
The first Windows 10 Arm Mobile PCs were announced a few months ago, all based on Qualcomm Snapdragon 835 processor, with products such as HP Envy x2 (2017) and ASUS NovaGo TP370.
The new products promised LTE connectivity, very long battery price, a user experience similar to the one on Intel/AMD based laptops, and at price points ($600 and up) that should command good performance.
But TechSpot ran some benchmarks on HP Envy x2 (a $1,000 device), and in most cases, the new always-connected PCs come with performance similar or even lower than a Chuwi laptop based on an Intel Celeron N3450 Apollo Lake processor that sells for a little over $400. That appears to be valid for both x86 emulation and native apps.
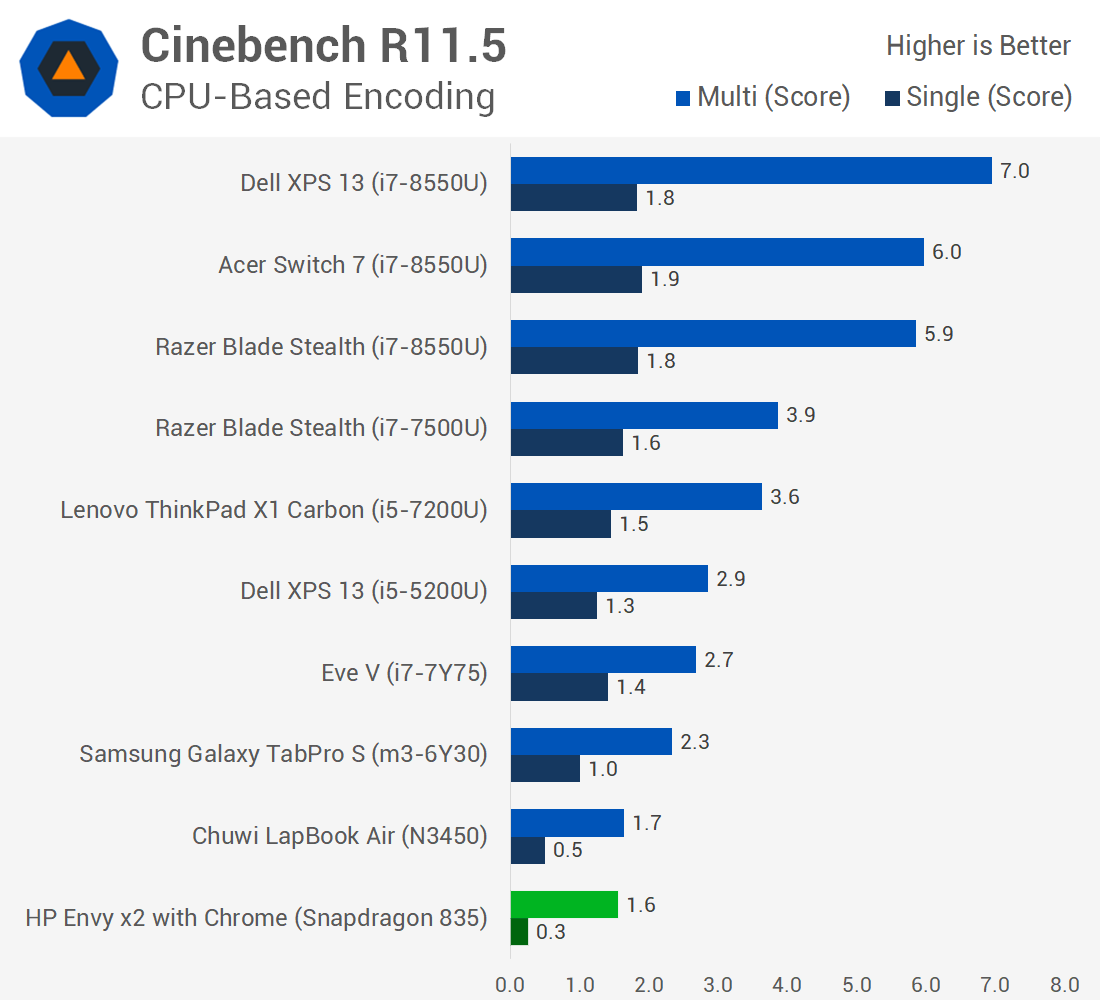
In some case, the Snapdragon laptop does pretty well with performance close to Core m3 / Core i5-5200U processors such as in the Microsoft Excel workload below.
