
Armv8 was announced in October 2011 as the first 64-bit architecture from Arm. while keeping compatibility with 32-bit Armv7 code. Since then we’ve seen plenty of Armv8 cores from the energy-efficient Cortex-A35 to the powerful Cortex-X1 core, as long as some custom cores from Arm partners.
But Arm has now announced the first new architecture in nearly ten years with Armv9 which builds upon Armv8 but adds blocks for artificial intelligence, security, and “specialized compute” which are basically hardware accelerators or instructions optimized for specific tasks.
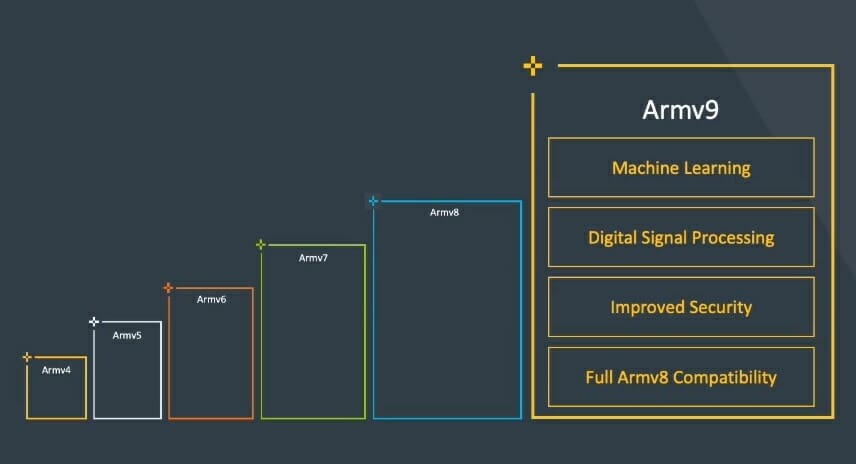
Armv9 still supports Aarch32 and Aarch64 instructions, NEON, Crypto Extensions, Trustzone, etc…, and is more an evolution of Armv8 rather than a completely new architecture.
Some of the new features brought about by Armv9-A include:
- Scalable Vector Extension v2 (SVE2) is a superset of the Armv8-A SVE found in some Arm supercomputer core with the addition of fixed-point arithmetic support, vector length in multiples of 128, up to 2048 bits. Useful for specialized DSP and XR (augmented and virtual reality) workloads, from 5G to genomics to computer vision.
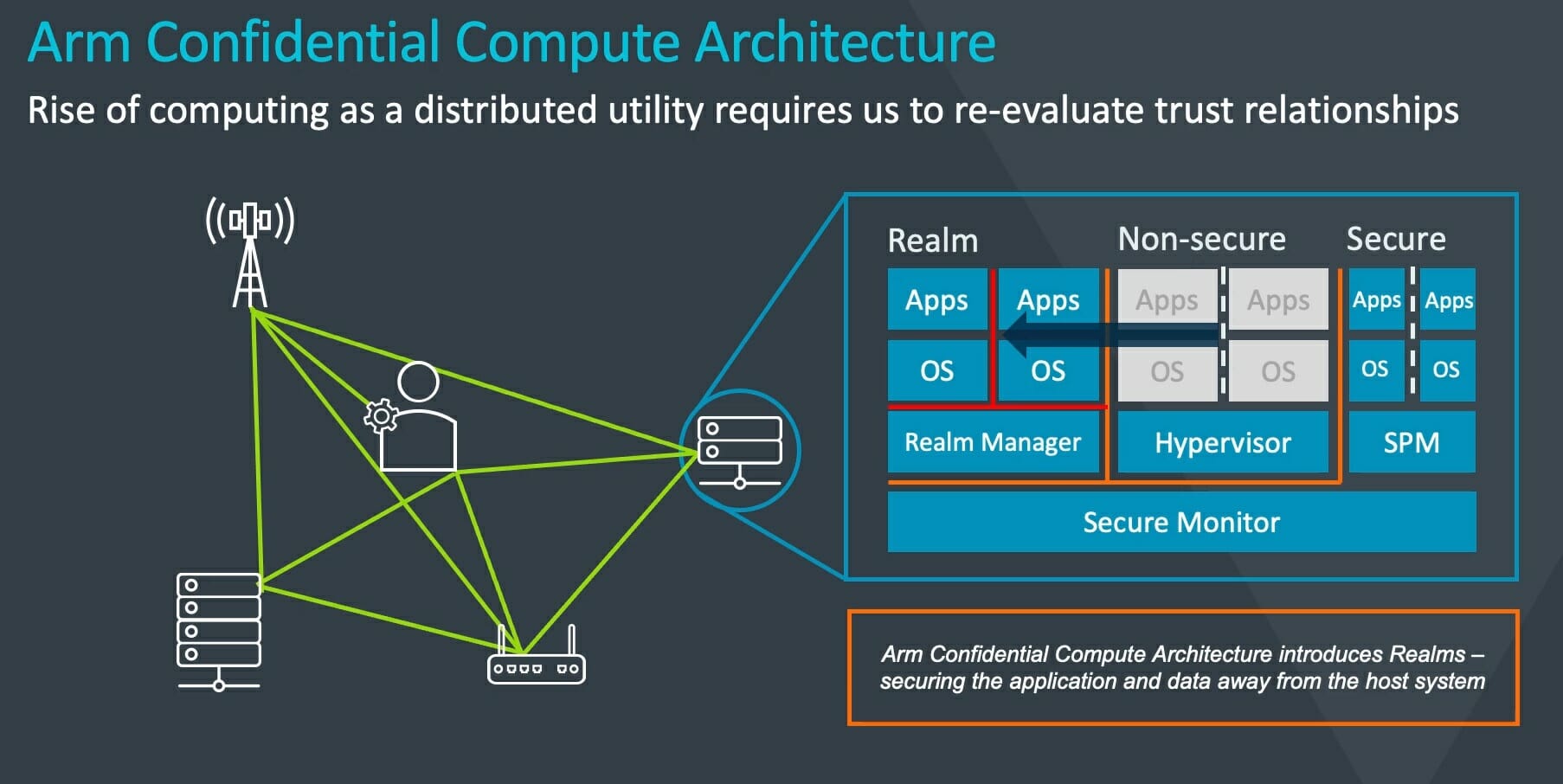
- Arm Confidential Compute Architecture (CCA)
- The Realm Management Extension (RME) establishes a new hardware-backed secure environment that extends Confidential Compute on Arm platforms to all developers and all workloads. Typical use case: a public cloud that processes sensitive or valuable data.
