
Ubuntu 16.04 and – I assume – other recent operating systems are still using single-thread version of file & data compression utilities such as bzip2 or gzip by default, but I’ve recently learned that compatible multi-threaded compression tools such as lbzip2, pigz or pixz have been around for a while, and you can replace the default tools by them for much faster compression and decompression on multi-core systems. This post led to further discussion about Facebook’s Zstandard 1.0 promising both smaller and faster data compression speed. The implementation is open source, released under a BSD license, and offers both zstd single threaded tool, and pzstd multi-threaded tool. So we all started to do own little tests and were impressed by the results. Some concerns were raised about patents, and development is still work-in-progess with a few bugs here and there including pzstd segfaulting on ARM.
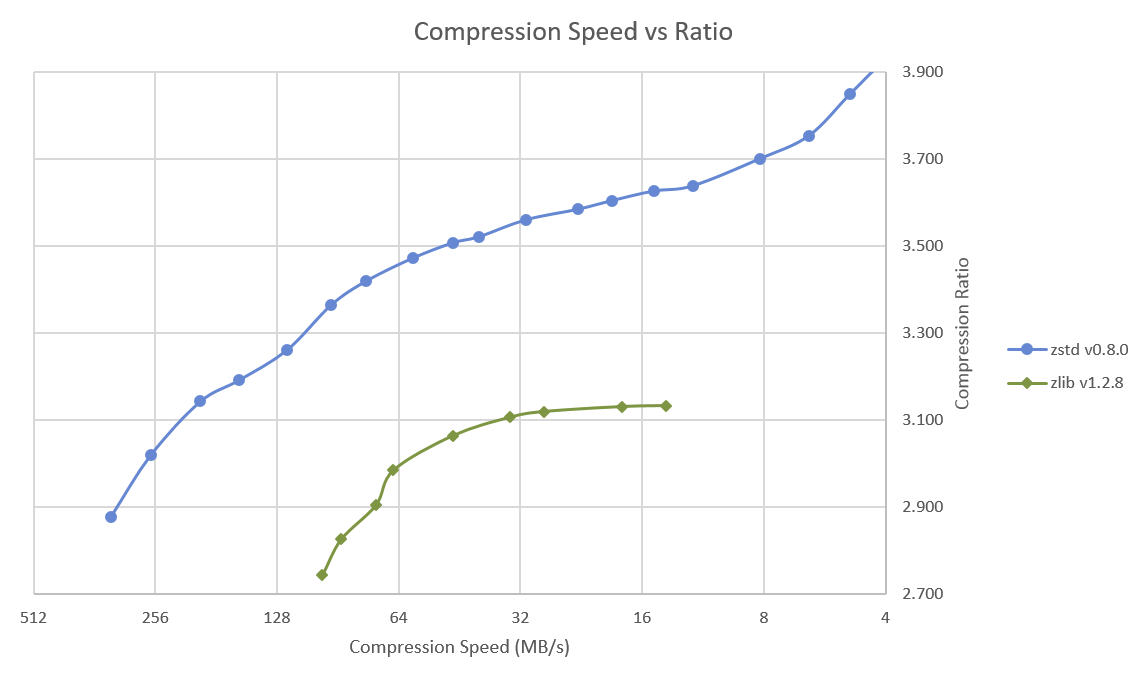
Zlib has 9 levels of compression, while Zstd has 19, so Facebook has tested all compression levels and their speed, and drawn the chart above comparing compression speed to compression ratio for all test points, and Zstd is clearly superior to zlib here.
They’ve also compared compression and decompression performance and aspect ratio for various other competing fast algorithms using lzbench to perform this from memory to prevent I/O bottleneck from storage devices.
| Name | Ratio | C.speed | D.speed |
|---|---|---|---|
| MB/s | MB/s | ||
| zstd 1.0.0 -1 | 2.877 | 330 | 940 |
| zlib 1.2.8 -1 | 2.730 | 95 | 360 |
| brotli 0.4 -0 | 2.708 | 320 | 375 |
| QuickLZ 1.5 | 2.237 | 510 | 605 |
| LZO 2.09 | 2.106 | 610 | 870 |
| LZ4 r131 | 2.101 | 620 | 3100 |
| Snappy 1.1.3 | 2.091 | 480 | 1600 |
| LZF 3.6 | 2.077 | 375 | 790 |
Again everything is a comprise, but Zstd is faster than algorithms with similar compression ratio, and has a higher compression ratio than faster algorithm.
