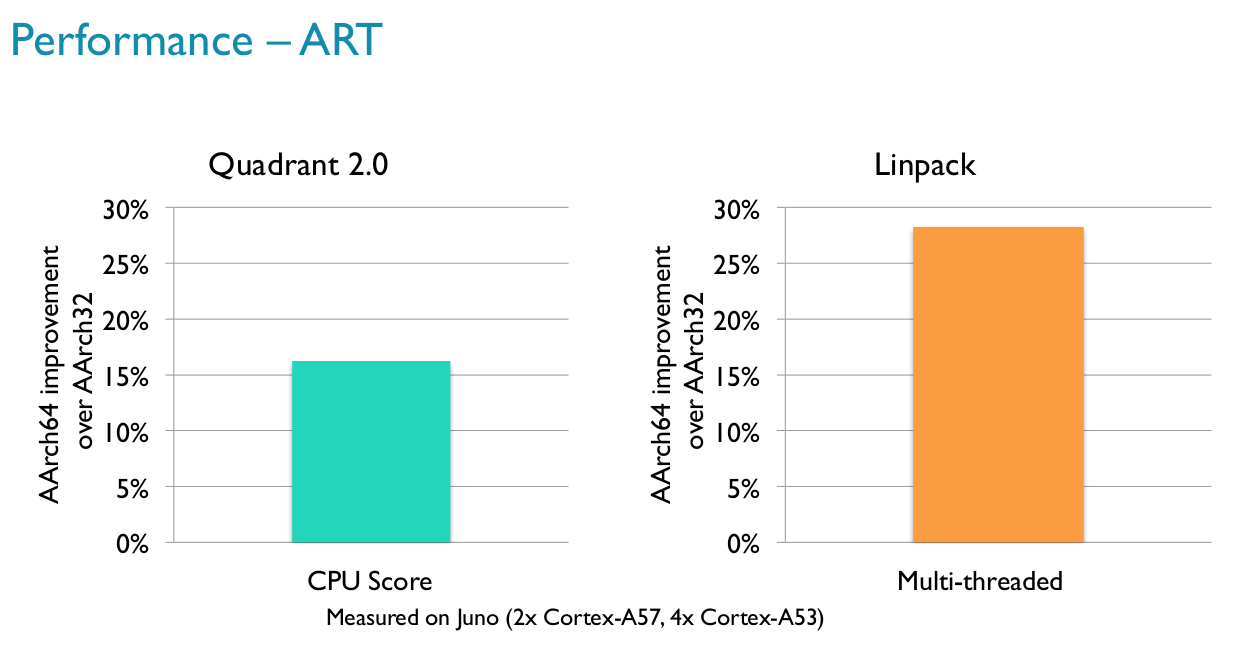
The second chart shows ART (Java runtime) performance is also about 15% better with Aarch64 using Quadrant 2.0 CPU score, and close to 30% faster with Linpack multi-threaded benchmark.
Broadcom BCM2837 processor’s Cortex A53 cores are likely to be further impacted since they are running a code compiled for the older ARMv6, which is slower than ARMv7. Let’s take another fun example. Raspberry Pi 3 benchmarks released on MagPi reveal sysbench completes in 49.02 seconds for multi-threaded CPU test, and tkaiser, an active developer for armbian project, ran sysbench on Pine A64 development on Ubuntu 16.04 64-bit, and the results are quite surprising considered Allwinner A64 is also a quad core Cortex A53 processor @ 1.2 GHz:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
tk@pine64plus:~$ sysbench --test=cpu run --num-threads=4 sysbench 0.4.12: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 4 ... Maximum prime number checked in CPU test: 10000 Test execution summary: total time: 3.2562s total number of events: 10000 total time taken by event execution: 12.9950 per-request statistics: min: 1.21ms avg: 1.30ms max: 13.14ms approx. 95 percentile: 1.30ms Threads fairness: events (avg/stddev): 2500.0000/10.70 execution time (avg/stddev): 3.2487/0.00 |
So it took only 3.25 seconds on Pine A64 with ARMv8 instructions compared to 49.02 seconds on Raspberry Pi 3 with ARMv6 instructions, so it appears that if you are specifically looking for prime numbers it does pay big time (15 times faster) to switch to Aarch64 instructions. Bear in mind that Sysbench command line benchmark has options that can affect the results, and sadly we don’t have the exact command line use for Raspberry Pi 3, but they’ve most likely used the default options as above (maximum prime number: 10,000), since another person ran the benchmark with 20,000 max on RPi3, which completed in around 119 seconds.
Which specific improvements of ARMv8 may bring the extra performance? Reader and commenter “Blu” explains:
Well, for one, compiler’s autovectorization actually works with aarch64 NEON, whereas in armv7 you had mostly to rely on manual vectorization via inline asm. Another big win is the twice-larger GPR & FPR files (when it comes to fp64: D16 -> D32), largely reducing register pressure in compiled (and not only) code. Last but not least, recent compilers have been more focused on AArch64, where they could produce better code vs armv7 not so much because of hw resource discrepancies, but because more man-effort went into AArch64 backends (and the arch provides a bunch of small tweaks that make compiler writer’s lives easier).