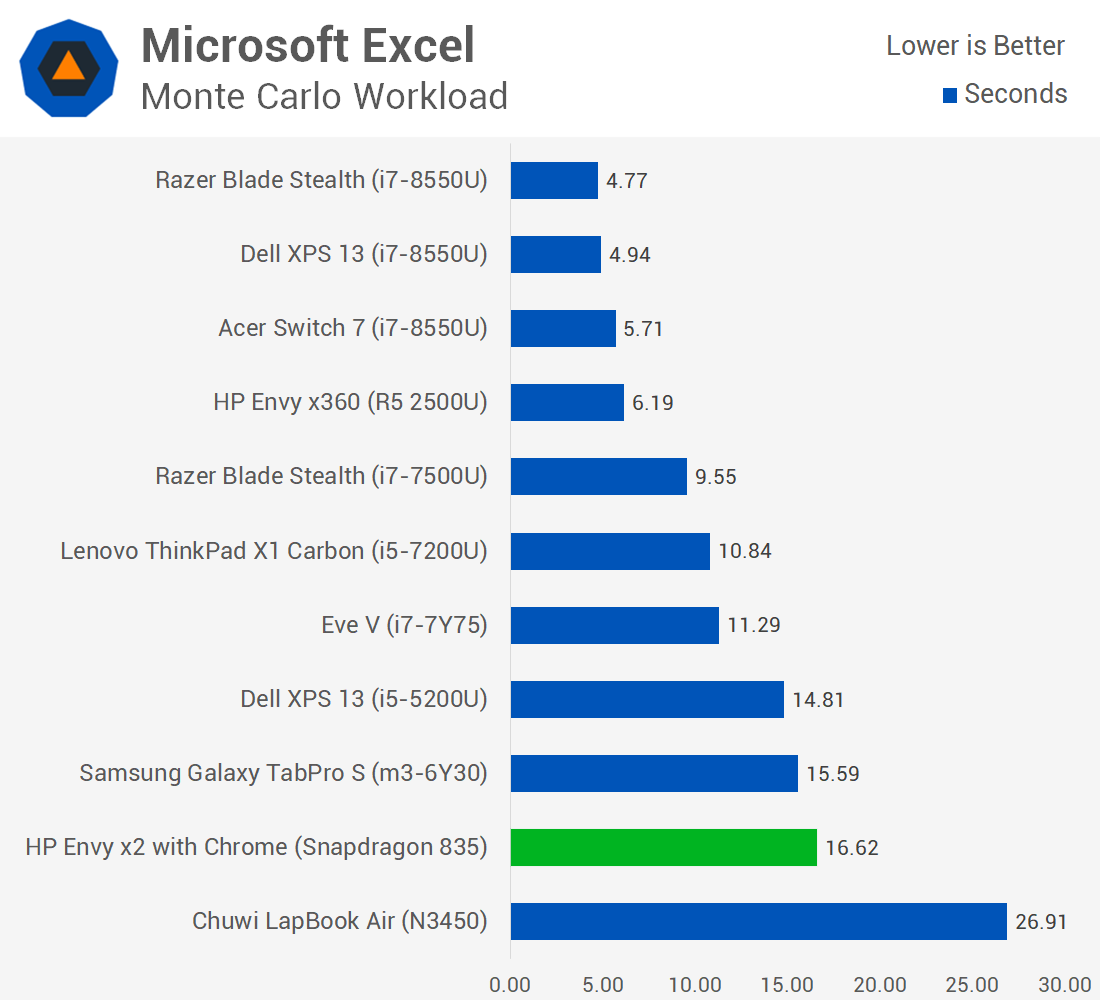
However, you may not want to use Photoshop on Arm until some further software optimizations are performed on the app.