But let’s not just trust Facebook, and instead try ourselves. The latest release is version 1.1.2, so that’s what I tried in my Ubuntu 16.04 machine:
|
1 2 3 4 5 |
wget https://github.com/facebook/zstd/archive/v1.1.2.tar.gz tar xf v1.1.2.tar.gz cd zstd-1.1.2/ make sudo make install |
This will install the latest stable release of zstd to your system, but the multi-thread is not build by default:
|
1 2 |
make -C contrib/pzstd/ sudo cp contrib/pzstd/pzstd /usr/local/bin/ |
There are quite a lot of options for zstd:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
zstd -h *** zstd command line interface 64-bits v1.1.2, by Yann Collet *** Usage : zstd [args] [FILE(s)] [-o file] FILE : a filename with no FILE, or when FILE is - , read standard input Arguments : -# : # compression level (1-19, default:3) -d : decompression -D file: use `file` as Dictionary -o file: result stored into `file` (only if 1 input file) -f : overwrite output without prompting --rm : remove source file(s) after successful de/compression -k : preserve source file(s) (default) -h/-H : display help/long help and exit Advanced arguments : -V : display Version number and exit -v : verbose mode; specify multiple times to increase log level (default:2) -q : suppress warnings; specify twice to suppress errors too -c : force write to standard output, even if it is the console -r : operate recursively on directories --ultra : enable levels beyond 19, up to 22 (requires more memory) --no-dictID : don't write dictID into header (dictionary compression) --[no-]check : integrity check (default:enabled) --test : test compressed file integrity --[no-]sparse : sparse mode (default:enabled on file, disabled on stdout) -M# : Set a memory usage limit for decompression -- : All arguments after "--" are treated as files Dictionary builder : --train ## : create a dictionary from a training set of files -o file : `file` is dictionary name (default: dictionary) --maxdict ## : limit dictionary to specified size (default : 112640) -s# : dictionary selectivity level (default: 9) --dictID ## : force dictionary ID to specified value (default: random) Benchmark arguments : -b# : benchmark file(s), using # compression level (default : 1) -e# : test all compression levels from -bX to # (default: 1) -i# : minimum evaluation time in seconds (default : 3s) -B# : cut file into independent blocks of size # (default: no block) |
Since we are going to compare results to other, I’ll also flush the file cache before each compression and decompression using:
|
1 2 |
sync sudo echo 3 | sudo tee /proc/sys/vm/drop_caches |
I’ll use the default settings to compress Linux mainline directory stored in a hard drive with tar + zstd (single thread):
|
1 2 3 4 5 |
time tar -I zstd -cf linux3.tar.zst linux real 2m10.056s user 1m31.608s sys 0m15.220s |
and pzstd (multiple threads):
|
1 2 3 4 5 |
time tar -I pzstd -cf linux4.tar.zst linux real 0m58.929s user 1m26.560s sys 0m15.464 |
Bear in mind that some time is lost due to I/O on the hard drive, but I wanted to test a real use case here, and if you want to specifically compare the raw performance of compressor you should use lzbench. Now let’s decompress the Zstandard tarballs:
|
1 2 3 4 5 6 7 8 9 10 11 |
mkdir linux3 linux4 time tar -I zstd -xf linux3.tar.zst -C linux3 real 0m45.124s user 0m21.260s sys 0m9.340s time tar -I zstd -xf linux4.tar.zst -C linux4 real 0m38.715s user 0m23.392s sys 0m11.496s |
My machine is based on an AMD FX8350 octa-core processor, and we can clearly see that by comparing real and user time, the test is mostly I/O bound. I’ve repeated those test with other multi-threaded tools as shown in the summary table below.
