
Qualcomm Centriq 2400 ARM Server-on-Chip has been four years in the making. The company announced sampling in Q4 2016 using 10nm FinFET process technology with the SoC featuring up to 48 Qualcomm Falkor ARMv8 CPU cores optimized for datacenter workloads. More recently, Qualcomm provided a few more details about the Falkor core, fully customized with a 64-bit only micro-architecture based on ARMv8 / Aarch64.
Finally, here it is as the SoC formally launched with the company announcing commercial shipments of Centriq 2400 SoCs.

Qualcom Centriq 2400 key features and specifications:
- CPU – Up to 48 physical ARMv8 compliant 64-bit only Falkor cores @ 2.2 GHz (base frequency) / 2.6 GHz (peak frequency)
- Cache – 64 KB L1 instructions cache with 24 KB single-cycle L0 cache, 512 KB L2 cache per duplex; 60 MB unified L3 cache; Cache QoS
- Memory – 6 channels of DDR4 2667 MT/s for up to 768 GB RAM; 128 GB/s peak aggregate bandwidth; inline memory bandwidth compression
- Integrated Chipset – 32 PCIe Gen3 lanes with 6 PCIe controllers; low speed I/Os; management controller
- Security – Root of trust, EL3 (TrustZone) and EL2 (hypervisor)
- TDP – < 120W (~2.5 W per core)
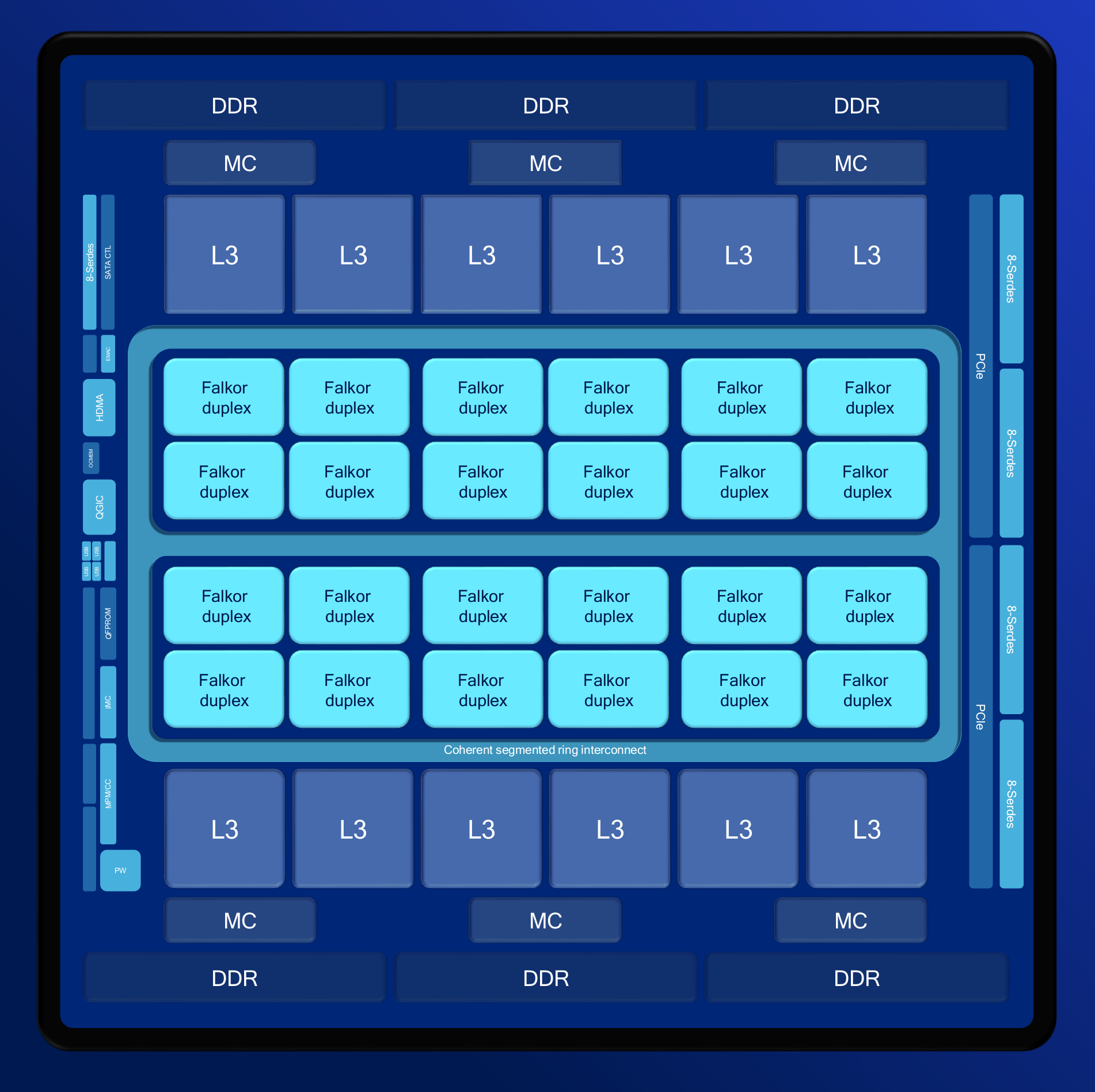
The SoC is ARM SBSA v3 compliant, meaning it can run any compliant operating systems without having to resort to “cute embedded nonsense hacks“. The processor if optimized for cloud workloads, and the company explains the SoC are already been used demonstrated for the following tasks:
