
After Zopfli, Google has now announced and released Brotli, a new compression algorithm to make the web faster, with a ratio compression similar to LZMA, but a much faster decompression, making it ideal for low power mobile devices.
Contrary to Zopfli that is deflate compatible, Brotli is a complete new format, and combines “2nd order context modeling, re-use of entropy codes, larger memory window of past data and joint distribution codes” to achieve higher compression ratios.
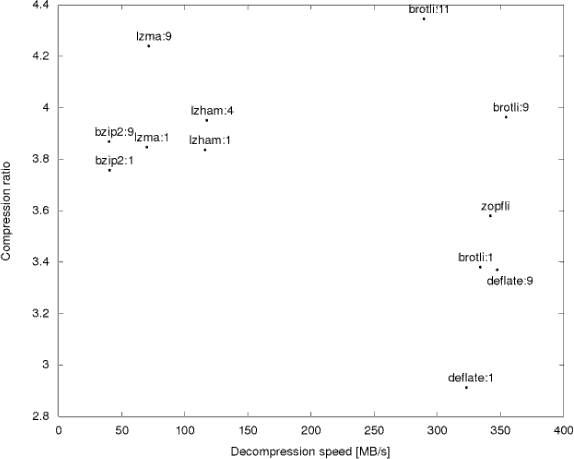
Google published some benchmark results comparing Brotli to other common algorithms. Since the company aims to make the web faster, the target is to decrease both downloading time (high compression ratio), and rendering time (fast decompression speed), and Brotli with a quality set to 11 is much better than competitor once both parameters are taken into account.
As you’d expect the source code can also be pulled from Github. So I gave it a quick try myself in an Ubuntu PC, and installed it as follows:
|
1 2 3 4 |
git clone https://github.com/google/brotli.git cd brotli/tools make -j8 sudo cp bro /usr/local/bin |
The application usage info is not really detailed, but good enough to get started:
|
1 2 3 |
bro -h Usage: bro [--force] [--quality n] [--decompress] [--input filename] [--output filename] [--repeat iters] [--verbose] |
I was a little too optimistic at first, and started by compressing a 2.4GB firmware file using quality 11 with bro, but I quickly found out it would take a very long time, as the compression speed is rather slow… Google white paper shows Brotli compresses 0.5 MB of data per second when quality is set to 11, and they performed the test on a server powered by an Intel Xeon E5-1650 v2 running at 3.5 GHz…
So instead I switched to Linux 4.2 Changelog text file I created a few days ago that’s only 14MB in size.
|
1 2 3 4 5 6 |
time bro --quality 11 --input Linux_4.2_Changelog.txt --output Linux_4.2_Changelog.txt.bro --verbose Brotli compression speed: 0.283145 MB/s real 0m46.648s user 0m46.093s sys 0m0.420s |
My machine is based on an AMD FX8350 processor (8 cores @ 4.0 GHz), and it took about 46.6 second to compress the file.
Then I switched to xz which implements LZMA compression, and compression preset 9.
|
1 2 3 4 5 |
time xz -9 Linux_4.2_Changelog.txt real 0m6.235s user 0m6.170s sys 0m0.024s |
Compression speed is much faster with xz, about 7.5 times faster , but it’s not really a concern for Google, because in their use cases, the file is compressed once, but downloaded and decompressed millions of times. It’s also interesting to note that both tools only used one core to compress the file.
Let’s check the file sizes.
|
1 2 3 |
ls -l L* -rw------- 1 jaufranc jaufranc 2530677 Sep 23 21:19 Linux_4.2_Changelog.txt.bro -rw-rw-r-- 1 jaufranc jaufranc 2457152 Sep 2 15:24 Linux_4.2_Changelog.txt.xz |
In my case, LZMA compression ratio was also slightly higher than Brotli compression ratio, but that’s only for one file, and Google’s much larger test sample (1,000+ files) shows a slight advantage to Brotli (11) over LZMA (9).