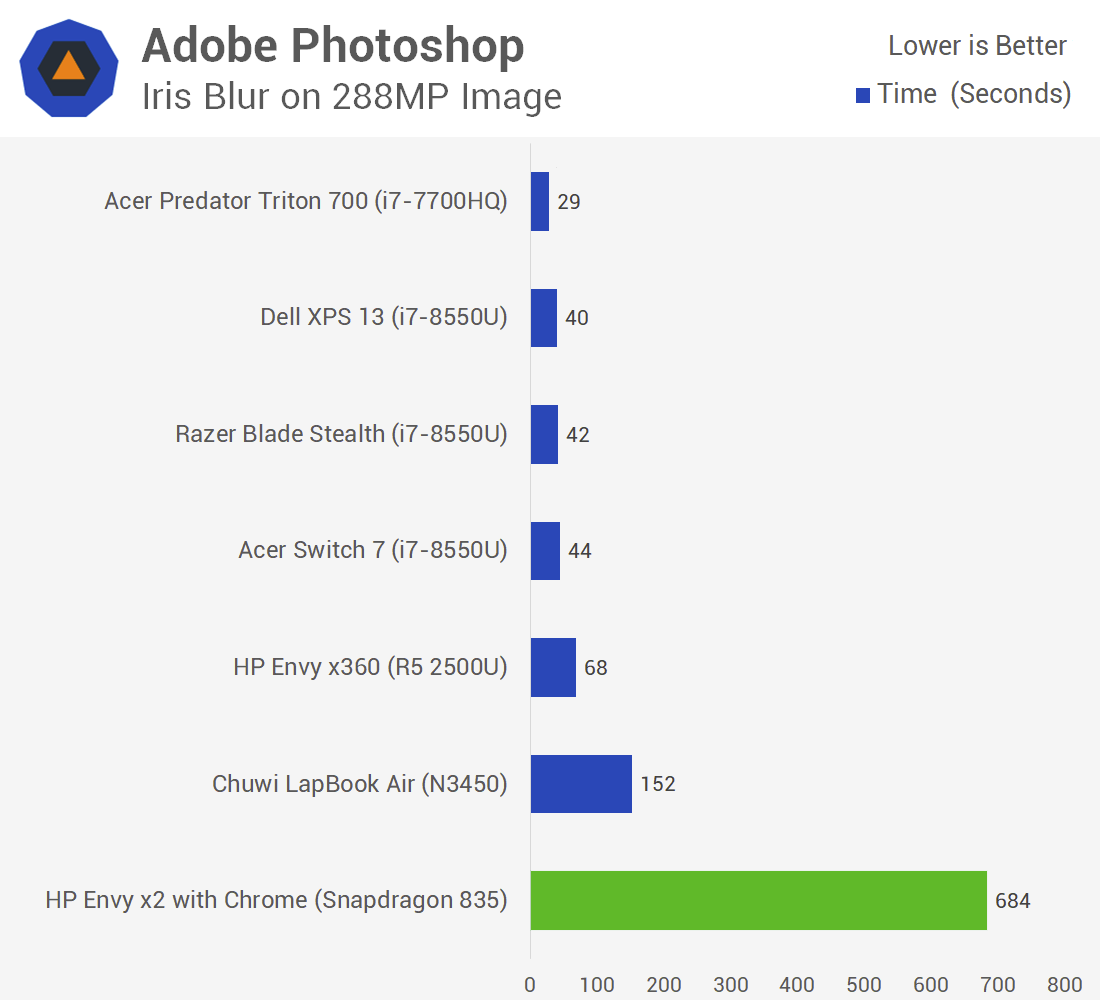
All three benchmarks above are relying on x86 emulation, but native apps fare about the same, for example using Google Octane in Microsoft Edge.