- Web front end with HipHop Virtual Machine
- NoSQL databases including MongoDB, Varnish, Scylladb
- Cloud orchestration and automation including Kubernetes, Docker, metal-as-a-service
- Data analytics including Apache Spark
- Deep learning inference
- Network function virtualization
- Video and image processing acceleration
- Multi-core electronic design automation
- High throughput compute bioinformatics
- Neural class networks
- OpenStack Platform
- Scaleout Server SAN with NVMe
- Server-based network offload
Three Qualcom Centriq 2400 SKUs are available today
- Centriq 2434 – 40 cores @ 2.3 / 2.5 GHz; 50 MB L3 cache; 110W TDP
- Centriq 2452 – 46 cores @ 2.2 / 2.6 GHz; 57.5 MB L3 cache; 120W TDP
- Centriq 2460 – 48 cores @ 2.2 / 2.6 GHz; 60 MB L3 cache; 120W TDP
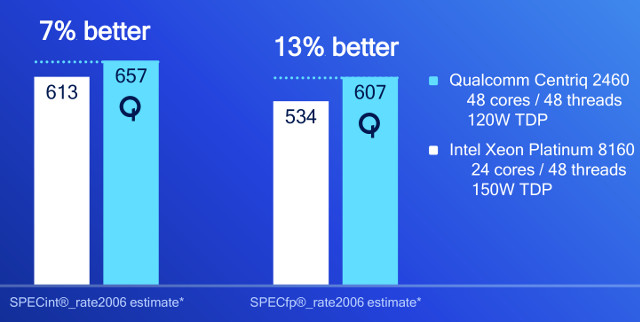
Qualcomm Centriq 2460 (48-cores) was compared to an Intel Xeon Platinum 8160 with 24-cores/48 threads (150 W) and found to perform a little better in both integer and floating point benchmarks.
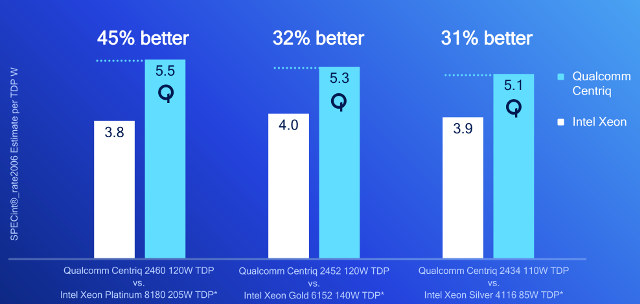
 The most important metrics for server SoCs are performance per thread, performance per watt, and performance per dollars, so Qualcomm pitted Centriq 2460, 2452 and 2434 against respectively Intel Xeon Platinum 8180 (28 cores/205W TDP), Xeon Gold 6152 (22 cores/140W TDP), and Xeon Silver 4116 (12 cores/85W TDP). Performance per watt was found to be significantly better for the Qualcomm chip when using SPECint_rate2006 benchmark.
