
Arm Cortex A75 based processors are only found in a few SoCs and devices, but Arm keeps on innovating, and they’ve now announced a new suite of of IP with Cortex-A76 CPU enabling 35 percent more performance, and Mali-G76 GPU with ML support and 30 percent higher efficiency and performance.
SoC based on those new CPU and GPU IP will provide “laptop-class” performance, and the company also announced Arm Mali-V76 VPU with support for 8K video decoding and encoding.
Arm Cortex A76
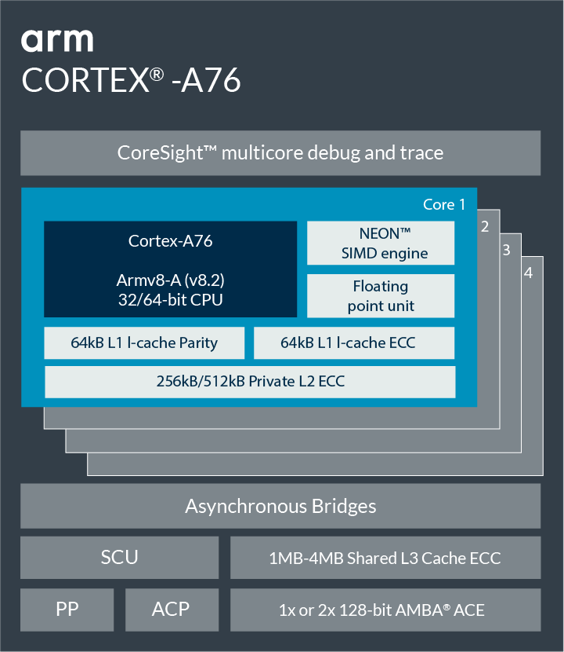
After Cortex A75, the Arm Cortex-A76 CPU is the second high performance processor core based on DynamIQ technology, and beside the 35 percent performance gain mentioned in the introduction, it also offers 40 percent improved efficiency, as well as delivers 4x compute performance improvements for AI/ML at the edge.
Highlights of Cortex A76:
- Architecture – Armv8-A (Harvard) with Armv8.1, Armv8.2, Armv8.3 (LDAPR instructions only), cryptography and RAS extensions
- ISA support – A64; A32 and T32 (at the EL0 only)
- Microarchitecture
- Pipeline – Out-of-order
- Superscalar
- NEON / Floating Point Unit
- Optional Cryptography Unit
- Up to four CPUs in cluster
- Physical addressing (PA) – 40-bit
- Memory system and external interfaces
- 64KB L1 I-Cache / D-Cache
- 256KB to 512KB L2 Cache
- Optional 512KB to 4MB L3 cache
- ECC Support, LPAE
- Bus interfaces – AMBA ACE or CHI
- Optional ACP
- Optional Peripheral Port
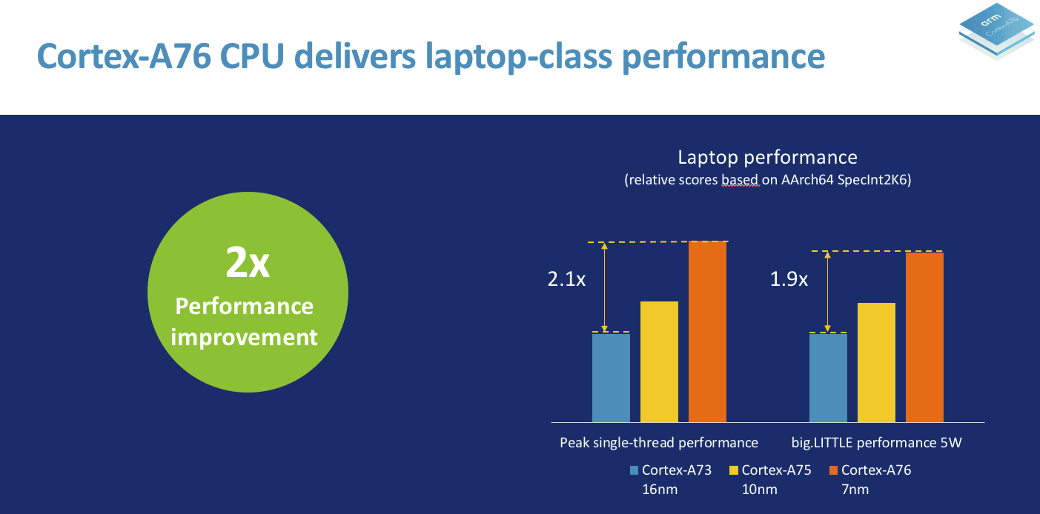
Cortex A76 SoC should provide around twice the performance as Cortex A73 SoC in laptops, considering the improvements in microarchitecture, lower process node (7nm vs 16nm), and higher CPU frequency (Up to 3GHz+). big.LITTLE performance at the same power envelop (5W) should also be about twice as good.