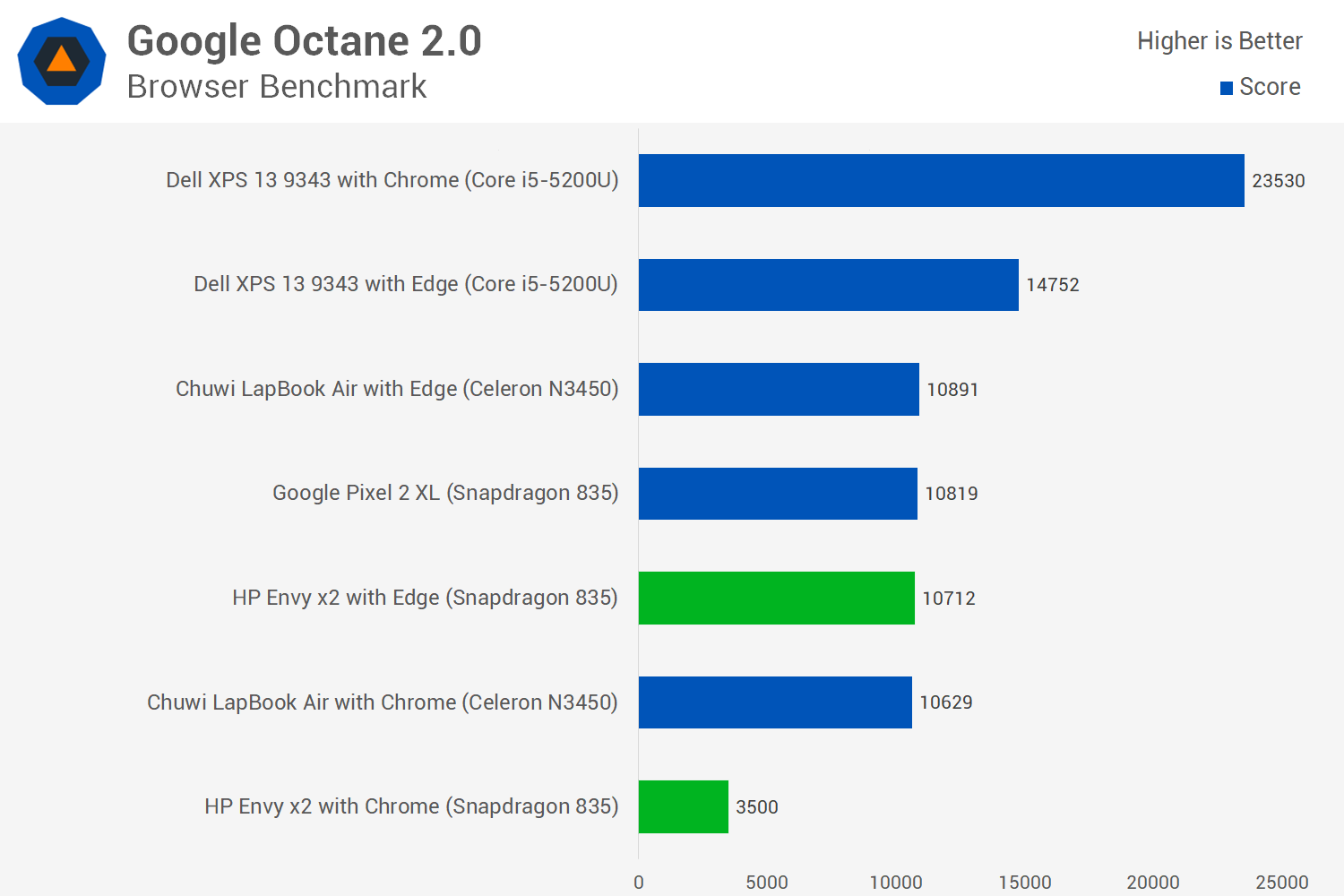
Google Octane 2.0 was also tested with Chrome (x86 emulation) in the chart above, and it shows you may want to stick to Microsoft Edge – at least for now – if you’re ever going to browse the web on an Arm laptop.