The most important metrics for server SoCs are performance per thread, performance per watt, and performance per dollars, so Qualcomm pitted Centriq 2460, 2452 and 2434 against respectively Intel Xeon Platinum 8180 (28 cores/205W TDP), Xeon Gold 6152 (22 cores/140W TDP), and Xeon Silver 4116 (12 cores/85W TDP). Performance per watt was found to be significantly better for the Qualcomm chip when using SPECint_rate2006 benchmark.
 Performance per dollars of the Qualcomm SoCs look excellent too, but…
Performance per dollars of the Qualcomm SoCs look excellent too, but…
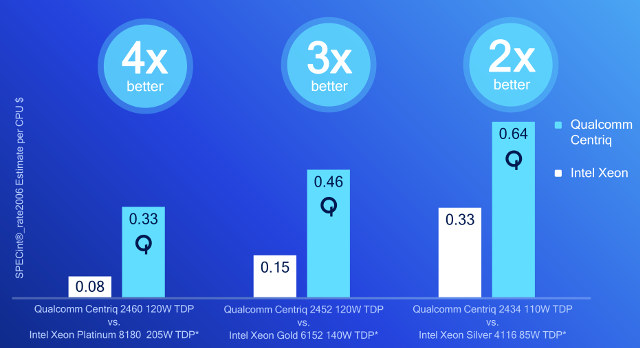
Qualcomm took Xeon SoCs pricing from Intel’s ARK, and in the past prices there did not reflect the real selling price of the chip, at least for low power Apollo Lake / Cherry Trail processors.
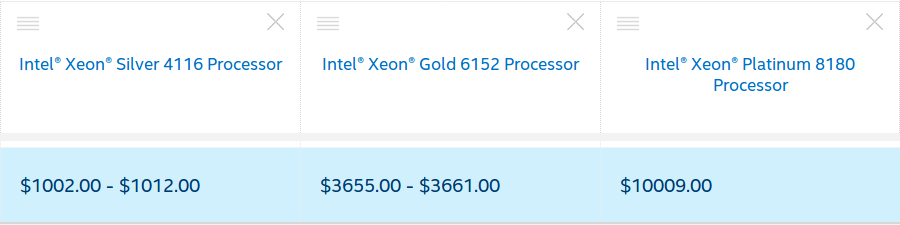 This compares to the prices for Centriq 2434 ($880), Centriq 2452 ($1,373), and Centriq 2460 ($1,995).
This compares to the prices for Centriq 2434 ($880), Centriq 2452 ($1,373), and Centriq 2460 ($1,995).
Qualcomm also boasted better performance per mm2, and typical power consumption of Centriq 2460 under load of around 60W, well below the 120W TDP. Idle power consumption is around 8 watts using C1 mode, and under 4 Watts when all idle states are enabled.
If you are wary of company provided benchmarks, Cloudflare independently tested Qualcomm Centriq and Intel Skylake/Broadwell servers using Openssl speed, compression algorithms (gzip, brotli…), Go, NGINX web server, and more.
