
Dimitris Tassopoulos (Dimtass) decided to learn more about machine learning for embedded systems now that the technology is more mature, and wrote a series of five posts documenting his experience with low-end hardware such as STM32 Bluepill board, Arduino UNO, or ESP8266-12E module starting with simple NN examples, before moving to TensorFlow Lite for microcontrollers.
Dimitris recently followed up his latest “stupid project” (that’s the name of his blog, not being demeaning here :)) by running and benchmarking TensorFlow Lite for microcontrollers on various Linux SBC.
But why? you might ask. Dimitris tried to build tflite C++ API designed for Linux, but found it was hard to build, and no pre-built binary are available except for x86_64. He had no such issues with tflite-micro API, even though it’s really meant for baremetal MCU platforms.
Let’s get straight to the results which also include a Ryzen platform, probably a laptop, for reference:
| SBC | Average for 1000 runs (ms) |
| Ryzen 2700X (this is not SBC) | 2.19 |
| AML-S905X-CC | 15.54 |
| Raspberry Pi 3 B+ | 13.47 |
| Jetson nano | 9.34 |
| NanoPi Duo | 36.76 |
| NanoPi Neo | 16 |
| NanoPi NEO2 | 22.83 |
| NanoPi NEO4 | 5.82 |
| NanoPi K1 Plus | 14.32 |
| Orange Pi Prime | 18.40 |
| Beaglebone Black | 97.03 |
| STM32F746 @ 216MHz | 76.75 |
| STM32F746 @ 288 MHz | 57.95 |
And in chart form.
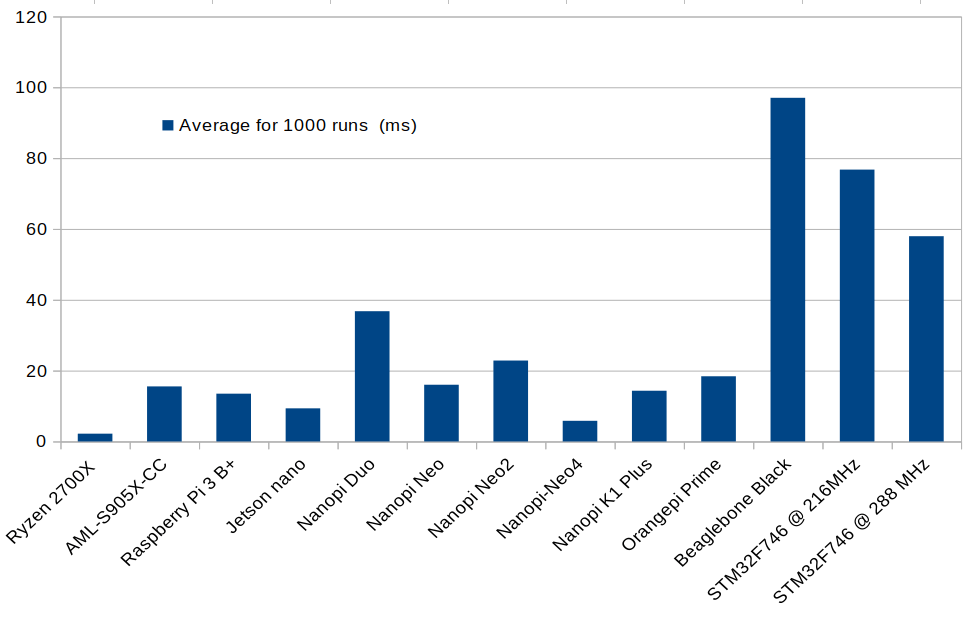
The Ryzen 2700X processor is the fastest, but Rockchip RK3399 CPU found in NanoPi NEO4 is only 2.6 times slower, and outperforms all other Arm SBCs, including Jetson Nano. Not bad for a $50 board. Allwinner H3 based NanoPi Neo board also deserves a mention as at $10, it offers the best performance/price ratio for those test.
If you want to try it on your own board or computer, you can do so as follows:
|
1 2 3 4 5 |
sudo apt install cmake g++ git clone https://dimtass@bitbucket.org/dimtass/tflite-micro-python-comparison.git cd tflite-micro-python-comparison/ ./build.sh ./build-aarch64/src/aarch64-mnist-tflite-micro |
Note that’s for Aarch64 (Arm 64-bit targets), the last command line will be different for other architectures, for example on Cortex-A7 based SoC, the program will be named “mnist-tflite-micro-armv7l” instead.