However, Arm laptops really shine when it comes to battery life, so that one of the main reasons – together with built-in LTE connectivity – to purchase a Qualcomm Snapdragon powered laptop.
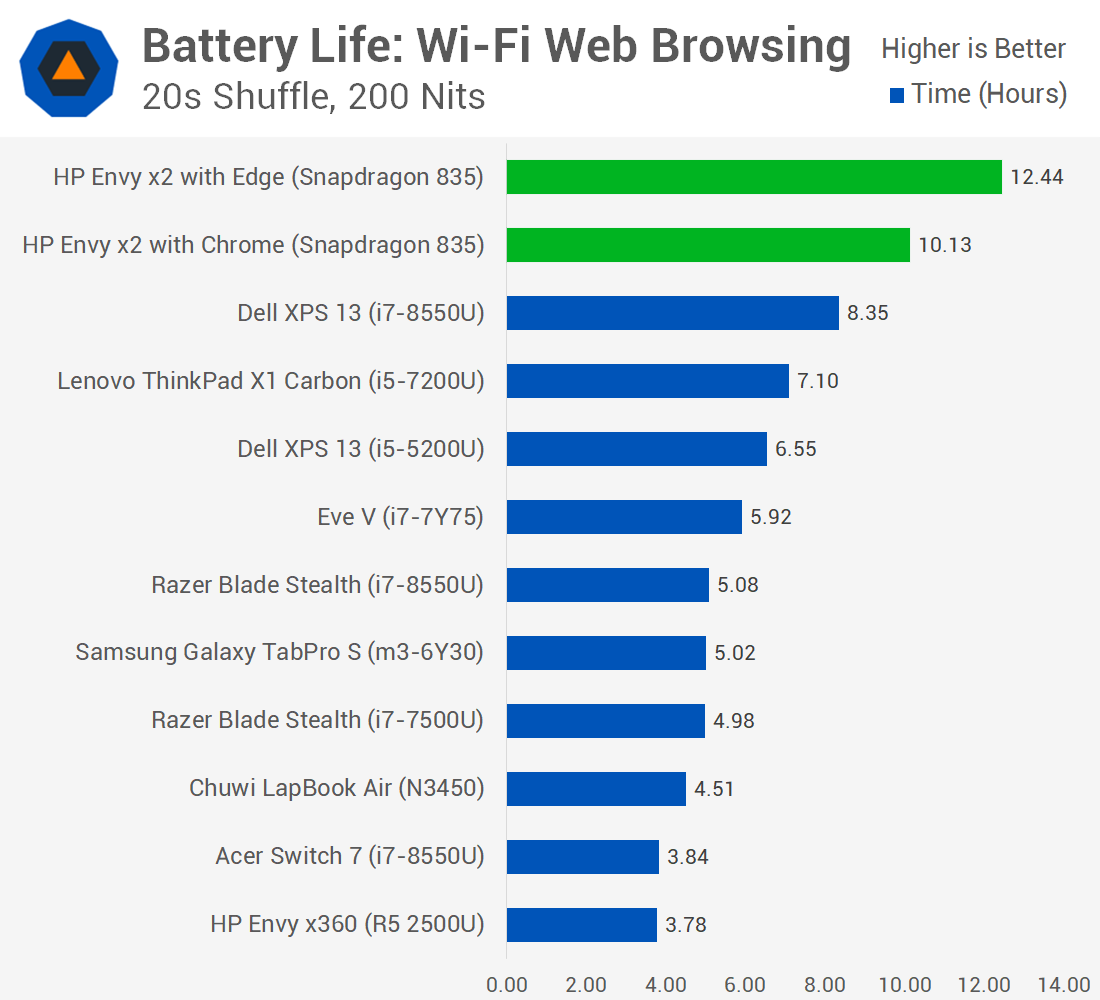
In a WiFi web browsing battery life test, the Snapdragon last close to 13 hours with Microsoft Edge, nearly 3 times longer than Chuwi LapBook Air, and several hours longer than a Dell XPS 13 laptop.