Decompression is much faster than compression in both cases:
|
1 2 3 4 5 |
time xz -d Linux_4.2_Changelog.txt.xz real 0m0.196s user 0m0.159s sys 0m0.036s |
|
1 2 3 4 5 |
time bro --decompress --input Linux_4.2_Changelog.txt.bro --output Linux_4.2_Changelog.txt.decode real 0m0.064s user 0m0.044s sys 0m0.020s |
Brotli is indeed considerably faster at decompressing than LZMA, about 3 times faster, just as reported in Google’s study.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



It’s worth noting that, unlike other compression algorithms, brotli uses a static dictionary based on common English, Spanish, HTML etc. That’s not a bad idea but it is sort-of cheating when you’re doing a comparison against other algorithms.
@opk
Why do you see it like cheating?
If using a certain dictionary in certain applications proves to be useful, then this is a legitimate approach.
Using the term quality to compress a video file with brotli, kind of thru me off… should be called compression strength or something like that, no?
Groan, all i can see is someone rushing to use it for everything all of a sudden and “turning it up to 11”, although that compression speed needs a lot of work.
I also wonder what the decompression memory requirements are (incl fixed overheads) and can it stream the process? And which of those tools isn’t honouring the umask properly – the generated file should have the same permissions.
FWIW try adding overflow:auto to your pre style.
Also a bummer threading isn’t utilised.
@notzed
Thanks for preformatted style tip. It did not work, but gave me the will and power to fix that issue :). Other solutions on the net did not work either (http://stackoverflow.com/questions/248011/how-do-i-wrap-text-in-a-pre-tag), but I found Crayon Syntax Highlighter plugin (https://wordpress.org/plugins/crayon-syntax-highlighter/), that’s quite neat with icon to toggle line numbers, wrapping, and more.
@LinAdmin
LZMA/deflate support custom preset dictionaries. It would’ve probably been fairer if a comparison was made with those algorithms using a similar preset dictionary.
Another thing to note is that Brotli’s max dictionary size is 16MB, which is another facet which makes this algorithm very web focused (as opposed to a more general purpose algorithm like LZMA).
Hi, a good review and good for us all if Brotli manages to boost the browsing. @Jean-Luc Aufranc (CNXSoft) Please run your test with ‘dickens’ (from Silesia Corpus) too, it is one of the most used testdatafiles in compression community for a reason, it represents English texts in its fat book form (2 Bibles). Just use ‘-v’ option in order we all to see what is the Brotli’s decompression speed on your Vishera, on my old Core 2 laptop I reached 145 MB/s, for more info: https://github.com/google/brotli/issues/174 Also, I shared my opinion with Brotli’s team about their current defaults and… Read more »
@Georgi Marinov (@Sanmayce)
I can test it, but could you provide the download link for dickens?
A single script that I can run to provide the results you want would be even nicer.
@Jean-Luc Aufranc (CNXSoft) >I can test it, but could you provide the download link for dickens? Bravo, I very much want to see how “low caliber” CPUs execute them, ‘dickens’ is inhere: http://sun.aei.polsl.pl/~sdeor/index.php?page=silesia http://sun.aei.polsl.pl/~sdeor/corpus/dickens.bz2 >A single script that I can run to provide the results you want would be even nicer. Sure, but I am lame in *nix prompt, so an “estimate” for *nix: Step #1: Download the whole package all-in-one: https://mega.nz/#!c0hBkCYQ!U2irEQPbiig6xcUD0mXIVn7P-suzTcku6COKtkvKHmo Step #2: Download the C source: https://software.intel.com/sites/default/files/managed/6d/27/Nakamichi_Shifune.zip Step #3: Compile the C source: ./gcc -O3 -fomit-frame-pointer Nakamichi_Shifune.c -o Nakamichi_Shifune.elf -D_N_XMM -D_N_prefetch_4096 -D_N_Branchfull Step #4: ./Nakamichi_Shifune.elf dickens.Nakamichi /report Sorry… Read more »
@Georgi Marinov (@Sanmayce)
The showdown package is only for Windows.