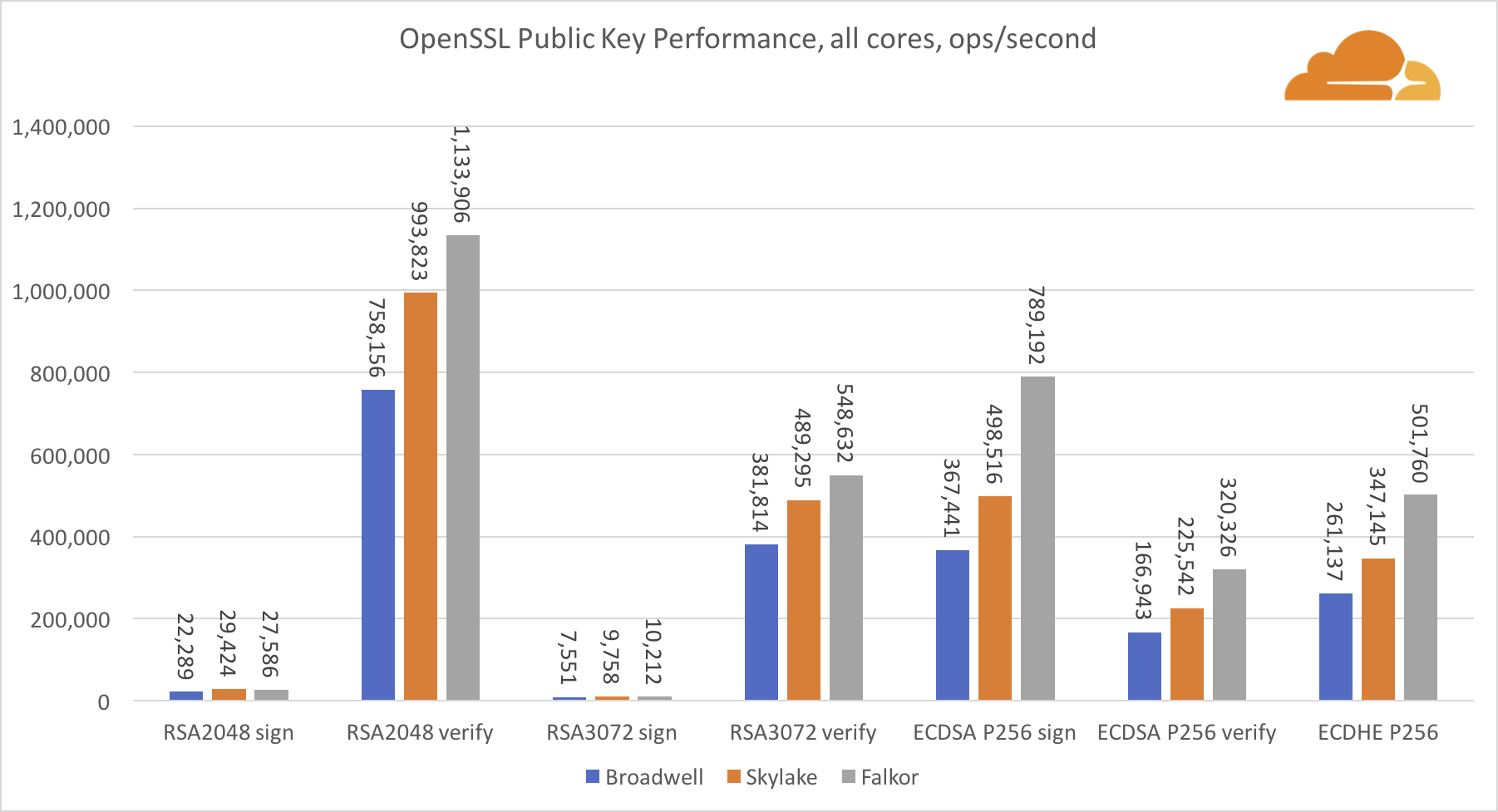
Usually, Intel single core performance is better, but since ARM has more cores, multi-threaded performance is often better on ARM. Here’s their conclusion:
The engineering sample of Falkor we got certainly impressed me a lot. This is a huge step up from any previous attempt at ARM based servers. Certainly core for core, the Intel Skylake is far superior, but when you look at the system level the performance becomes very attractive.
The production version of the Centriq SoC will feature up to 48 Falkor cores, running at a frequency of up to 2.6GHz, for a potential additional 8% better performance.
Obviously the Skylake server we tested is not the flagship Platinum unit that has 28 cores, but those 28 cores come both with a big price and over 200W TDP, whereas we are interested in improving our bang for buck metric, and performance per watt.