Via Liliputing

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.


I think always-connected ARM notebooks meet their target audience demands (i.e. office productivity at 1.5x-2.x the battery life of the competition) quite well, even in devices’ first iterations. Question is, when will vendors start producing those at more accessible prices? And do they even intend to?
All of this is a nonsense. And it is serious, they don’t seem to give up on this crap anytime soon…
> Performance Similar to Intel Apollo Lake Laptop (in Most Cases)
The original article gives a very different conclusion:
> Being able to run x86 desktop apps is a key ingredient to this new Windows variant. Even ignoring the compatibility issues for a moment, x86 performance on ARM chips is terrible, which puts the whole platform into question at least in this early iteration.
The statements are different, but not incompatible:
1. The performance is similar to that of a quad core Apollo Lake processor (in most cases). True, just look at the many benchmark on Techsport.
2. The performance is terrible. A judgment call, but also true considering the price. For $1,000, you can get a Core i7 system, and comparable Apollo Lake laptops cost between $300 and $500.
From the Techspot article:
> When the Snapdragon fails to get even close to a measly Atom-based Celeron processor in a number of workloads, you’re not going to get a good real world experience. When you use the device with a desktop app like Excel or Photoshop, it’s easy to get frustrated by how sluggish, laggy and unimpressive the performance is. Using a Celeron N3450 is tough when you’re used to Core i5 or i7 performance, and the Snapdragon 835 is significantly worse than this.
Whereas above:
> and in most cases, […] performance similar or even lower than a Chuwi laptop based on an Intel Celeron N3450 Apollo Lake processor […] valid for both x86 emulation and native apps.
I expect the SD835 to be better than the Atom natively, but it should be much worse than the Atom when running x86 code.
> When you use the device with a desktop app like Excel or Photoshop, it’s easy to get frustrated by how sluggish, laggy and unimpressive the performance is
If this sentence is based on someone working with the device in question and performing real-world tasks (e.g. retouching something in Photoshop and not running a stupid pseudo benchmark like applying a blur filter to a 288MP (!) file) then it’s an interesting conclusion. If the above is only based on those horribly irrelevant BS benchmarks then it’s simply laughable.
Take 2 PCs, one with OS on a HDD, the other with a modern SSD (preferably not SATA bottlenecked but NVMe already). The PC with the HDD has a much faster CPU and more RAM and will outperform the other PC in all of those stupid pseudo benchmarks easily. The SSD equipped ‘loser’ though will be the machine you will work with more productive in reality. Since all the ‘benchmarking’ focuses on irrelevant stuff only.
Have you looked through this funny set of ‘benchmarks’ that were used to ‘measure’ the binary translation performance?
Video encoding as use case on such a thing? Seriously? 2 Photoshop ‘benchmarks’ using each filters that are amongst those maybe 15 operations in Photoshop that are OpenCL accelerated (so of course x86 currently wins here but just due to OpenCL acceleration not yet available on ARM). WinRAR and 7-zip? Is this what you do the whole day long?
An Excel benchmark? Seriously? With a human being in front of the machine Excell will be idling 99% of the time since waiting for the operator. And everything that’s performance relevant is related to UI stuff that most probably performs as smoothly as on x86.
IMO that’s just another great example for BS benchmarking (measuring something totally irrelevant and afterwards drawing the wrong conclusions).
The photoshop benchmark was really something, I agree. One has to wonder how often the reviewers use their personal notebooks to do photoshop workloads..
And in general, I don’t think x86 emu on those machines was intended for ‘here’s my desktop number cruncher app, let’s move it over to this notebook!’ scenarios. It’s for using your office productivity apps that don’t come in ARM format yet, and that includes text processing, communications, browsing.
These new machines do those tasks competently (minus non-native browsers like chrome — we can expect those natively-compiled sooner than later), at a much longer battery lifespan. As advertised.