- Arm Confidential Compute Firmware Architecture – A standard platform software framework for the Arm Confidential Compute Architecture that simplifies hardware design and encourages reuse and portability. Typical use case: protection of sensitive personal healthcare data on mobile devices.
- Tracing & Debugging
- Branch Record Buffer Extensions (BRBE) providing profiling information, such as hot-spot analysis and Auto FDO, for debugging/optimization. To be implemented in Armv9.2-A scheduled for release in Q3/Q4 2021
- Embedded Trace Extension (ETE) and Trace Buffer Extension (TRBE) for improved trace capabilities for Armv9
- The Transactional Memory Extension (TME) brings Hardware Transactional Memory (HTM) support to the Arm architecture to address the difficulty of writing highly concurrent, multi-threaded programs in which the amount of coarse-grain, thread-level parallelism can scale better with the number of CPUs, by reducing serialization due to lock contention.
The CPU performance of Armv9 SoC is expected to increase by more than 30% over the next two generations of mobile and infrastructure CPUs, but Arm highlights Total Compute design principles where SoC will be optimized for specific tasks.
A few more details can be found in the press release and Total Compute page, but for technical details, I’d recommend checking out the A-profile and security features pages from Arm’s developer website. The “Arm Vision” section of the website also has some more details including a video by Arm SVP, Chief Architect and Fellow, Richard Grisenthwaite, that gives a more practical overview of Armv9 and use cases made possible with the new features. All the screenshot above comes with this video as well.

Jean-Luc started CNX Software in 2010 as a part-time endeavor, before quitting his job as a software engineering manager, and starting to write daily news, and reviews full time later in 2011.
Support CNX Software! Donate via cryptocurrencies, become a Patron on Patreon, or purchase goods on Amazon or Aliexpress



It doesn’t look to me like it’s as much of a gap since v8 as v8 was to v7. I’m more seeing it as a way to put a .0 after a new version while standardizing all the stuff that accumulated in v8.x for large values of x. I’m still missing the aarch64 equivalent of thumb2 though. Thumb2 code is significantly faster on machines with small caches, up to 20% on my compile farms, it’s really sad that they never produced any such thing, because for me *this* was a significant architectural improvement, and I was secretly hoping that Thumb3… Read more »
It’s not necessarily code size alone: it’s also pointer sizes. For the latter, there’s ILP32 but I’m not sure that its use is widespread (or even if a Linux distro exists that supports it in an official release).
Here its not just pointer size because compiling in 32-bits with -marm instead of -mthumb2 results in the exact same lower performance as running in 64-bit. However as a side effect I do continue to run them in 32-bits to benefit from thumb2, and this results in using smaller pointers, which is an additional nice saver of course!
probably the tradeoff larger caches vs. additional transistors for “thumb3” is’t as great as it was for thumb2. (or arm is so dominant on mobile that there is just no incentive for such an easy optimization)
and yeah they wanted a new baseline build target (v9) that includes all the 8.x improvements. currently basically everyone still just builds for 8.0…
Related article ARM’S V9 ARCHITECTURE EXPLAINS WHY NVIDIA NEEDS TO BUY IT” https://www.nextplatform.com/2021/03/30/arms-v9-architecture-explains-why-nvidia-needs-to-buy-it/
A bit long, but a nice few quotes, among which:
“In the Armv9 decade, partners will create a future enabled by Arm AI with more ML on device,” Davies explained. “With over eight billion voice assistive devices. We need speech recognition on sub-$1 microcontrollers. Processing everything on server just doesn’t work, physically or financially.”
Bold statement!