Some of the key microarchitectural enhancements include:
- Decoupled branch prediction and instruction fetch – Built to hide latency at high bandwidth, the in-order Cortex-A76 front-end is able to fetch 4 to 8 instructions per cycle, using multi-level branch target caches and hybrid indirect predictor to sustain the maximum throughput.
- Arm’s first 4-wide decode core, increasing the maximum instruction per cycle capability. Up to 8 operations per cycle can then be dispatched to the out-of-order core, supporting a wider area-/power-optimized instruction window.
- More integer and vector execution throughput – Quad-issue integer units are integrated in the core including 3x simple ALU and 1x multi-cycle integer. Moreover, Cortex-A76 supports dual-issue native 16B (128-bit) vector and floating-point units, twice the throughput of any previous Arm CPU. Vitally, it can deliver the 4x ML performance improvements we mentioned earlier.
- Enhanced memory system – The full cache hierarchy is co-optimized for latency and bandwidth, with a sophisticated 4th generation prefetcher, deep memory-level parallelism
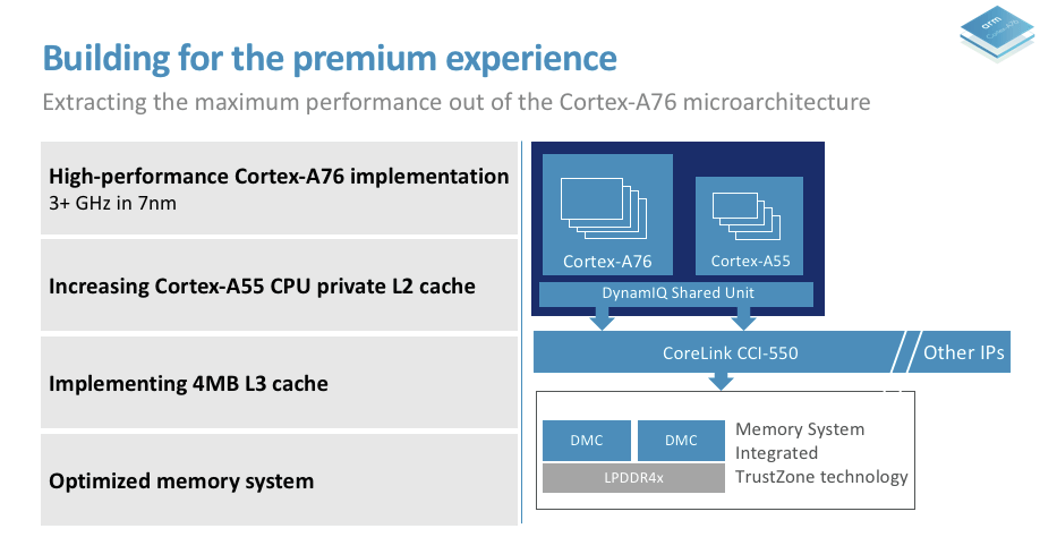
You’ll find more details in a dedicated Arm Community blog post, and the product page.
Arm Mali-G76
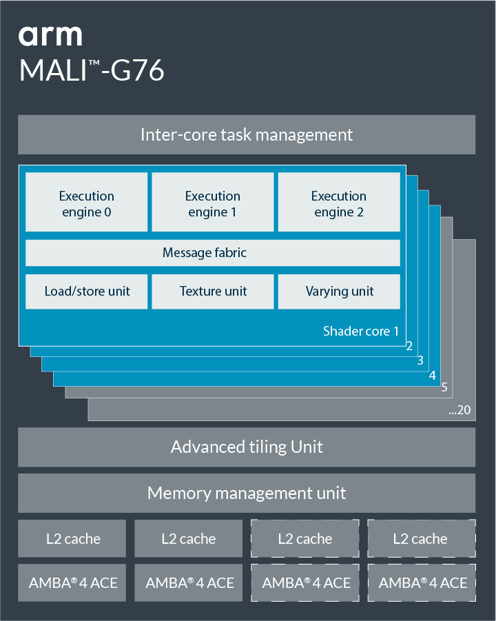 Beside the 30% improvement in performance density and energy efficiency, Arm Mali-G76 Bifrost architecture based GPU also delivers around 2.7 times machine learning (ML) improvements over Mali-G72 GPU.