Note that while tflite-micro is easy to port to any SBCs, there are some drawbacks over using tflite C++ API. Notably tflite-micro does not support multi-threading, and it’s much slower than tflite C++ API.
| CPU | tflite-micro/tflite speed ratio |
| Ryzen 2700X | 10.63x |
| Jetson nano (5W) | 9.46x |
| Jetson nano (MAXN) | 3.86x |
The model is also embedded in the executable instead of being loading from a file, unless you implement your own parse. You’ll find a more detailed analysis and explanation on Dimtass’ blog post.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



Hmm, tflite-micro supports GPUs now? I thought it didn’t.
It doesn’t support any kind of acceleration other than whatever compiler flags you use. It’s explained in the post.
Doh, I’ve mentally switched the tflite c++ and tflite-micro sections, my bad.
I just did a quick test on a Pi 4 with 4GB RAM and got average time of 8.39ms which is quite a bit faster than the Pi 3.
Have you used any cooling to prevent throttling?
Yes, a Pimoroni Fan Shim.
Then this is definitely the inference average time on the rpi4. Good to know, thanks!
The article says “BBB is a single core running @ 1GHz and the code is running on top of Linux. So the OS has a huge impact in performance, compared to baremetal”. My understanding of what the code does is that it mostly performs MAC operations so the OS is totally irrelevant here, with 100% of the time spent in userland. A more likely explanation is that in order to perform these operations a lot of RAM is needed and possibly that the BBB’s memory latency is very high on this one. Or the code relies on something that the… Read more »
Mem latencies is definitely one possible explanation — most of these tensor ops require decent locality to perform well, which for large-footprint kernels is achieved via prefetching, which is inherently a tuned operation — optimal prefetching for a given mem setup might not be optimal for another, etc.
BTW, depending on compiler built-in flags, -mfloat-abi=hard -mfpu=neon might be required to make good use of the neon in CA8.
Regarding the compiler flags, afaik gcc is set by default to auto when those flags are not set. Therefore, since the code is not cross-compiled, but it uses the OS toolchain, the flags should be the proper ones. Of course, if the toolchain is not built with the proper flags then this could be a problem. I’ve tested on the nanopi neo to build with the proper architecture flags according this (https://gcc.gnu.org/onlinedocs/gcc-4.7.2/gcc/Optimize-Options.html#Optimize-Options) and I’ve seen the same performance. Therefore, I guess gcc selects the proper flags when in auto.
This is the point of the TVM optimizer. For example the loops being run maybe be exceeding CPU D-cache size on the BBB. What TVM does is split the loops into two equivalent loops half the size and then tests running those. It does this process over 1000s of alternatives searching for the optimal configuration. For any given model the optimal run time arrangement varies quite a bit depending on the target hardware.
There is also a good chance a quantized int model will outperform float on the BBB. The BBB does not have a lot of float power.
With that I meant that the OS because of the scheduler that switches the CPU to also different tasks, has greater impact on a single core CPU. Of course there are other factors, but I think in the BBB case this has the greater impact.
But in practice you don’t have to switch to something else since your code is single-threaded, so in the worst case the CPU is interrupted 100 times a second for 1 microsecond each time, which is not even noticeable.
The only way to find out and to be sure is to build the same benchmark as a baremetal for the cpu. This was also my question and I’ve mention it somewhere in the end. I’ll probably try to do this at some point to verify this.
>possibly that the BBB’s memory latency is very high on this one.
From what I remember the bus fabric in the TI SoCs is a bit weird. There’s at least one hack (not sure if it enabled for the AM335x’s though) that flushes all of the in-flight memory operations to make barriers work properly.
Maybe cache write-back was disabled in favor of write-through.
It would be interesting to get a process like TVM optimization running on these devices. https://tvm.ai/2018/10/03/auto-opt-all TVM works by reordering the instructions in the model in a bunch of different ways, and then chooses the fastest. TVM does not change what the model is doing, it is a micro optimizer for the TF API. I used it on the Allwinner V5 (not using the dedicated AI hardware) and it was able to triple my performance. The main thing it did was pick strides the right size to not fall out of the cache. I suspect you would see a lot… Read more »
Hi jon, this seems interesting. I guess this acts on the tflite model only, so it doesn’t matter if the model the is loaded in any of the available Tensorflow APIs (tflite or tflite-micro), right? I mean I don’t have to use the tflite python bindings only to use this. I’m asking because it wasn’t clear for me from the link.