> One has to wonder how often the reviewers use their personal notebooks to do photoshop workloads..
Why should they care? It requires a lot of time and efforts to correctly benchmark something. With such a device you would’ve to check use cases first and then try to choose those benchmarks that reflect reality to be able to compare performance of x86 vs. such an ARM thing here.
But why? If you’re a tech publication (or something like Phoronix) your readers don’t care anyway. They’re fine with irrelevant numbers as long as they’re graphed nicely. Running such irrelevant synthetic benchmarks in ‘fire and forget’ mode is also way less expensive than doing it correctly.
These Photoshop benchmarks are pure BS. 288 megapixel in RGB with only 8-bit color depth result already in an uncompressed data size of ~700 MB. Work with 16-bit color depth and it’s twice as much, add some layers or transparency and record 10 undo steps and you’re already swapping every machine to death that has less than 16 GB DRAM.
The only reason such BS benchmarks are fired up is since it’s easy for the tester. Whether the task has any relevance for ‘doing work in Photoshop’ or the ‘benchmark’ is just generating numbers without meaning… who cares?
Yeah, benchmarks are BS because computers are idle 99% of the time. Most users would be happy with a Pentium II for their office work.
> Video encoding as use case on such a thing? Seriously?
Oh come on, never heard of the millions of people using any sort of video chatting software? Yeah, the video actually needs to get encoded before it can get streamed over the internet.
But yes, I may very well want to encode a video on such a device. Why can’t I?
> OpenCL acceleration not yet available on ARM
I take the point, but that also just points out another downside.
> An Excel benchmark? Seriously?
You clearly haven’t seen how “serious users” can use Excel (ever seen how well a 16MB XLSX file performs? I’m not kidding, I get those at work (related to financial modelling of fairly complex operations)).
A benchmark is there to show performance. Whether the performance matters to you or not is another matter altogether.
Don’t confuse video trans-coding (a software process) with video encoding for live streams (a largely hw process).
“Transcoding” is just a fancy term for decode -> encode. There’s nothing explicit in either which prohibits use of hardware acceleration or a pure software process. What’s important is whether the software can utilise the provided hardware acceleration or not.
Presumably, emulated x86 would have limited hardware access, so any video dealing application which is emulated probably cannot use hardware encode/decode at all.
One also needs to consider that hardware implementations are often quite limited compared to software implementations, so if the hardware can’t do what needs to be done for the application, only software can be used.
> emulated x86
?
I know nothing about Windows application development (*nix and macOS guy) but I can’t imagine that those programs do not use interfaces/frameworks that are designed to use the best engine available. And that’s QuickSync on Intel laptops or Snapdragon’s video engine on these ARM thingies (of course not doing any video processing on CPU cores at all and especially not emulated since plain stupid).
There might be some use cases for CPU based video encoding (e.g. higher quality and/or lower sizes when using x264 instead of CPU’s video engines) but how should this be important for the use case of these ARM laptops? The stuff that matters (playing video or encoding video chats) will be done highly energy efficient on the SoC’s video engine. Natively of course and not harming the CPU cores anyway.
Someone made a benchmark using three times the wrong approach to encode video (on the CPU). So what? How should users of these laptops be affected by ‘benchmarking gone wrong’?
> There’s nothing explicit in either which prohibits use of hardware acceleration or a pure software process.
Yes, there is. Hardware encoders/decoders are limited to a small set of encoding schemes and bitrates. Software transcoders, OTOH, usually handle a great deal of encoding schemes and bitrates. So most of the time transcoding is performed in software for the lack of matching hw compatibility.
> transcoding is performed in software for the lack of matching hw compatibility
Actually, it’s likely because hardware encoders are typically junk in terms of the output they generate.
Most hardware encoders these days can encode H.264, which is very widely supported. If quality of output isn’t a concern, you very much can transcode using hardware accelerated encoders.
> Actually, it’s likely because hardware encoders are typically junk in terms of the output they generate.