Currently my main concern is weak Go language performance, but that is bound to improve quickly once ARM based servers start gaining some market share.
Both C and LuaJIT performance is very competitive, and in many cases outperforms the Skylake contender. In almost every benchmark Falkor shows itself as a worthy upgrade from Broadwell.
The largest win by far for Falkor is the low power consumption. Although it has a TDP of 120W, during my tests it never went above 89W (for the go benchmark). In comparison Skylake and Broadwell both went over 160W, while the TDP of the two CPUs is 170W.
Back to software support, the SoC is supported by a large ecosystem with technologies such as memcached, MongoDB, MySQL, …, cloud management solutions such as Openstack and Kubernetes, programming languages (Java, Python, PHP, Node, Golang…), tools (GVV/ LLVM, GBD…), virtualization solution including KVM, Xen and Docker, as well as operating systems like Ubuntu, Redhat, Suse, and Centos.
Qualcomm is already working on its next generation SoC: Firetail based on Qualcomm Saphira core. But no details were provided yet.
Thanks to David for the links.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.


Performance per watt is where ARM have been excelling so far, so nothig extraordinary here. As long as the single-thread performance is good enough ™, many server workloads care more about throughput.
If Qualcomm can make a board with this chip, 1 dimm per channel, 4 x4 NVMe slots, and 2 x8 PCIe slots, they’ll have my money.
Just give me minimal firmware and a serial port, and no extraneous bullshit.
@noone
Seconded. I want something in this space, even if it seems “pricey” in comparison to the embedded stuff we’re normally used to.
What an amazing read Cloudfare’s benchmark test is. Kudos to Vlad Krasnov! Very very well done pointing out what the numbers mean, why they are as they are and how they could/will improve.
@tkaiser
They have a follow up article about Intel performance only. The CPU cores are clocked lower when some crypto instructions (e.g. AVX-512) are used, so they may actually impact the system performance negatively (depending on your load).
https://blog.cloudflare.com/on-the-dangers-of-intels-frequency-scaling/
@cnxsoft
That’s a well-known phenomenon on Intel cores since AVX2 and AVX512 only exacerbated things. If your code has predominantly SIMD portions then you win from the SIMD throughput gains. But:
1) on recent AVX architectures core clocks are dropped when AVX is encountered — recent intels just cannot run AVX at their stock clocks.
2) on AVX512 the SIMD engines are kept dormant, so upon encountering AVX512 code the SIMD engines are first fired up, and then clocks are dropped.
So it’s perfectly possible to have code where the throughput gain from limited use of AVX/AVX512 is insufficient to offset the increased latencies from the need to fire up engines first (the smaller detriment) and to downclock entire pipelines (the larger detriment), so you end up with deceleration from using AVX/AVX512.
@blu
Do ARM processors exhibit the same behavior for some SIMD instructions, or is it specific to x86?
@cnxsoft
Not on any of the ARMs I’ve encountered, but we shall see how things develop with the new SVE (scalable vector extension), where vectors can go as wide as 2048 bits. On Intel it started with AVX2 on Haswell, though it’s not necessarily linked to AVX2 per se, as much as to AVX256 workloads and Intel’s push for ever higher clocks. Basically, very high clocks or very wide throughput — you cannot have both; the ever-lasting dilemma of latency vs throughput.
@blu
It’s not the dilemma of latency vs. throughput, it’s the dilemma of the thermal envelope.
@slackstick
The dilemma (an imposed choice between two or more alternatives) is latency vs throughput; what brought to it in this case was beyond my point (yes, it’s usually thermal envelope and product costs).
How do they meet the cooling needs on these at present?
@theguyuk
Under-clocking for the most part.
@blu
You get both latency and throughput 10 times over per watt with DSPs. Won’t be long before someone figures out how to get it done for general compute.
They are working on improving Go crypto performance on arm64 based on disappointing benchmark results reported by Cloudflare:
Source: https://www.worksonarm.com/blog/woa-issue-30/