It only alters the models. There are thousands of equivalent ways to arrange the API calls inside the models. TVM does a search pattern through all of those combinations looking for the best one. When targeting ARM CPUs I get anywhere from 50% to 300% speed up by running TVM. You’ll find that the optimal model varies for every CPU core and DRAM configuration. It will even vary on same CPU with DDR3 vs DDR4. It does not vary as much on x86 since most x86 chips are very similar. TVM is commercially available as Amazon Sagemaker. Python is not… Read more »
Thanks for the info Jon! I will have a look at it. It seems like a tool for production code as it needs quite some time and effort to set this up properly. Nevertheless, I’ll try at least to make an example with it and test it and see its performance on the specific tflite model.
I had that demo running in half an hour. All you need is a working Python on the target.
You should be able to run this demo are all of your larger ARM boards. It will let you get a feel for how much impact optimizing has.
https://docs.tvm.ai/tutorials/autotvm/tune_relay_mobile_gpu.html
It is Amazon SageMaker Neo, not the generic Sagemaker.
Google just announced these new, low footprint models.
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet/edgetpu
I suspect they will run quite well on small hardware. On these small CPUs the quantized models (integer) usually outperform the float versions. Sometimes float wins but I have only observed that to happen on a quad-core CPU with NEON. NEON is SIMD so it can do multiple float ops in parallel.
Which is why it’s such a shame to read in the blog posts that loading quantized models is broken/unimplemented in tflite-micro.
I’ve actually opened a ticket for the performance issues, but I haven’t got any response yet. I guess, that they are pretty busy right now with porting more Ops and it’s also still an early development release. I’m sure that most of the issues will be resolved at some point.
https://github.com/tensorflow/tensorflow/issues/30953
@dimtass: Your 5-part series of blog posts about running tflite-micro (and the comparison to STM’s x-cube-ai) on microcontrollers was great to read! I had read Pete Warden’s blog posts leading up to and then announcing tflite-micro, and had read through some of the documentation but haven’t really dived into tflite-micro yet, so I learned a ton reading through your evaluation of it. If you’re looking for even more stupid project feature-creep, maybe you should get a hold of one of the Kendryte K210 boards (e.g. MAIX-bit) and try out its (tiny) NPU-acclerated API. That would let you include all of… Read more »
Thanks John! I’ll definitely have a look to your proposals. There are so many releases and new things that are coming out for embedded and ML, which is really very hard to follow everything. It’s just raining ML. I’ve also seen that the support uint8 quantization, which was my problem with TF-lite. I can’t quantize the model with uint8, the converter output int8. I don’t know if I’m doing something wrong or it’s an issue with tflite. I’ve read tons of posts and I could make it work. It’s still a mystery. Therefore, I guess that nncase will have the… Read more »
Hmm… from what I’ve seen, the nncase is targeting specifically image classification NNs. I don’t know if it can be used outside of this scope. I’ll dig deeper though.
I wonder how RK1808 and A311D SBCs would fare in this comparison…
Since only a single thread on a single CPU core is used in those tests and not any other accelerator, then both should be near the RK3399. For testing the neural network accelerators it would be a different benchmark, but most difficult to do as not every SoC support the same tools and some time those tools are difficult to build for each SoC.
I posted my numbers on dimtass’s project page, all running Debian or Raspbian with some aarch64 kernel:
Google Coral Dev Board: 12.404573 ms
Rock Pi 4B: 6.333575 ms
Raspberry Pi 4 Model B: 8.358435 ms
I’m very curious about Khadas VIM3, but I don’t have that board
why rockpi4 is slower than the nanopi neo4? They should be using the same rk3399 cpu, right? Just curious…
I believe that has to do with the CPU frequency. The armbian distro and also the Yocto distro that I’m maintaining overclock the RK3399 a bit by default. Other distros are using the stock frequencies, which are just a bit lower.
sir, I’m a student working on real time object detection on beaglbone black for a project. For tht, i need to install or build tflite from source, can u please guide me on how to install tensorflow lite on beaglebone black