To sum it up, one can observe a significant speedup from armv7 to AArch64 for both objective (i.e. larger hw resources) and subjective (i.e. greater man-effort) reasons.
Now the Raspberry Pi 3 is not the only platform to use 32-bit operating systems, as most Android devices and boards I’ve tested so far, excluding DragonBoard 410c combine a 64-bit kernel with 32-bit user space. ODROID-C2 board, however, will support with Ubuntu 16.04 64-bit ARM (aka ARM64).
There’s however a side effect of compiling code with 64-bit instructions, the size gets bigger. Another reader “Jon” compiled code for Rockchip RK3128 Cortex A7 processor (ARMv7/32-bit) and Pine A64 Cortex A53 processor (ARMv8/64-bit), and found some large differences in memory size.
| Binary | ARMv7 Size (Bytes) | ARMv8 Size (Bytes) | Ratio |
| libcrypto.so | 1,052,920 | 1,673,400 | 1.59x |
| toolbox Android 5.1 | 150,836 | 255,280 | 1.69x |
So in case you are really tight on storage or memory, 32-bit code might be a better option.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



Wasn’t the original advantage of Raspbian that it was compiled specifically for the original RPi’s CPU, giving it an advantage over the more portable debian armhf?
Ironic that it is now the conservative / legacy system, but I guess there is always Debian for AArch64 as a starting point…
When calculcating 20,000 prime numbers sysbench takes less than 8 seconds on A64 @1152MHz (still quite unimpressive in terms of stress for the CPU, better use https://github.com/ssvb/cpuburn-arm). That’s a bit faster than on a recent Intel Atom like on the UP board. And that means just that sysbench can not be taken as a ‘benchmark’ any more or to compare different architectures (be it hardware or software)
Since Raspbian is still Debian they could ship one single OS image relying on https://wiki.debian.org/Multiarch checking the SoC ID at boot, then entering the BCM2837 in Aarch64 state (if that’s possible 😉 ) and then running code optimised for ARMv8 on BCM2837 and ARMv6 on the older SoCs. That boot differentiaton works prove the various chinese ‘Fruit Pi’ imitators that ship Raspbian rip-offs that are able to boot natively on Bananas, Oranges and still Raspberries. Multiarch is a different story though and might require a lot of work.
Could another party (Debian, Canonical/Ubuntu) create a 64-bit version for Raspi3, or is that technically impossible because of the binary blobs and closed character of the Raspi?
@Sander
The hardest part for outsiders would most probably be to bring up the BCM2837 in Aarch64 state — compare with http://linux-sunxi.org/Arm64#Boot_modes
Another benefit of ARM64 not shown by these synthetic benchmarks is extra bits to use as tagged pointers. This is a big boon for reference counting or type storage, no need to keep a separate data block for this.
> obviously that would require a lot of work behind the scene.
Obviously. That’s what Linaro has been doing for years, and where those +15/30% come from. And that shows difference between 96boards and things like Pi3 – 96boards are actually used to develop and test 64-bit stuff (also trusted firmware, ACPI and UEFI for ARM, etc.), while Pi3 is, well, just another number in the row. Compatibility is actually a great thing, but I don’t feel compelled to buy a new Pi with the original one sitting on my shelf (I’ll buy Zero when it actually costs $5, just to celebrate the event, but unlikely will use it – too few capabilities).
Or the x86 is such a pile of feces that the vast majority of pure algorithms run better on ARMv8. Luckily for Intel, “real world” performance is about poorly written compilers executing poorly written code and that’s something the x86 does rather well.
Multiarch is already part of respbian for reasons I’m not sure of. I just know it’s mentioned in dmesg. Either way, low level backwards comparability was never part of the RasPi’s design goals. Maybe they’ll make an effort at making sure the python libraries keep working about the same but the typical raspi code bases are tiny and can be ported to just about anything else once the libraries are done.
Multiarch is there because we saw no reason to rip it out.
Unfortunately it’s of limited utility because the Debian multiarch design requires exact match of package versions and there is nearly always going to be some version skew between a derivative and it’s parent (because stuff fails to build, we have to patch stuff for various reasons etc)
@Peter Green
Is Raspbian the result of a completely automated build process or do you hack manually around in the OS image prior to releasing it? I just ask because I naively thought if it’s not possible to create one hybrid OS image to let the build process spit out one image for each architecture instead?
What compiler flags should I use with gcc? Particularly if I am interested in floating point operations?
I am currently using
-Ofast -mcpu=cortex-a53 -mfpu=neon-vfpv4 -mfloat-abi=hard -fdollar-ok -fno-sign-zero -funsafe-math-optimizations
but binaries compiled with -mcpu=cortex-a53 do not appear to run any faster than binaries I compiled on the Pi 2 with -mcpu=cortex-a7 (all other flags the same, both cases running on the Pi 3).
@Rokshox
Also make sure you use a 64-bit compiler. In case you cross-compile you’ll need to use aarch64-linux-gnu-gcc.
ARM64 patch for Raspberry Pi 3 are starting to show in ARM Linux kernel mailing list @ https://lkml.org/lkml/2016/4/4/853