
AI inference used to happen exclusively in powerful servers hosted in the cloud, but in recent years great efforts have been made to move inference at the edge, usually meaning on-device, due to much lower latency, and improved privacy.
On-device inference works, but obviously, performance is limited, and on battery-operated devices, one also has to consider power consumption. So for some applications, it makes sense to have a local server with much more processing power than devices, and lower latency than the cloud. That’s exactly the use case SolidRun Janux GS31 Edge AI inference server is trying to target using several NXP processors combined with up to 128 Gyrfalcon Lightspeeur SPR2803 AI accelerators
 Janux GS31 server specifications:
Janux GS31 server specifications:
- CPU Module – CEx7 LX2160A COM Express module with
- NXP LX2160A 16-core Arm Cortex A72 processor @ 2.0 GHz
- System Memory – Up to 64GB DDR4 RAM via 2x SO-DIMM sockets
- “Video” Processors – Up to 32x NXP i.MX 8M Cortex-A53 SoC with 2D/3D GPUs, hardware video decoder support 1080p60;
- AI Accelerators – Up to 128 Gyrfalcon Lightspeeur SPR2803 AI accelerators delivering up to 2150 TFLOPS (2.15 petaFLOPS) @ 300MHz
- Video Decoding – Up to 128x 1080p60 streams
- Networking – 2x 10GbE SFP+, 1 x Gigabit Ethernet (RJ45)
- USB – 2x USB Type-A ports, 1x micro USB port
- Misc – PWM outputs for 8x cooling fans
- Power Supply
- Input – 100V~240V via IEC60320 connector
- Consumption – Max 900W (single-phase), or ~7 Watts per stream
- Dimensions – 445 x 500 x 43.5mm (1U rack)
- Temperature Range – Operating: 10°C to 35°C; storage: -40°C to -60°C
- Humidity – Operating: 20% to 80% relative, non-condensing; storage: 20% to 93% relative, non-condensing
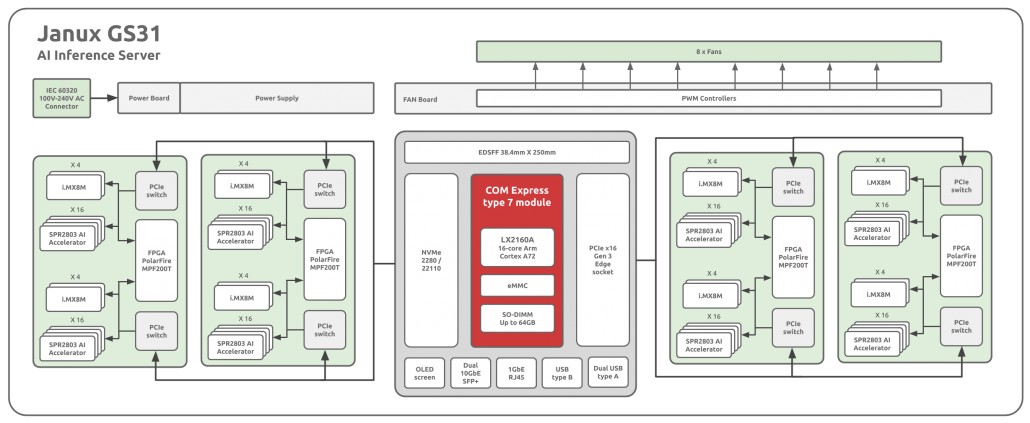
If we look at the block diagram above, we can see the server includes up to four “Snowball” modules, each with eight NXP i.MX8M processors, 32 Gyrfalcon AI accelerator and one PolarFire MPF200T FPGA connected over a PCIe switch.
The server runs Linux, supports TensorFlow, Caffe and PyTorch frameworks, as well as VGG, ResNet and MobileNet AI networks. The specifications make it clear the server is designed for real-time inference on multiple video streams, and target applications include monitoring of smart cities & infrastructure, intelligent enterprise/industrial video surveillance, object detection, recognition & classification, smart visual analysis, and more.
SolidRun claims Janux GS31 achieves three times the performance of other devices on the market, for half the cost, half the size, and half the power consumption. But they did not provide any numbers for comparison at this point in time.
The company did not provide availability nor pricing information about the server, but if interested, you can contact them via the product page which has limited information at the time of writing.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress. We also use affiliate links in articles to earn commissions if you make a purchase after clicking on those links.


Solidrun Janux GS31 has just been officially launched, but no public pricing is available.