Which is another way to say ‘transcoding is performed in software for the lack of matching hw compatibility’, no? Here, http://slhck.info/video/2017/03/01/rate-control.html
> the video actually needs to get encoded before it can get streamed over the internet.
Sure, there’s a video engine in those SoCs that does the job. On Intel it’s QuickSync, no idea how the technology is called with Snapdragons. Both (!) video encoding benchmarks use encoders that run on the CPU instead. Why? It’s 100% irrelevant for all average use cases on such a laptop thingy.
AFAIK Handbrake can make use of QuickSync when available. So you get with native execution on a x86 machine the stuff offloaded on a dedicated video engine in the Intel CPU while on the Snapdragon x86 code runs in binary translation mode. Comparing Apples and Oranges. And I would assume still 100% irrelevant since stuff like video encoding will be done by Windows offloaded to Snapdragon’s video engine (that’s one of the reasons why such SoCs show great battery life: offloading everything possible to special engines contained in the SoC)
People love to compare numbers. People prefer data over information. That’s the sole reason such stupid ‘passive benchmarking’ orgies only producing numbers without meaning happen all the time.
I now noticed one benchmark dissonance (multi-threaded result way to high compared to single-threaded) and am wondering what could’ve caused this.
The WinRAR benchmark shows single and multi threaded results.
* The top performing Intel machines with i7-8550U (4 cores, 8 threads) show multi-threaded numbers that are up to 6.5 times better as single-threaded (as expected)
* The four thread Intel machines show up to 3.2 times multi-threaded performance (as expected)
* The Snapdragon using an octa-core big.LITTLE implementation shows 10 times the multi-threaded performance compared to single-threaded (2145 KB/s vs. 213 KB/s)
How’s that possible? It’s an octa-core design with 4 faster cores (2.45 GHz) and 4 slower cores (1.9 GHz). So either when running the benchmark single-threaded the scheduler threw the task on a slow core (very unlikely and even then the numbers are wrong) or the tester simply did just run every benchmark one single time.
We’re talking here about binary translation. X86 code gets translated to ARM so the first execution is slower and subsequent executions run then with optimized code (a lot) faster. If we assume the code got executed on one of the fast cores first and scored with 213 KB/s then a sensible expectation for a multi-threaded result when running on all 8 big.LITTLE cores should be around 6 times faster (1300 KB/s). But it’s ten times faster so chances are great that this benchmark just shows how the binary translation with subsequent executions of the same code got better and reduced execution times?
Or is there another explanation?
That is definitely a plausible explanation. A bigLITTLE should not exhibit this behavior in plausible workloads.
With binary translation, benchmarking even is more useless than mostly without. I have software, when executed via qemu, execution time just is not deterministic. It can change by more than a factor of 10, depending on something unknown code obviously gets translated or not. I don’t think binary translation caches code between runs.
Of course results are cached: https://docs.microsoft.com/en-us/windows/uwp/porting/apps-on-arm-x86-emulation
Windows 10 on ARM does reference off of core 0 which is a little core as discussed in this video at 14:20.
https://youtu.be/VeOQp5V7EgM?t=860
Those are not necessarily connected, though. Task manager reporting a clock off a LITTLE core is one thing, task scheduler not scheduling tasks giving priority to the big cores would be a *major* problem — I don’t think MS would dare ship their product with such a problem.
The video is worth a look though since in the following minutes it can be clearly seen that browsing the web is no issue at all.
On the other hand those ‘benchmarks’ done by the TechSpot guy claim ‘Chrome performance is terrible on the Envy x2 compared to Edge’. And what is he using for this claim? Another totally irrelevant benchmark called Google Octane 2.0 that is a JavaScript engine and not a web browser benchmark!
Here the developers of this benchmark explain why still using it for anything is simply wrong: https://v8project.blogspot.de/2017/04/retiring-octane.html (the TL;DR: version is: since developers optimized only for BS benchmarking real-world performance of JavaScript engines even declined)