Beside the 30% improvement in performance density and energy efficiency, Arm Mali-G76 Bifrost architecture based GPU also delivers around 2.7 times machine learning (ML) improvements over Mali-G72 GPU.
Some of the specifications of Mali-G76 GPU:
- Anti-Aliasing – 4x MSAA, 8x MSAA, 16x MSAA
- API Support – OpenGL ES 1.1, 2.0, 3.1, 3.2, Vulkan 1.1, OpenCL 1.1, 1.2, 2.0 Full Profile
- Bus Interface – AMBA 4, ACE-LITE
- L2 Cache – 512KB to 4MB
- Scalability – 4 to 20 Cores
- Adaptive Scalable Texture Compression (ASTC) – Low Dynamic Range (LDR) and High Dynamic Range (HDR), supports both 2D and 3D images.
- Arm Frame Buffer Compression (AFBC) – Version 1.2; 4×4 pixel block size

The GPU will be used in “premium mobile”, virtual reality, machine learning, and automotive applications.
For more information, check out the blog post and product page on Arm’s website.
Arm Mali-V76

Mali-V76 is the latest video processing unit (VPU) from Arm with support for 8K video decoding @ 60 fps, and also suitable for video walls with 2×2 4K UHD videos, or 4×4 1080p HD videos.
Main features of Mali-V76 VPU:
- Multi-standard video processor
- 10/8-bit HEVC, VP9, VP8, H.264, AVS+/AVS and legacy
- Simultaneous encode and decode
- Programmability/flexibility
- Scalable 2-8 cores (8K60D/8K30E)
No mention of AV1 codec, so we’ll probably have to wait for 2020 or beyond before AV1 makes it into silicon.

Mali-V76 is an evolution of Mali-V61 video processor with twice the decode performance, a 40% smaller area for 4K120 performance, 25% additional bitrate saving , twice the bus fabric latency tolerance, and additional support for 10-bit H.264 codec and 8-bit AVS+/AVS decode.
Again, you can find out more on Arm’s product page and blog post about Mali-V76 VPU.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



4-decode/8-dispatch.. Arm Holdings gone big league now.
I don’t know whether designing a NOR flash chip implies a radically different process compared to main SoCs, but I wish ARM could do something to have every SoC vendors embed something like a small NOR flash inside their silicon (e.g. embed it within ARM IP) so that we could place the dtb/uboot inside and avoid definitely board-specific kernels…
Reading elsewhere I notice they seem to have another core too
” Arm is preparing a separate core for wired servers and networking gear. The A76 aims to expand Arm’s dominance in smartphones into laptops with 4+4 A76/A55 configurations sporting large caches.”
Shame no 4GHz for table top
“The comparisons are based on CPUs running at similar frequencies. Arm acknowledged that Intel’s chips typically support higher frequencies than Arm’s cores. Although TSMC announced a 4-GHz A72 test chip, few SoC makers are expected to push their designs to such extreme speeds.”
Do you think that A76 would be implemented in Snapdragon 855?
The 855 is going to be 7nm (and not 10nm like 845), so if it would also implement major architectural advances, it would be even greater than what I expected it be!
Sometimes ARM shares its designs with its partners like Qualcomm, prior to the official launch. So maybe it’s not too late.
And Qualcomm modifies the core’s design a bit, but it is not a fully custom one, like Qualcomm used to Make until the 800/801.
In second thought, A75 was introduced exactly one year ago – and it was in time to be implemented in SD845, so it should be a similar case with A76 and SD855.
And maybe before that, we would see Snapdragon 1000 implementing A76 – for ultrabook laptops.
The SD1000 would consume 6.5 Watts, as opposed to 5 Watts that SD845 consumes.
Any word on a Spectre resistant/immune processor from ARM?
> Any word on a Spectre resistant/immune processor from ARM
I looked for this as well but didn’t find any such info. However it’s indicated that the branch predictor was significantly improved, and that the fetch unit can fetch 4 to 8 instructions per cycle. If that’s the case, we could imagine that after a branch, both targets are systematically fetched, making thus voiding any attempt at running side-channel timing attacks without killing the benefits of branch prediction.
https://developer.arm.com/support/arm-security-updates/speculative-processor-vulnerability
“Cortex-A76 (released end May 2018) is resilient to Variants 2 and 3.”
Thank you! Thanks to willy as well.