Nakamichi_Shifune won’t build:
gcc -O3 -fomit-frame-pointer Nakamichi_Shifune.c -o Nakamichi_Shifune.elf -D_N_XMM -D_N_prefetch_4096 -D_N_Branchfull
In file included from Nakamichi_Shifune.c:940:0:
/usr/lib/gcc/x86_64-linux-gnu/4.8/include/smmintrin.h:31:3: error: #error “SSE4.1 instruction set not enabled”
# error “SSE4.1 instruction set not enabled”
Here are the results for brotli:
time bro –quality 11 –input dickens –output dicken.bro –verbose
Brotli compression speed: 0.284661 MB/s
real 0m34.219s
user 0m33.767s
sys 0m0.383s
jaufranc@FX8350:~/edev/sandbox/brotli$ time bro –decompress –input dicken.bro –output dicken.out –verbose
Brotli decompression speed: 195.78 MB/s
real 0m0.056s
user 0m0.032s
sys 0m0.020s
@Jean-Luc Aufranc (CNXSoft) Oh, there is difference between GCC Windows and GCC Linux, maybe GCC is not fully installed. Just comment the line #940, SSE4.1 is actually not used just SSE2: 938 #ifdef _N_XMM 939 #include // SSE2 intrinsics //940 #include // SSE4.1 intrinsics 941 #endif It should work this way. I was lazy to make time reporting portable enough: k = (((float)1000*TargetSize/(clocks2 – clocks1 + 1))); k=k>>20; k=k*Trials; printf(“RAM-to-RAM performance: %d MB/s.\n”, k); If clocks_per_sec is not 1000 as in Windows, the MB/s would be unusable. Anyway, thanks for your FX8350 result, 195MB/s is still far from my ~512MB/s… Read more »
@Georgi Marinov (@Sanmayce) The reporting does not seem to work that well on Linux… This is what I got: ./Nakamichi_Shifune.elf ../Showdown_Brotli_vs_Zstd_vs_GZIP_vs_Shifune/dickens.Nakamichi /report Nakamichi 'Shifune-Totenschiff', written by Kaze, based on Nobuo Ito's LZSS source, babealicious suggestion by m^2 enforced, muffinesque suggestion by Jim Dempsey enforced. Decompressing 3740418 bytes ... RAM-to-RAM performance: 0 MB/s. Memory pool starting address: 0x7fec65545040 ... 64 byte aligned, OK Copying a 512MB block 1024 times i.e. 512GB READ + 512GB WRITTEN ... memcpy(): (512MB block); 524288MB copied in 157187953 clocks or 0.003MB per clock RAM-to-RAM performance vs memcpy() ratio (bigger-the-better): 0% 12345678 ./Nakamichi_Shifune.elf ../Showdown_Brotli_vs_Zstd_vs_GZIP_vs_Shifune/dickens.Nakamichi /reportNakamichi 'Shifune-Totenschiff', written… Read more »
@Jean-Luc Aufranc (CNXSoft) Thank you for wrestling with my code 😉 If you still care, just replace the ‘1000’ with ‘CLOCKS_PER_SEC’ in next three lines and voila: //k = (((float)1000*TargetSize/(clocks2 - clocks1 + 1))); k=k>>20; k=k*Trials; k = (((float)CLOCKS_PER_SEC*TargetSize/(clocks2 - clocks1 + 1))); k=k>>20; k=k*Trials; ... //k = (((float)1000*SourceSize/(clocks2 - clocks1 + 1))); //k=k>>10; k = (((float)CLOCKS_PER_SEC*SourceSize/(clocks2 - clocks1 + 1))); //k=k>>10; ... //j = (float)1000*1024*( 512 )/ ((int) durationGENERIC); j = (float)CLOCKS_PER_SEC*1024*( 512 )/ ((int) durationGENERIC); This is the dump from my MinGW console: D:\Internetdownloads\Nakamichi_Shifune>gcc --version gcc (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 5.1.0 Copyright (C) 2015 Free Software Foundation,… Read more »
@Georgi Marinov (@Sanmayce) ./Nakamichi_Shifune.elf ../Showdown_Brotli_vs_Zstd_vs_GZIP_vs_Shifune/dickens.Nakamichi /report Nakamichi 'Shifune-Totenschiff', written by Kaze, based on Nobuo Ito's LZSS source, babealicious suggestion by m^2 enforced, muffinesque suggestion by Jim Dempsey enforced. Decompressing 3740418 bytes ... RAM-to-RAM performance: 960 MB/s. Memory pool starting address: 0x7f67ee8fd040 ... 64 byte aligned, OK Copying a 512MB block 1024 times i.e. 512GB READ + 512GB WRITTEN ... memcpy(): (512MB block); 524288MB copied in 154956606 clocks or 0.003MB per clock RAM-to-RAM performance vs memcpy() ratio (bigger-the-better): 28% 12345678 ./Nakamichi_Shifune.elf ../Showdown_Brotli_vs_Zstd_vs_GZIP_vs_Shifune/dickens.Nakamichi /reportNakamichi 'Shifune-Totenschiff', written by Kaze, based on Nobuo Ito's LZSS source, babealicious suggestion by m^2 enforced, muffinesque suggestion by… Read more »