| Compression | Decompression | File Size (bytes) | Compression Ratio | |||
| Tools | Time (s) | “User” Time (s) | Time (s) | “User” Time (s) | ||
| ztsd | 130.056 | 91.608 | 45.124 | 21.26 | 1,881,020,744 | 1.48 |
| pzstd | 58.929 | 86.56 | 38.175 | 23.39 | 1,883,697,296 | 1.48 |
| lbzip2 | 84.216 | 353.84 | 37.109 | 167.416 | 1,855,837,345 | 1.50 |
| pigz | 61.121 | 121.332 | 34.36 | 15.26 | 1,903,915,372 | 1.47 |
| pixz | 177.596 | 1233.88 | 36.24 | 78.116 | 1,782,756,524 | 1.57 |
| pzstd -19 | 275.361 | 1939.536 | 26.85 | 21.832 | 1,794,035,552 | 1.56 |
I’ve included both “real time” and “user time”, as the latter shows how much CPU time the task has spent on all the cores of the system. If user time is large that means the task required lots of CPU power, and if a task completes in about the same amount of “real time”, but a lower “user time”, it means it was likely more efficient, and consumes less power. pigz is the multi-threaded version of xz algorithm relying on lzma compression which delivers a high compression ratio, at the expense of longer compression time, so I also run pzstd with level 19 compression to compare:
|
1 2 3 4 5 |
time tar -I "pzstd -19" -cf linux7.tar.zst linux real 4m35.361s user 32m19.536s sys 0m18.500s |
Zstandard compression ratio is similar to the one of lbzip2 with default settings, but compression is quite faster, and much more power efficient. Compared to gzip, (p)zstd offers a better compression ratio, against with default settings, and somewhat comparable performance. pixz offers the best compression ratio, but takes a lot more time to compress, and uses more resources to decompress compared to Zstandard and Pigz. Pzstd with compression level 19 takes even more time to compress, and is getting close to pixz compression, but has the advantage of being much faster to decompress.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



Also interesting: https://github.com/lzfse/lzfse
I used zstd to demonstrate a ‘backup/clone internal eMMC of an SBC to a remote machine’ use case. Usually this process is bottlenecked by both CPU (to compress data) and IO (speed to read from the device) but depending on acting on ‘real data’ or unused space (zeroed out) it’s most of the times either/or.
So by using single-threaded zstd (on ARM pzstd doesn’t work currently) and adding parallelisms manually it can be ensured that both backup time and archive size needed decrease.
All details: https://forum.armbian.com/index.php/topic/2096-backup-script-for-block-devices/?p=21729
Why pzstd does not work on arm?
@zoobab
I’ve linked to the bug report in the post. pzstd will segfault.
How about comparing with 7-zip (.7z format)? That would be something!
@Jay
Ahem, .7z is more of a container than a ‘format’ since 7-zip supports various compression schemes (LZMA/LZMA2, PPMd, BZip2 and even more — for example optimized ZIP/deflate or even zstandard, just do a web search for ‘7-zip zstandard’).
As used most of the times .7z means LZMA2 so you can easily compare yourself with .xz (see first link in the blog post for pixz results).
@Jay
7z should be pretty similar to xz as both are based on lzma2. They are different implementation though, so maybe there are some differences in term of performance.
@Jean-Luc Aufranc (CNXSoft)
Performance of xz utilities and 7za/7zr is almost the same with identical compression settings. But you need pixz to get multithreaded behaviour and then there might be slight speed differences. IMO not worth the efforts to test/compare given the availability of zstandard now 😉
I have sent an email to one of the Facebook guys to find out if they have filed any patents on Zstandard. Let’s wait and see.
hi, i did quick script to compare different parallel compressors. cpu was core2duo @ 2.4ghz, machine was a linux64 vm running on win7_64. os was standard jessie install without any optimizations. all tools were from jessie, only zstd was compiled from source sid package. apparently zstd isnt the best one if you prefer compression ratio. with pixz you can get more at almost any compression level (only with lowest zstd was better at speed, but since you dont usually run hundreds of compression threads i guess it doesnt matter). test files were a /system partition of my android 4.4.2 for… Read more »
And then you know why pixz simply doesn’t matter and why zstd rocks (I don’t write about pzstd for a reason).
zstandard / zstd will be added to the Linux kernel: http://www.phoronix.com/scan.php?page=news_item&px=Facebook-Linux-Zstd
Directly link to patch sets: http://lkml.iu.edu/hypermail/linux/kernel/1708.0/03746.html
Those also add the compression standard to BtrFS and SquashFS file systems.