
When we interviewed Toradex right before Embedded World 2019, they told us they would focus on their new software offering called Torizon, an easy-to-use industrial Linux Platform, especially targeting customers are coming from the Windows / WinCE environment or who have only experience with application development and are not embedded Linux specialists.
The company has now officially launched Torizon, and provided more details about their industrial open source software solution especially optimized for their NXP i.MX modules.
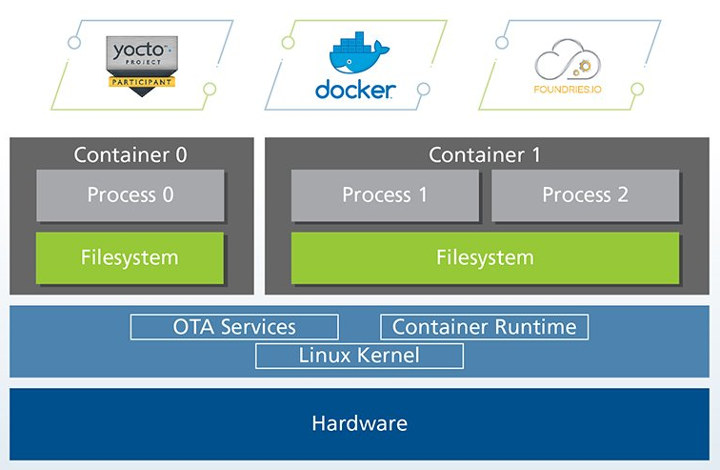 Torizon specifically relies on foundries.io Linux microPlatform which provides full system with a recent stable kernel, a minimal base system built with OpenEmbedded/Yocto, and a runtime to deploy applications and services in Docker containers. The microPlatform is part of TorizonCore (light blue section above) that also includes an OTA client (Aktualizr). TorizonCore is free open-source software, and serves as the base to run software containers.
Torizon specifically relies on foundries.io Linux microPlatform which provides full system with a recent stable kernel, a minimal base system built with OpenEmbedded/Yocto, and a runtime to deploy applications and services in Docker containers. The microPlatform is part of TorizonCore (light blue section above) that also includes an OTA client (Aktualizr). TorizonCore is free open-source software, and serves as the base to run software containers.
To get started, Torizon provides a Debian container including apt package manager that allows developers to easily download and try a large number of deb packages. Toradex will also provide a development tools for pin configuration, display settings, performance monitoring and more, with both local and web-based remote UIs.
One of the tools that should help Windows developers is the Torizon Microsoft Developer Environment that integrates with Visual Studio, making Linux application development and debugging more intuitive for Windows developers. .Net support is also available in Torizon, the company is working on a tighter integration, and is giving away 2x 30 support hours (that must be 60 hours…) to qualified developers moving Windows or Windows CE application to Torizon.
More details can be found in the product page, as well as on Github where you can access the source code and a getting started guide. Note that Torizon is still considered beta software.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



This seems like cramming as much cool tech into the wrong place as possible. If you are doing OTA updates to a piece of industrial hardware managing hundreds of megabytes of docker images is going to turn the whole thing into a shit show.
(disclaimer: I work for Toradex, but please try to read my answer in an objective way, because I think it contains some valuable technical details) 1. the docker runtime is optional, you can have OTA updates with a Yocto/OE built single image solution. This has still some advantages compared to A/B image approach (less storage, you can have multiple versions on the device, not just last two) and updates are transactional (you reboot to the new image or to the old one, not to something in between). 2. being an old and old-school embedded developer I can understand your concern… Read more »
>This has still some advantages compared to A/B image approach It’s not really clear what you’re saying has advantages to be honest. Anyhow there are numerous advantages to having fixed images i.e. you can sign the whole image and know that the image you are booting is valid and hasn’t been tampered with, you can validate the disk blocks as they are read so you know they haven’t been tempered with while the system is running, the whole thing can be read only,.. >If you look a bit better into that topic you will discover that: >– container images are… Read more »
I appreciated the discussion and thank you for the effort you put in replying, I am not a native English speaker, so if some of my replies may not be easy to understand or may sound rude or too ironic, please blame my poor knowledge of the language and not bad attitude. I like having a discussion with people with different views. As I said, the plan is not to solve any issue or apply to each and every scenario, but I think that this solution has some advantages that you may have to consider when designing an embedded system… Read more »
>I am not a native English speaker, so if some of my >replies may not be easy to understand Your replies are fine. I didn’t get the context linking the two statements. I don’t use English on a daily basis anymore so potentially the issue was on this side. >I like having a discussion with people with different views. Same. >Part of the industry moved from firmware to embedded OSs in the 90s, >and still have lots of firmware-based solution working perfectly From my personal perspective: There are hundreds of thousands of devices running something I wrote. The real world… Read more »
> From my personal perspective: There are hundreds of thousands of devices running something I > wrote. The real world consequences of that stuff breaking actually worries me. Same thing here. I started working on devices in 1999, both as freelance and employee, and I am still worried that my first customer calls me for an issue 🙂 But on the other side happy to see products I’ve been helping developing used at my local supermarket and lots of other places. > If I had to advocate for anything it would be to ban microcontrollers for anything that involves >… Read more »
Torizon now supports OTA firmware update (Alpha release): https://labs.toradex.com/projects/torizon-over-the-air