@Georgi Marinov (@Sanmayce) If you want mobile device top of performance, I’ve just tested both tools on the Orange Pi 2 mini board (ARM Cortex A7 @ 1.5GHz) I have on my desk. bro --decompress --input dicken.bro --output dicken.result --verbose Brotli decompression speed: 25.3212 MB/s 12 bro --decompress --input dicken.bro --output dicken.result --verboseBrotli decompression speed: 25.3212 MB/s I stopped your test after 20 minutes as it still had not completed the first part (stuck at Decompressing 3740418 bytes …), and I’ll go to bed now… 🙂 I can see the x86 code uses SSE instructions, so unless there’s also some… Read more »
Oh man, these lilliput machines are so exciting! I know next to nothing about ARM, yet I see that v7 has 32bit registers whereas v8 has already 64bit, this will hurt Shifune’s decoding speed. The price is lovable, just for me. To avoid waiting the ‘memcpy()’ mumbo-jumbo segment, it can be skipped by adding ‘BandwidthFlag=0;’ that way: BandwidthFlag=0; if (BandwidthFlag) { // Benchmark memcpy() [ ... Please run it again, these little scamps are so sweet&cheap. By the way, by chance I have become the author of fastest hash function (for table lookups), called FNV1a-YoshimitsuTRIAD, with supremacy especially on ARM:… Read more »
@Jean-Luc Aufranc (CNXSoft)
Ugh, stupid of me, you said that it stuck still decompressing, don’t know what is the cause, maybe the XMM macro is the culprit, you could comment it and put below it standard memcpy() as below:
#ifdef _N_XMM
//SlowCopy128bit( (const char *)( (uint64_t)(srcLOCAL+1) ), retLOCAL );
memcpy(retLOCAL, (const char *)( (uint64_t)(srcLOCAL+1) ), 16);
Being little endian (as x86) it should work.
@Georgi Marinov (@Sanmayce)
I had only compiled the code with:
gcc -O3 -fomit-frame-pointer Nakamichi_Shifune.c -o Nakamichi_Shifune.elf
maybe that’s why it looped.
Anyway, I’ve done the modifications with memcpy, and built it as on x86, but it will just segfault as I run the program.
@Jean-Luc Aufranc (CNXSoft) >I had only compiled the code with: >gcc -O3 -fomit-frame-pointer Nakamichi_Shifune.c -o Nakamichi_Shifune.elf >maybe that’s why it looped. If this was the full compile line no wonder, you cannot omit ‘-D_N_XMM’, it should be like this: gcc -O3 -fomit-frame-pointer Nakamichi_Shifune.c -o Nakamichi_Shifune.elf -D_N_XMM -march=armv7v >Anyway, I’ve done the modifications with memcpy, and built it as on x86, but it will just segfault as I run the program. Never compiled for ARM, but shouldn’t you specify ARM target in GCC command options?! https://gcc.gnu.org/onlinedocs/gcc/ARM-Options.html It says that “not all architectures are recognized” automatically: -march=name This specifies the name of… Read more »
@Georgi Marinov (@Sanmayce) I should not matter on ARMv7 platforms, but for earlier versions it might become an issue. Normally, you’ll get the message “illegal instruction” if you try to run the program build for ARMv7 on an earlier version. If you don’t have ARM hardware right now and are interested in making your program work on ARM, I’d recommend getting one like the Raspberry Pi 2. You could also run QEMU with ARM Linux. I’ve explained how to do so on an older post, which may not be 100% up-to-date: http://www.cnx-software.com/2011/09/26/beagleboard-emulator-in-ubuntu-with-qemu/ Alternatively, you could also rent an ARM server… Read more »